
As of March 21, 2023, QODA is now CUDA Quantum. For up-to-date information, see the CUDA Quantum page.
Quantum algorithm researchers in government, enterprise, and academia are interested in developing and benchmarking novel quantum algorithms on ever-larger quantum systems. Use cases include drug discovery, cybersecurity, high energy physics, and risk modeling.
However, these systems are still small, quality still needs to improve, and capacity on them is limited. Developing applications and algorithms on quantum circuit simulators is therefore common.
NVIDIA cuQuantum is a software development kit (SDK) that enables users to easily accelerate and scale quantum circuit simulations with GPUs. A natural tool for calculating state vectors, it enables users to simulate quantum circuits deeper (more gates) and wider (more qubits) than they could on today’s quantum computers.
cuQuantum includes the recently released NVIDIA cuQuantum Appliance, a deployment-ready software container with multi-GPU, multi-node state vector simulation support. Generalized multi-GPU APIs are also now available in NVIDIA cuStateVec for easy integration into any simulator.
For tensor network simulation, the slicing API provided by the cuQuantum cuTensorNet library enables accelerated tensor network contractions distributed across multiple GPUs or multiple nodes. An additional higher-level API is also now available to make this easier for multi-node, enabling users to take advantage of NVIDIA A100 systems with nearly linear strong scaling.
This post takes a deep dive into multi-node state vector simulation with the NVIDIA cuQuantum Appliance. For related information, see Achieving Supercomputing-Scale Quantum Circuit Simulation with the NVIDIA cuQuantum Appliance.
Capabilities of cuQuantum Appliance on the ABCI 2.0 supercomputer
NVIDIA participated in the AI Bridging Cloud Infrastructure (ABCI) grand challenge this past year to benchmark multi-node cuQuantum Appliance capabilities with their system configurations. ABCI is a supercomputer hosted by Japan’s National Institute of Advanced Industrial Science and Technology (AIST).
ABCI 2.0 is ranked at 22 on the TOP500 list as of November 2022, executing the High Performance Linpack (HPL) benchmark with 22.21 petaflops per second. The supercomputer is ranked 32 on the Green500 list with 21.89 gigaflops per watt as of November 2022.
The ABCI system consists of 1,088 compute nodes, with 4,352 NVIDIA V100 GPUs, (dubbed “Compute Node (V)”), and 120 compute nodes with 960 A100 GPUs (dubbed “Compute Node (A)”). The NVIDIA cuQuantum team worked with the NVIDIA Ampere architecture nodes to test a range of circuits, in addition to solution accuracy for a range of precisions.
The ABCI Compute Node (A) GPU systems are NVIDIA A100 40 GB, 8 GPUs per node, with the third-generation NVLink. They have a theoretical peak of 19.3 petaflops, and a theoretical peak memory bandwidth of 1,555 GB/s. Nodes are connected with InfiniBand HDR.
Quantum computing performance benchmarks on the ABCI Compute Node (A)
Three commonly used algorithms, which are relevant for applications research and quantum computer benchmarking, were run.
These three benchmarks leverage the multi-node cuQuantum Appliance: Quantum Volume, the Quantum Approximate Optimization Algorithm (QAOA), and Quantum Phase Estimation (QPE). The Quantum Volume Circuit ran with a depth of 10 and a depth of 30. QAOA is a common algorithm used to solve combinatorial optimization problems like routing and resource optimization on relatively, near-term quantum computers.
NVIDIA ran QAOA with p=1. QPE is a key subroutine in many fault-tolerant quantum algorithms with a wide range of applications, including Shor’s Algorithm for factoring and a range of chemistry calculations like molecular simulations. Weak scaling was demonstrated for all three common quantum algorithms (Figures 1 and 2).
In addition, strong scaling was examined with quantum volume (Figures 3 and 4). The cuQuantum Appliance has effectively turned the ABCI Compute Node (A) into a perfect 40-41 qubit quantum computer. It is clear that scaling to a supercomputer like ABCI’s is valuable for both accelerating time-to-solution and extending the phase space researchers can explore with state vector quantum circuit simulation techniques.
