
NVIDIA cuQuantum is an SDK of optimized libraries and tools for accelerating quantum computing workflows. With NVIDIA Tensor Core GPUs, developers can use it to speed up quantum circuit simulations based on state vector and tensor network methods by orders of magnitude.
cuQuantum aims to deliver at the speed of light on NVIDIA GPUs and CPUs for quantum circuit simulations. Users of quantum computing frameworks can leverage cuQuantum-backed simulators to realize GPU acceleration for their workloads.
What’s new in cuQuantum 23.10?
cuQuantum 23.10 includes updates to both NVIDIA cuTensorNet and NVIDIA cuStateVec. New features include support for NVIDIA Grace Hopper systems. For more information, see the cuQuantum 23.10 release notes.
Tensor network high-level APIs and gradients
cuTensorNet provides high-level APIs to facilitate quantum simulator developers to program in an intuitive way to make the most of their capabilities. This technology enables developers to abstract away specific tensor network knowledge when creating simulators. This makes building a tensor-network-based quantum simulator simpler, as it covers expectations, measurements, samples, and other elements.
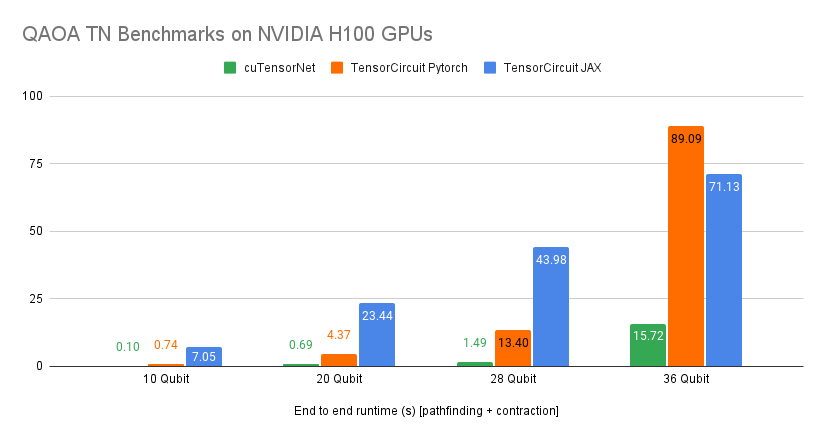
We’ve introduced experimental support for gradient calculations from a given tensor network aimed at accelerating quantum machine learning with tensor networks. This enables drastic speedups for QML and adjoint differentiation-based workflows with cuTensorNet.
Scale up state vector simulations with fewer devices
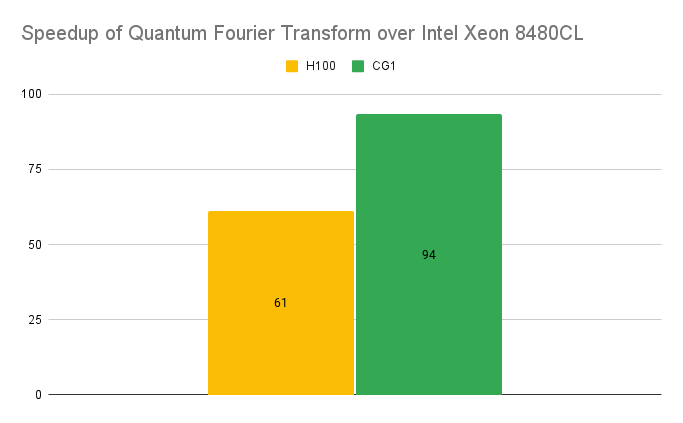
cuStateVec introduces new APIs for host-to-device state vector swap, which enables the use of CPU memory with GPUs to further scale simulations. Now, 40 qubit state vector simulations only require 16 NVIDIA Grace Hopper systems instead of 128 NVIDIA H100 80GB GPUs. As you can see by the speedup offered by these systems, NVIDIA Grace Hopper drastically outperforms the NVIDIA Hopper GPU architecture when used with other CPUs, and CPU-only implementations. This leads to substantial cost and energy savings for each workload.
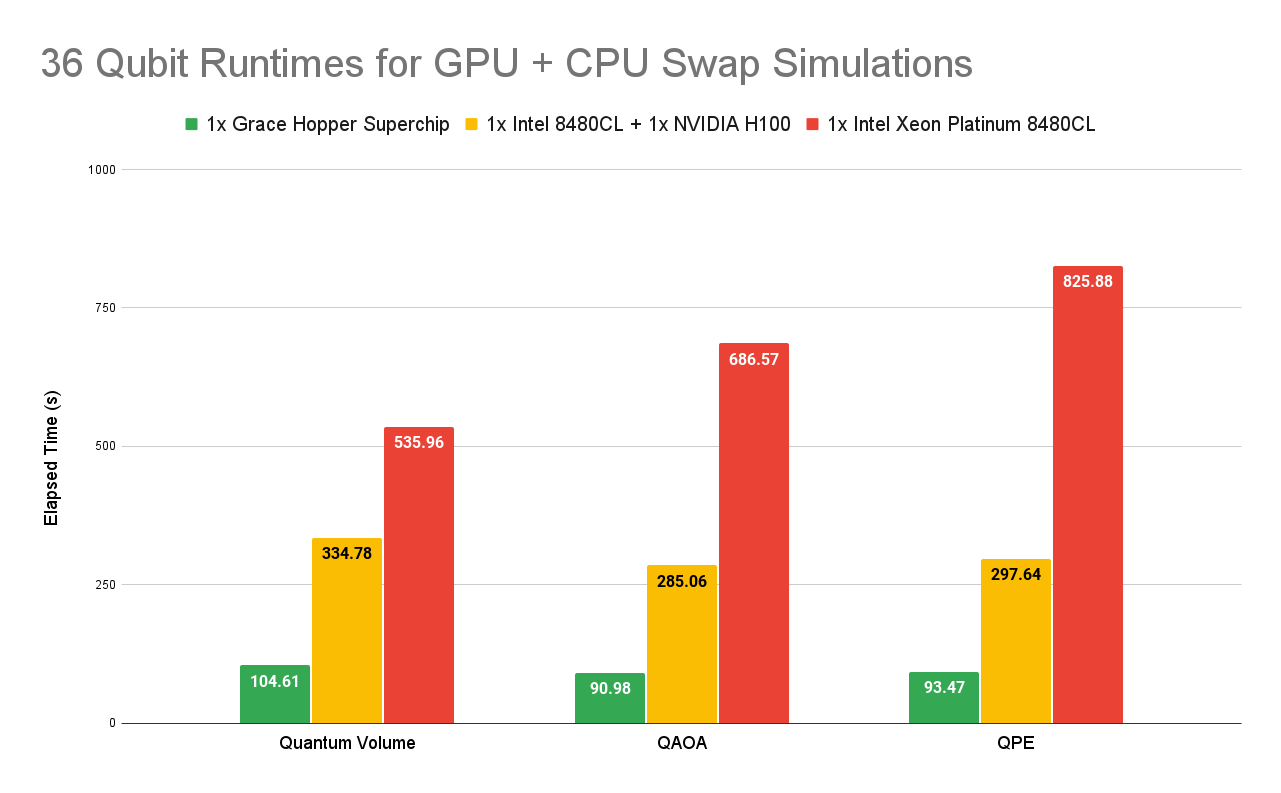
Additional API-level and kernel-level optimizations have been made to improve performance further. Grace Hopper systems provide better runtimes than other CPU and Hopper systems. The chip-to-chip interconnect and better CPU afford faster runtimes.
Getting started with cuQuantum
cuQuantum offers documentation to help with getting started. If you are running a CSP, we encourage users to check out marketplace listings for each major CSP.
After you have set up your environment, we recommend checking out our benchmark suite on GitHub and validating that you are engaging GPUs in your benchmarks.
Please reach out with questions, requests, or issues on GitHub.
