
Quantum computing aspires to deliver more powerful computation and faster results for certain types of classically intractable problems. Quantum circuit simulation is essential to understanding quantum computation and the development of quantum algorithms. In a quantum circuit, the quantum device is composed of N qubits, and computations are performed by applying a sequence of quantum gates and measurements to the qubits.
Mathematically, the quantum state of the N-qubit system can be described as a complex 2N-dimensional vector. The most intuitive method to simulate a quantum circuit on a classical computer, known as state vector simulation, stores this vector with its 2N complex values directly in memory. The circuit is executed by multiplying the vector by a series of matrices that correspond to the gate sequence that makes up the circuit.
However, as the dimension of the state vector grows exponentially with the number of qubits, the memory requirements for a full description of the state limits this method to circuits with 30–50 qubits. Alternative methods based on tensor networks can simulate significantly more qubits but are generally limited in the depth and complexity of circuits that they can effectively simulate.
The NVIDIA cuQuantum SDK features libraries for state vector and tensor network methods. In this post, we focus on state vector simulation and the cuStateVec library. For more information about the library for tensor network methods, see Scaling Quantum Circuit Simulation with NVIDIA cuTensorNet.
cuStateVec library
The cuStateVec library provides single GPU primitives to accelerate state vector simulations. As the state vector method is fundamental in simulating quantum circuits, most quantum computing frameworks and libraries include their own state vector simulator. To enable easy integration to these existing simulators, cuStateVec provides an API set to cover common use cases:
- Measurement
- Gate application
- Expectation value
- Sampler
- State vector movement
Measurement
A qubit can exist in a superposition of two states, |0> and |1>. When a measurement is performed, one of the values is probabilistically selected and observed, and another value collapses. The cuStateVec measurement API simulates qubit measurement and supports use cases of the measurement on the Z-basis product and batched single-qubit measurements.
Gate application
Quantum circuits have quantum logic gates to modify and prepare quantum states to observe a desirable result. Quantum logic gates are expressed as unitary matrices. The cuStateVec gate application API provides features to apply quantum logic gates for some matrix types, including the following:
- Dense
- Diagonal
- Generalized permutation
- Matrix exponential of Pauli matrices
Expectation value
In quantum mechanics, expectation value is calculated for an operator and a quantum state. For quantum circuits, we also calculate the expectation for given circuit and quantum states. cuStateVec has an API to calculate the expectation value with a small memory footprint.
Sampler
The state vector simulation numerically keeps quantum states in the state vector. By calculating the probability for each state vector element, you can efficiently simulate measurements of multiple qubits for multiple times without collapsing the quantum state. The cuStateVec sampler API executes sampling on GPU with a small memory footprint.
State vector movement
The state vector is placed on a GPU to accelerate simulations by the GPU. To analyze a simulation result on a CPU, copy the resulting state vector to the CPU. cuStateVec provides the accessor API to do this on behalf of users. During the copy, the ordering of state vector elements can be rearranged so that you can reorder qubits into the desired qubit ordering.
For more information, see the cuStateVec documentation.
Google Cirq/qsim and NVIDIA cuStateVec
The first project to announce integration of the NVIDIA cuStateVec Library was Google’s qsim, an optimized simulator for their quantum computing framework, Cirq. The Google Quantum AI team extended qsim with a new cuStateVec-based GPU simulation backend to complement their CPU and CUDA simulator engines.
Build instructions for Cirq and qsim with cuStateVec
To enable cuStateVec through Cirq, compile qsim from the source and install the bindings for Cirq provided by the qsimcirq Python package.