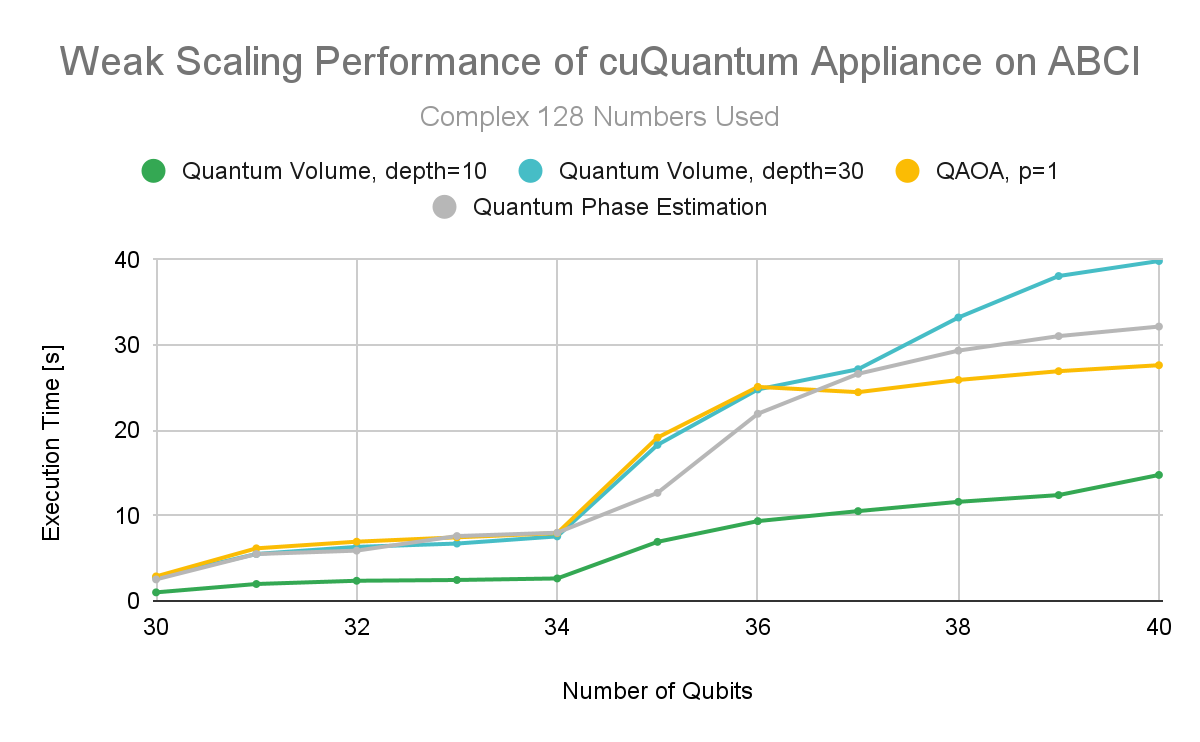
One of the test objectives was to compare the difference between complex 128 (c128) and complex 64 (c64) implementations. When reducing precision, results showed that more memory can be used for an additional qubit. However, it is important to confirm that the reduced precision is not achieved at the cost of producing useful results from the simulations. This experiment used Quantum Phase Estimation to calculate the number pi, which was measured to 16 digits and matched.
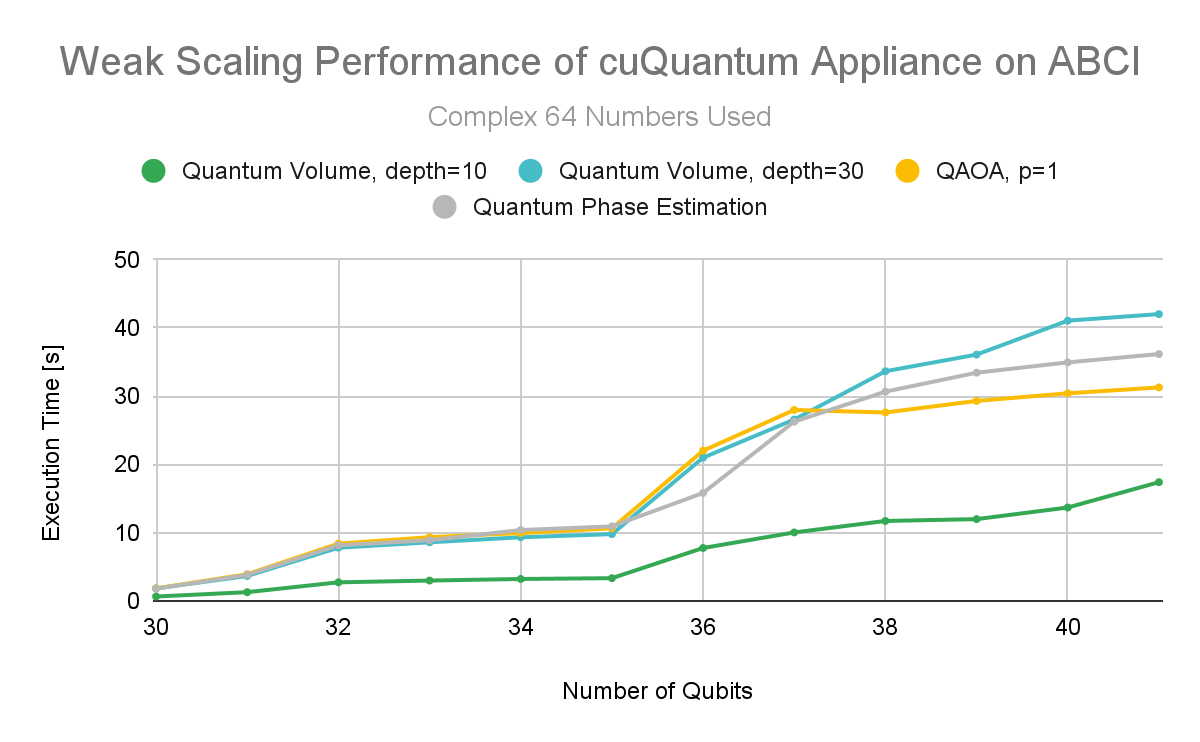
Test results show excellent weak scaling performance for lower precision as well. cuQuantum Appliance users can expect to take advantage of lower precision with confidence that both performance and accuracy are minimally impacted.
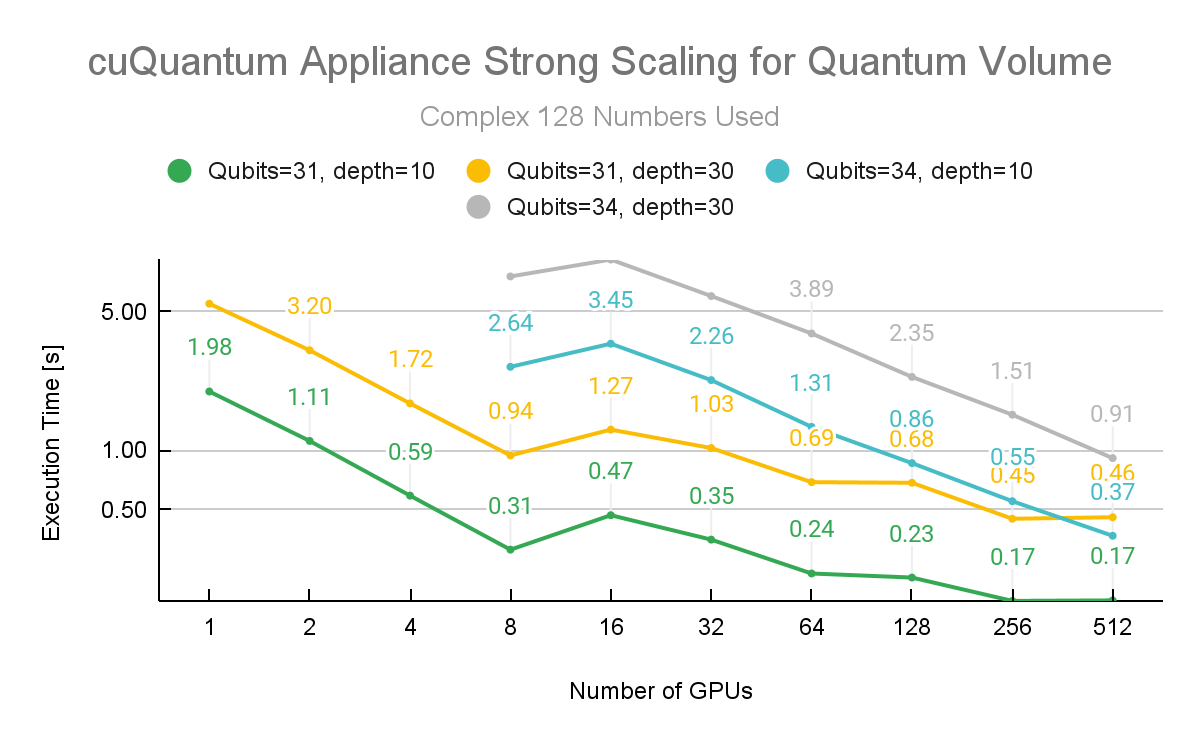
Additional measurements were made to test the strong scaling of the cuQuantum Appliance multi-node capabilities. These numbers were generated with the Quantum Volume Circuit of depth 10 and depth 30. Both of these results are measured for 31 and 34 qubit Quantum Volume.
Figure 3 shows the performance metrics when using incremental amounts of GPUs with complex 128 precision. It is clear that scaling to multiple nodes results in time savings for a range of problem sizes.
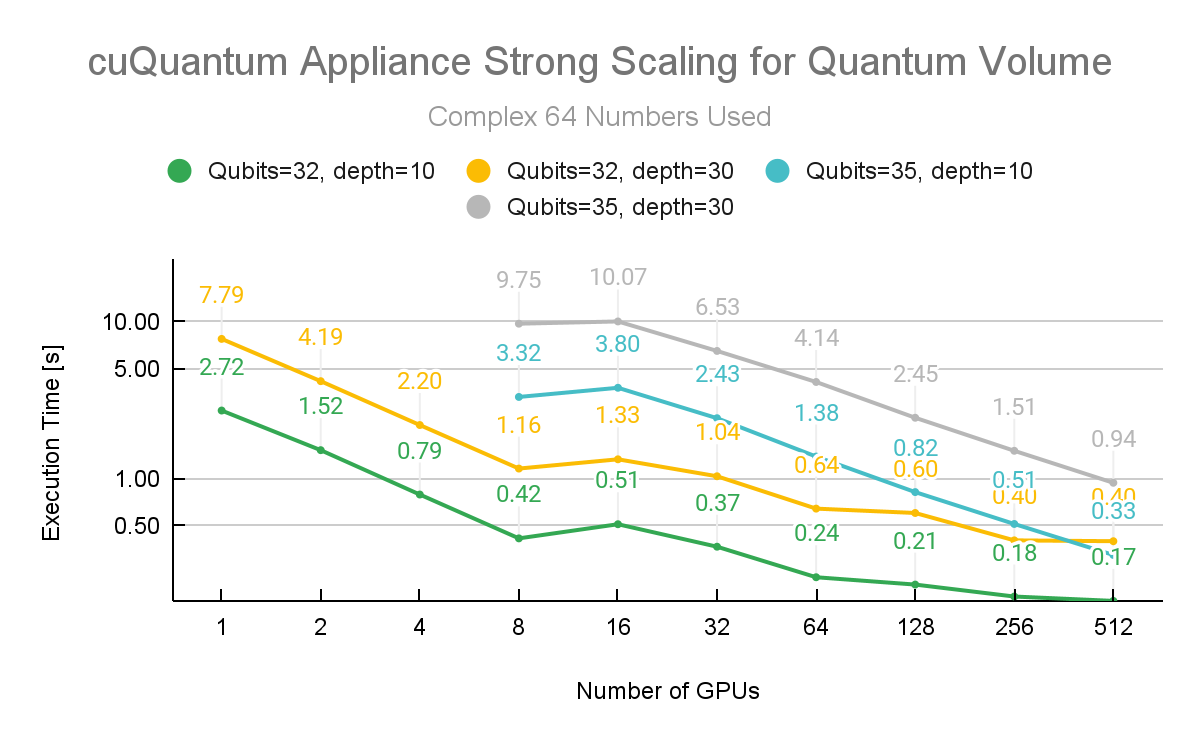
The NVIDIA cuQuantum team conducted additional experiments varying the precision as depicted in Figure 4. This figure shows Quantum Volume running again at depth 10 and depth 30. In this instance, the simulation was held to 32 and 35 qubits and distributed across 512 NVIDIA A100 40GB GPUs on the ABCI Compute Node (A).
