
As of March 21, 2023, QODA is now CUDA Quantum. For up-to-date information, see the CUDA Quantum page.
Quantum circuit simulation is critical for developing applications and algorithms for quantum computers. Because of the disruptive nature of known quantum computing algorithms and use cases, quantum algorithms researchers in government, enterprise, and academia are developing and benchmarking novel quantum algorithms on ever-larger quantum systems.
In the absence of large-scale, error-corrected quantum computers, the best way of developing these algorithms is through quantum circuit simulation. Quantum circuit simulations are computationally intensive, and GPUs are a natural tool for calculating quantum states. To simulate larger quantum systems, it is necessary to distribute the computation across multiple GPUs and multiple nodes to leverage the full computational power of a supercomputer.
NVIDIA cuQuantum is a software development kit (SDK) that enables users to easily accelerate and scale quantum circuit simulations with GPUs, facilitating a new capacity for exploration on the path to quantum advantage.
This SDK includes the recently released NVIDIA cuQuantum Appliance, a deployment-ready software container, with multi-GPU state vector simulation support. Generalized multi-GPU APIs are also now available in cuStateVec, for easy integration into any simulator. For tensor network simulation, the slicing API provided by the cuQuantum cuTensorNet library enables accelerated tensor network contractions distributed across multiple GPUs or multiple nodes. This has allowed users to take advantage of DGX A100 systems with nearly linear strong scaling.
The NVIDIA cuQuantum SDK features libraries for state vector and tensor network methods. This post focuses on cuStateVec for multi-node state vector simulation and the cuQuantum Appliance. If you are interested in learning more about cuTensorNet and tensor network methods, see Scaling Quantum Circuit Simulation with NVIDIA cuTensorNet.
What is a multi-node, multi-GPU state vector simulation
A node is a single package unit made up of tightly interconnected processors optimized to work together while maintaining a rack-ready form factor. Multi-node multi-GPU state vector simulations take advantage of multiple GPUs within a node and multiple nodes of GPUs to provide faster time to solution and larger problem sizes than would otherwise be possible.
DGX enables users to take advantage of high memory, low latency, and high bandwidth. The DGX H100 system is made up of eight H100 Tensor Core GPUs, leveraging the fourth-generation NVLink and third-generation NVSwitch. This node is a powerhouse for quantum circuit simulation.
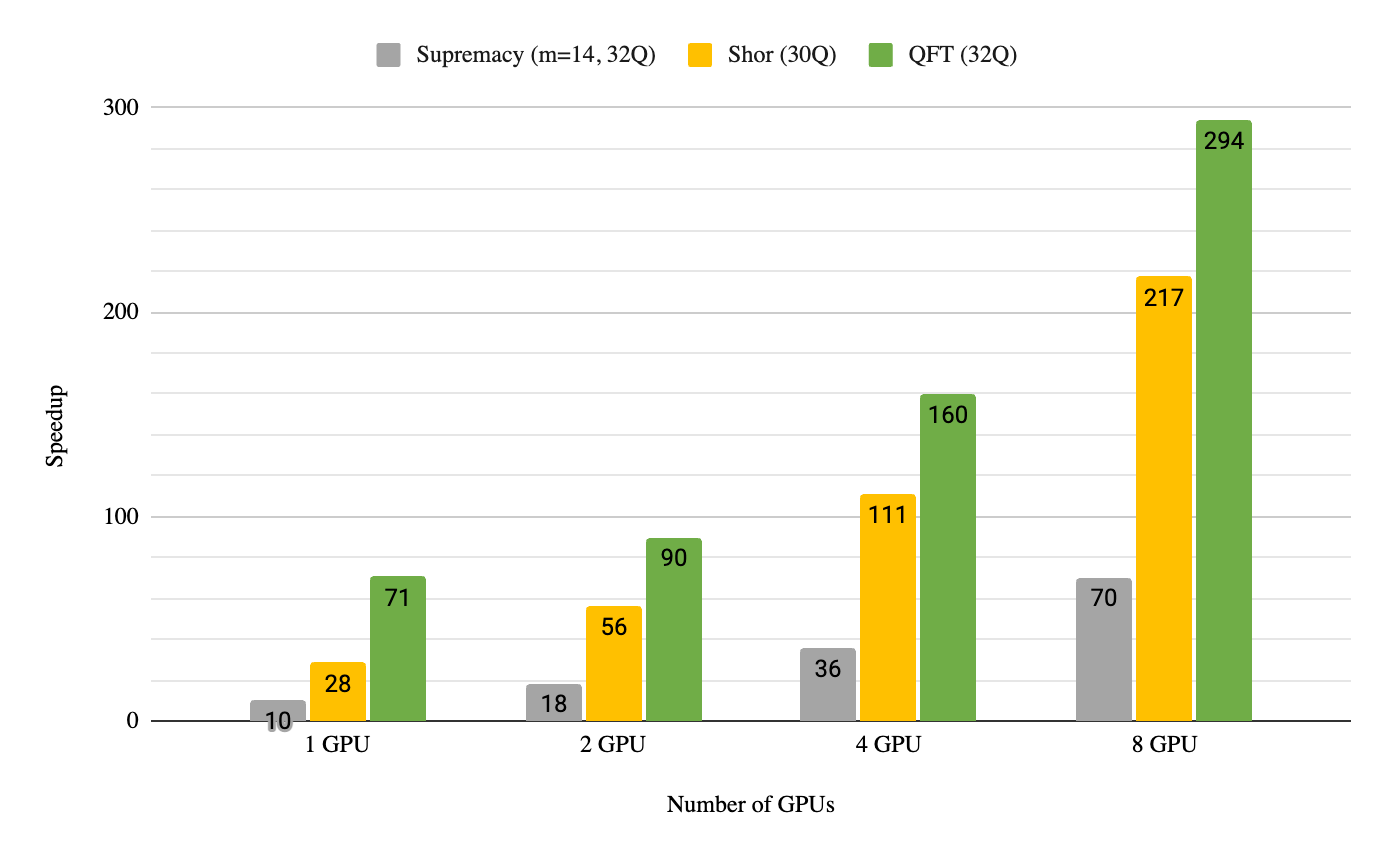
Running on a DGX A100 node with the NVIDIA multi-GPU-enabled cuQuantum Appliance on all eight GPUs resulted in 70x to 290x speedups over dual 64-core AMD EPYC 7742 processors for three common quantum computing algorithms: Quantum Fourier Transform, Shor’s Algorithm, and the Sycamore Supremacy circuit. This has enabled users to simulate up to 36 qubits with full state vector methods using a single DGX A100 node (eight GPUs). The results shown in Figure 1 are 4.4x higher since we last announced benchmarks for this capability, due to software-only enhancements our team has implemented.
The NVIDIA cuStateVec team has intensively investigated a performant means of leveraging multiple nodes in addition to multiple GPUs within a single node. Because most gate applications are perfectly parallel operations, GPUs within and across nodes can be orchestrated to divide and conquer.
During the simulation, the state vector is split and distributed among GPUs, and each GPU can apply a gate to its part of the state vector in parallel. In many cases this can be handled locally; however, gate applications to high-order qubits require communication among distributed state vectors.
One typical approach is to first reorder qubits and then apply gates in each GPU without accessing other GPUs or nodes. This reordering itself needs data transfers between devices. To do this efficiently, high interconnect bandwidth becomes incredibly important. Efficiently taking advantage of this parallelizability is non-trivial across multiple nodes.
Introducing the multi-node cuQuantum Appliance
The answer to performantly and arbitrarily scale state vector-based quantum circuit simulation is here. NVIDIA is pleased to announce the multi-node, multi-GPU capability delivered in the new cuQuantum Appliance. In our next release, any cuQuantum container user will be able to quickly and easily leverage an IBM Qiskit frontend to simulate quantum circuits on the largest NVIDIA systems in the world.
The cuQuantum mission is to enable as many users as possible to easily accelerate and scale quantum circuit simulation. To that end, the cuQuantum team is working to productize the NVIDIA multi-node approach into APIs, which will be in general availability early next year. With this approach, you will be able to leverage a wider range of NVIDIA GPU-based systems to scale your state vector quantum circuit simulations.
The NVIDIA multi-node cuQuantum Appliance is in its final stages of development, and you will soon be able to take advantage of the best-in-class performance available with NVIDIA DGX SuperPOD systems. This will be offered as an NGC-hosted container image that you can quickly deploy with the help of Docker and a few lines of code.
With the fastest I/O architecture of any DGX system, NVIDIA DGX H100 is the foundational building block for large AI clusters like NVIDIA DGX SuperPOD, the enterprise blueprint for scalable AI, and now, quantum circuit simulation infrastructure. The eight NVIDIA H100 GPUs in the DGX H100 use the new high-performance fourth-generation NVLink technology to interconnect through four third-generation NVSwitches.
The fourth-generation NVLink technology delivers 1.5x the communications bandwidth of the prior generation and is up to 7x faster than PCIe Gen5. It delivers up to 7.2 TB/sec of total GPU-to-GPU throughput, an improvement of almost 1.5x compared to the prior generation DGX A100.
Along with the eight included NVIDIA ConnectX-7 InfiniBand / Ethernet adapters, each running at 400 GB/sec, the DGX H100 system provides a powerful high-speed fabric saving overhead in global communications among state vectors distributed across multiple nodes. The combination of multi-node, multi-GPU cuQuantum with massive GPU-accelerated compute leveraging state-of-the-art networking hardware and software optimizations means that DGX H100 systems can scale to hundreds or thousands of nodes to meet the biggest challenges, such as scaling full state vector quantum circuit simulation past 50 qubits.
To benchmark this work, the multi-node cuQuantum Appliance is run on the NVIDIA Selene Supercomputer, the reference architecture for NVIDIA DGX SuperPOD systems. As of June 2022, Selene is ranked eighth on the TOP500 list of supercomputing systems executing the High Performance Linpack (HPL) benchmark with 63.5 petaflops, and number 22 on the Green500 list with 24.0 gigaflops per watt.
NVIDIA ran benchmarks leveraging the multi-node cuQuantum Appliance: Quantum Volume, the Quantum Approximate Optimization Algorithm (QAOA), and Quantum Phase Estimation. The Quantum Volume circuit ran with a depth of 10 and 30. QAOA is a common algorithm used to solve combinatorial optimization problems on, relatively, near-term quantum computers. We ran it with two parameters.
Both weak and strong scaling are demonstrated in the preceding algorithms. It is clear that scaling to a supercomputer like the NVIDIA DGX SuperPOD is valuable for both accelerating time-to-solution and extending the phase space researchers can explore with state vector quantum circuit simulation techniques.
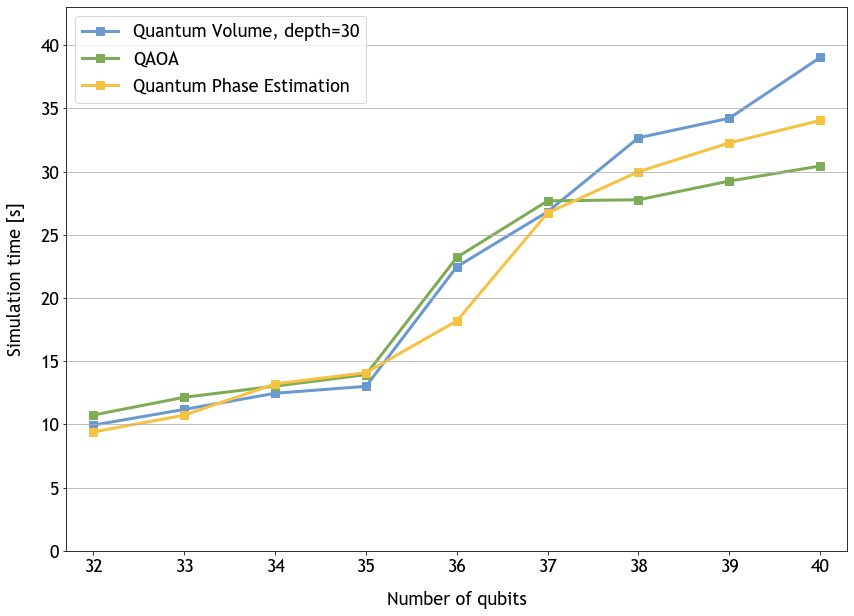
We are further enabling users to achieve scale with our updated cuQuantum Appliance. By introducing multi-node capabilities, we are enabling users to move beyond 32 qubits on one GPU, and 36 qubits on one NVIDIA Ampere Architecture node. We simulate a total of 40 qubits with 32 DGX A100 nodes. Users will now be able to scale out even further depending upon system configurations, with a software limit of 56 qubits or millions of DGX A100 nodes. Our other preliminary tests on NVIDIA Hopper GPUs have shown us that these numbers will be even better on our next-generation architecture.
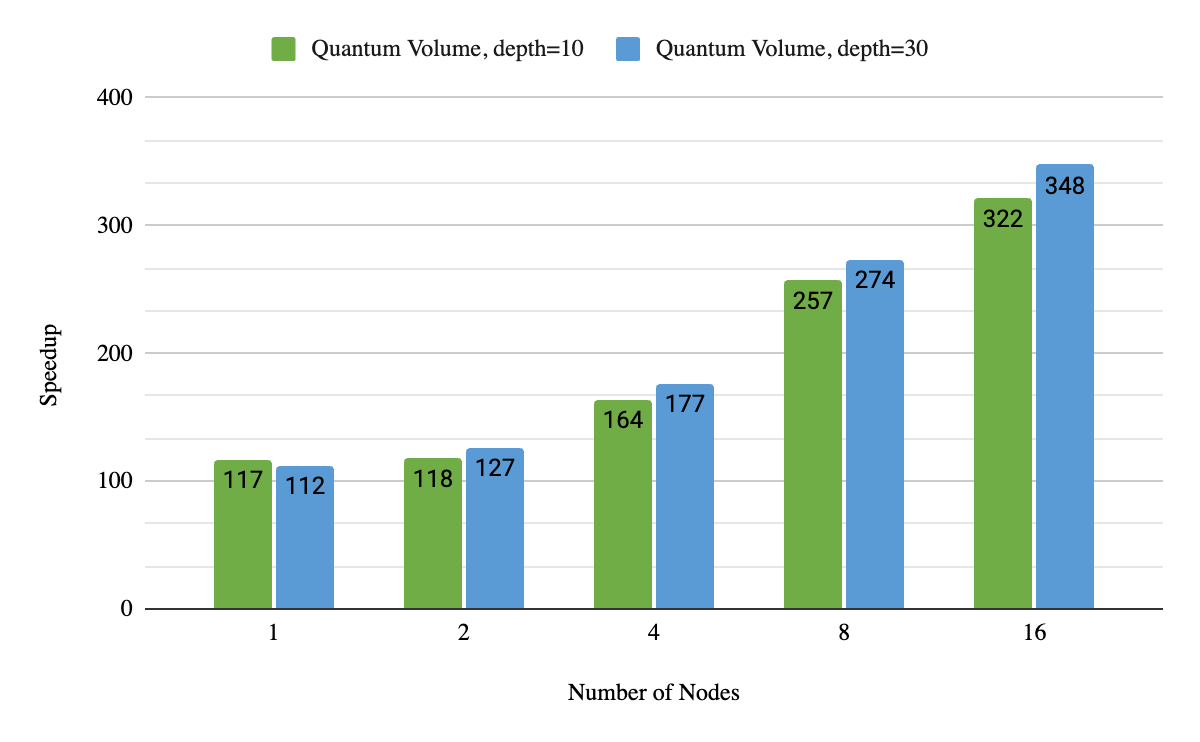
We also measured the strong scaling of our multi-node capabilities. We focused on Quantum Volume for simplicity. Figure 3 describes the performance when we solved the same problem multiple times changing the number of GPUs. Compared to state-of-the-art dual-socket server CPU, we obtained 320x to 340x speedups when leveraging 16 DGX A100 nodes. This is also 3.5x faster than the previous state-of-the-art implementation of quantum volume (depth=10 for 36 qubits with just two DGX A100 nodes). When adding more nodes, this speedup becomes more dramatic.
Simulate and scale quantum circuits on the largest NVIDIA systems
The cuQuantum team at NVIDIA is scaling up state vector simulation to multi-node, multi-GPU. This enables end users to conduct quantum circuit simulation for full state vectors larger than ever before. Not only has cuQuantum enabled scale, but also performance, showing weak scaling and strong scaling across nodes.
In addition, cuQuantum introduced the first cuQuantum-powered IBM Qiskit image. In our next release, you will be able to pull this container, making it easier and faster to scale up quantum circuit simulations with this popular framework.
While the multi-node cuQuantum Appliance is in private beta today, NVIDIA expects to release it publicly over the coming months. The cuQuantum team intends to release multi-node APIs within the cuStateVec library by spring 2023.
Getting started with cuQuantum Appliance
When the multi-node cuQuantum Appliance is in general availability later this year, you will be able to pull the Docker image from the NGC catalog for containers.
You can reach out to the cuQuantum team with questions through the Quantum Computing Forum. Contact us on the NVIDIA/cuQuantum GitHub repo with feature requests or to report a bug.
For more information, see the following resources:
- cuQuantum (includes cuTensorNet)
- cuQuantum documentation
- NVIDIA/cuQuantum GitHub repo
- cuQuantum Appliance
- What Is Quantum Computing?
- Lightning Fast simulations with Pennylane and the NVIDIA cuQuantum SDK
- Orquestra Integration with NVIDIA cuQuantum
- NVIDIA cuQuantum and QODA Adoption Accelerates
GTC 2022 and cuQuantum
Join us for these GTC 2022 sessions to learn more about NVIDIA cuQuantum and other advancements:
- GTC 2022 Keynote
- A Deep Dive into the Latest HPC Software
- Defining the Quantum-Accelerated Supercomputer
- Scaling Quantum Circuit Simulations with cuQuantum for Quantum Algorithms
- Quantum Computing Simulation in Pharmaceuticals Research
- Accelerating Quantum Computing Research with GPUs
- AI for Science: Heralding Scientific Breakthroughs through AI