# Prerequisite: # Download cuQuantum Beta2 from https://developer.nvidia.com/cuquantum-downloads # Extract cuQuantum Beta2 archive and set the path to CUQUANTUM_ROOT $ tar -xf cuquantum-linux-x86_64-0.1.0.30-archive.tar.xz $ export CUQUANTUM_ROOT=`pwd`/cuquantum-linux-x86_64-0.1.0.30-archive $ ln -sf $CUQUANTUM_ROOT/lib $CUQUANTUM_ROOT/lib64 # Clone qsim repository from github and checkout v0.11.1 branch $ git clone https://github.com/quantumlib/qsim.git $ git checkout v0.11.1 # Build and install qsimcirq with cuStateVec $ pip install . # Install cirq $ pip install cirq
In this example, we run a circuit that creates a Greenberger-Horne-Zeilinger (GHZ) state and samples experimental outcomes. The following Python script gets the amplitudes in |0…00> and |1…11> by calling three different simulators:
- Cirq built-in simulator
- qsim CPU-based simulator
- qsim accelerated with cuStateVec
For the Cirq and qsim CPU-based simulators, we enable two sockets of a 64-core EPYC 7742 CPU. For the cuStateVec-accelerated simulation, we use a single A100 GPU.
import cirq
import qsimcirq
n_qubits = 32
qubits = cirq.LineQubit.range(n_qubits)
circuit = cirq.Circuit()
circuit.append(cirq.H(qubits[0]))
circuit.append(cirq.CNOT(qubits[idx], qubits[idx + 1]) \
for idx in range(n_qubits - 1))
# Cirqs = cirq.sim.Simulator()
result = s.compute_amplitudes(circuit, [0, 2**n_qubits-1])
print(f'cirq.sim : {result}')
# qsim(CPU)
options = qsimcirq.QSimOptions(max_fused_gate_size=4, cpu_threads=512)
s = qsimcirq.QSimSimulator(options)
result = s.compute_amplitudes(circuit, [0, 2**n_qubits-1])
print(f'qsim(CPU) : {result}')
# qsim(cuStateVec)
options = qsimcirq.QSimOptions(use_gpu=True, max_fused_gate_size=4, gpu_mode=1)
s = qsimcirq.QSimSimulator(options)
result = s.compute_amplitudes(circuit, [0, 2**n_qubits-1])
print(f'cuStateVec: {result}')
The following console output shows that the CPU version of qsim was 5.1x faster than Cirq’s simulator by optimizations with CPU SIMD instructions and OpenMP. By using cuStateVec version, the simulation is further accelerated, 30.04x faster than Cirq’s simulator and 5.9x faster than qsim’s CPU version.
cirq.sim : [0.70710677+0.j 0.70710677+0.j], 87.51 s qsim(CPU) : [(0.7071067690849304+0j), (0.7071067690849304+0j)], 17.04 s cuStateVec: [(0.7071067690849304+0j), (0.7071067690849304+0j)], 2.88 s
Performance results
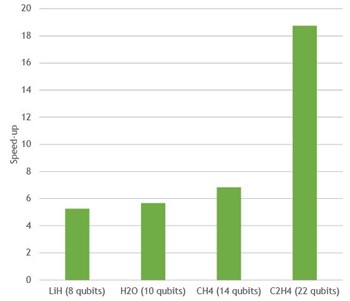
Preliminary performance results on gate applications of some popular circuits are shown in the following figures. Simulations are accelerated for all qubit counts. However, as the number of qubits is increased, the simulation becomes significantly accelerated, by a factor of roughly 10-20x for the largest circuits. This performance opens opportunities to explore development and evaluation of larger quantum circuits.
Cirq/qsim + cuStateVec on the A100 versus 64-core CPU
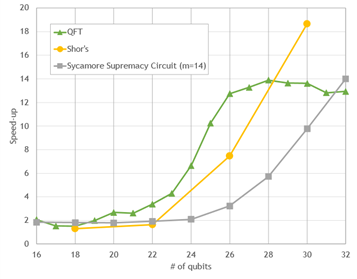
VQE speed-up On One NVIDIA A100 relative to 64 CPU cores in EPYC 7742
Multi-GPU state vector simulation
State vector simulations are also well suited for execution on multiple GPUs. Most gate applications are a perfectly parallel operation and accelerated by splitting the state vector and distributing it on several GPUs.