The jump in execution time from 8 to 16 GPUs is related to the extra initialization overhead to distribute the workload to two nodes instead of one. This cost is quickly amortized when scaling nodes to an arbitrarily large number.
Comparing cuQuantum Appliance performance
Users are enabled to achieve scale with the updated NVIDIA cuQuantum Appliance. cuQuantum benchmarks were run up to a total of 40 qubits with 64 A100 40 GB nodes. However, users are only limited by the number of accessible GPUs. It is now possible to scale simulations easily, with no changes to existing Qiskit code, and up to 81x faster than the previous implementation without cuQuantum Appliance.
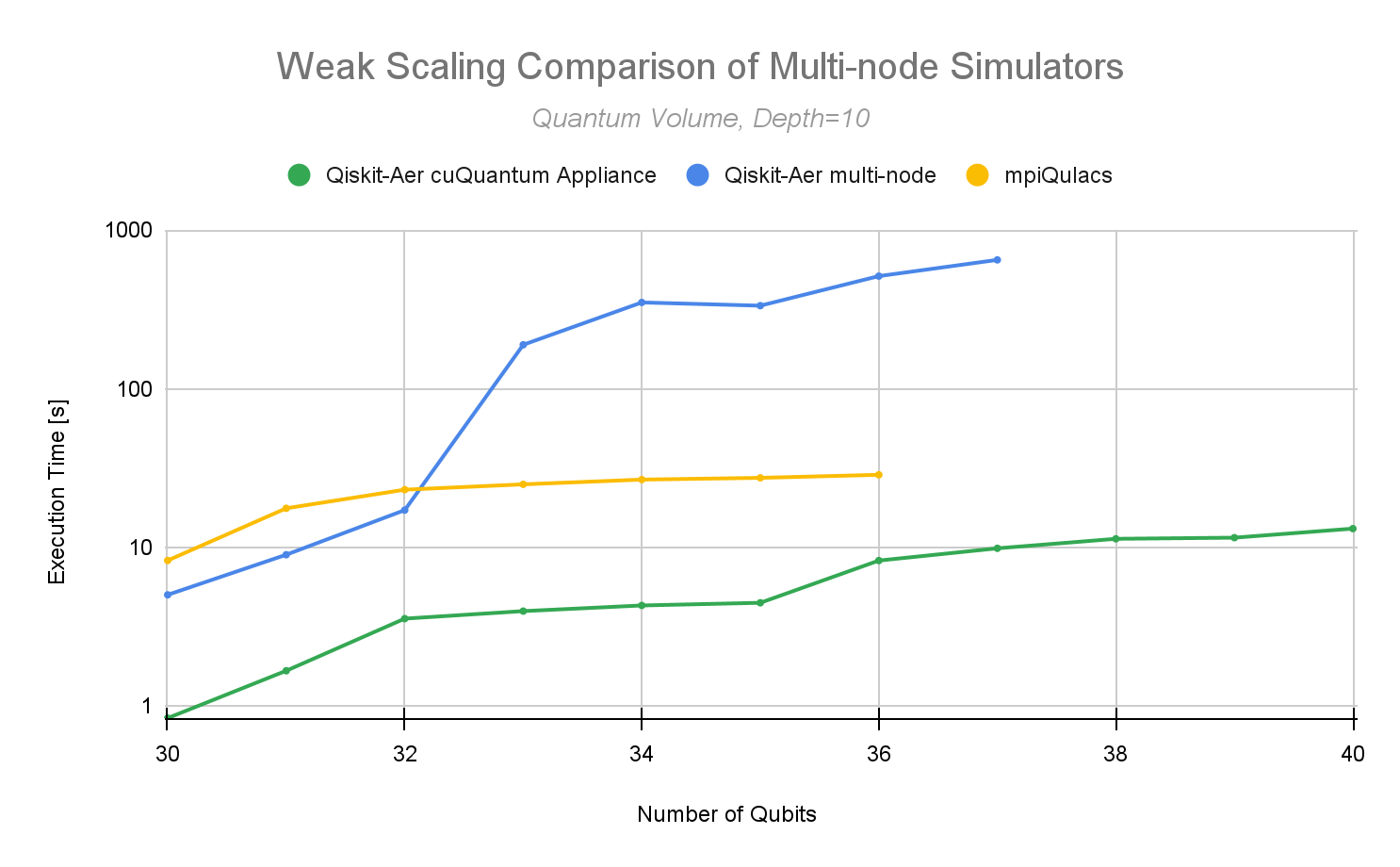
NVIDIA has also benchmarked against a fast, multi-node, full-state vector quantum circuit simulator called mpiQulacs. An impressive simulator, it was developed to run on the Fujitsu A64FX CPU architecture.
In March of 2022, they announced their multi-node simulator’s performance results on a quantum volume depth of 10 with up to 36 qubits. The NVIDIA cuQuantum Appliance now enables users to scale out to 40 qubits with c128, or 41 qubits with c64, on the ABCI 2.0 supercomputer with similar best-in-class performance.
Other preliminary tests on NVIDIA Hopper GPUs have shown that the cuQuantum Appliance multi-node performance numbers will be approximately 2x better than the results presented here, using the new NVIDIA H100 GPUs.
The cuQuantum team at NVIDIA is accelerating state vector simulation at scale. cuQuantum enables scale, and best-in-class performance, showing weak scaling and strong scaling across nodes. In addition, the previously announced results have been validated externally on the AIST ABCI 2.0 supercomputer, showing versatility across different HPC infrastructures.
NVIDIA has also introduced the first cuQuantum-powered IBM Qiskit image. Users are able to pull this container today, making it easier and faster to scale up quantum circuit simulations with this popular framework.
The cuQuantum team has already begun working to bring these multi-node APIs to a wider range of developers and will include these in the next cuQuantum release.
Get started with cuQuantum Appliance
The multi-node cuQuantum Appliance is available today. You can access it directly from the NGC catalog for containers. To request features or to report bugs, reach out to the cuQuantum team at NVIDIA/cuQuantum on GitHub.
Additional resources:
- cuQuantum Documentation
- Lightning Fast Simulations with Pennylane and the NVIDIA cuQuantum SDK
- Orquestra Integration with NVIDIA cuQuantum
- NVIDIA cuQuantum and QODA Adoption Accelerates
- A Deep Dive into the Latest HPC Software
- Defining the Quantum-Accelerated Supercomputer
- Scaling Quantum Circuit Simulations with cuQuantum for Quantum Algorithms
- Quantum Computing Simulation in Pharmaceuticals Research
- Accelerating Quantum Computing Research with GPUs
- AI for Science: Heralding Scientific Breakthroughs through AI