Beyond approximately 30 qubits, a multi-GPU simulation is inevitable. This is because a state vector is not able to fit in a single GPU’s memory due to its exponential increase in size with additional qubits.
When multiple GPUs work together on a simulation, each GPU can apply a gate to its part of the state vector in parallel. In most cases, each GPU only needs local data for the update of the state vector and each GPU can apply the gate independently.
However, depending on which of the simulated qubits a gate acts on, the GPUs might sometimes require parts of the state vector stored in a different GPU to perform the update. In this case, the GPUs must exchange large parts of the state vector. These parts are typically hundreds of megabytes or several gigabytes in size. Therefore, multi-GPU state vector simulations are sensitive to the bandwidth of the GPU interconnect.
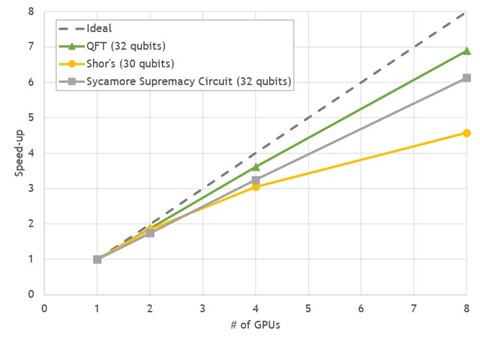
The DGX A100 is a perfect match for these requirements, with eight NVIDIA A100 GPUs providing a GPU-to-GPU direct bandwidth of 600GB/s using NVLink. We chose three common quantum computing algorithms with 30-32 qubits to benchmark Cirq/qsim with cuStateVec on the DGX A100:
- Quantum Fourier Transform (QFT)
- Shor’s algorithm
- Sycamore Supremacy circuit
All benchmarks show good strong-scaling behavior between 4.5–7x speed-up on eight GPUs, compared to a single GPU run.
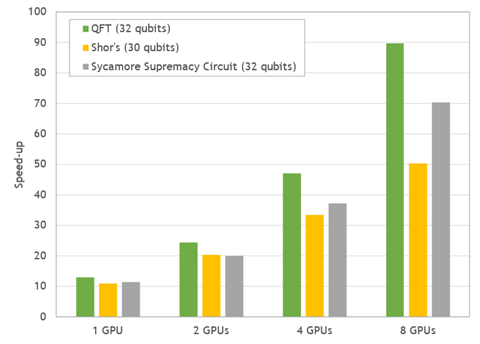
In comparison to the simulation time on two 64-core CPUs, the DGX-A100 delivers impressive overall speed-ups between 50–90x.
Summary
The cuStateVec library in the NVIDIA cuQuantum SDK aims to accelerate state vector simulators of quantum circuits on GPUs. Google’s simulator for Cirq qsim is one of the first simulators to adopt the library, benefiting Cirq users with the library’s GPU acceleration for their existing programs. Integrations to more quantum circuit frameworks will follow, including IBM’s Qiskit software.
We are also scaling up. Preliminary results for cuStateVec-based multi-GPU simulations show a 50–90x speedup on key quantum algorithms. We hope that cuStateVec becomes a valuable tool for breaking new ground in quantum computing.
Have feedback and suggestions on how we can improve the cuQuantum libraries? Send an email to cuquantum-feedback@nvidia.com.
Getting Started
The current Beta 2 version of cuQuantum is available for download. Documentation can be found here, and examples are on our GitHub.
Download the cuQuantum Appliance, our container for multi-GPU cuStateVec.
For more information, see the following resources:
- cuQuantum beta (includes cuTensorNet)
- cuQuantum documentation
- NVIDIA/cuQuantum GitHub repo
- cuQuantum Appliance
- What is Quantum Computing?
- NVIDIA Teams With Google Quantum AI, IBM and Other Leaders to Speed Research in Quantum Computing
- NVIDIA Sets World Record for Quantum Computing Simulation With cuQuantum Running on DGX SuperPOD
GTC 2022
You can learn more about NVIDIA cuQuantum and other advances through GTC sessions and posts: