
At COMPUTEX 2023, NVIDIA announced the NVIDIA DGX GH200, which marks another breakthrough in GPU-accelerated computing to power the most demanding giant AI workloads. In addition to describing critical aspects of the NVIDIA DGX GH200 architecture, this post discusses how NVIDIA Base Command enables rapid deployment, accelerates the onboarding of users, and simplifies system management.
The unified memory programming model of GPUs has been the cornerstone of various breakthroughs in complex accelerated computing applications over the last 7 years. In 2016, NVIDIA introduced NVLink technology and the Unified Memory Programming model with CUDA-6, designed to increase the memory available to GPU-accelerated workloads.
Since then, the core of every DGX system has been a GPU complex on a baseboard interconnected with NVLink in which each GPU can access the other’s memory at NVLink speed. Many such DGX with GPU complexes are interconnected with high-speed networking to form larger supercomputers such as the NVIDIA Selene supercomputer. Yet an emerging class of giant, trillion-parameter AI models will require either several months to train or cannot be solved even on today’s best supercomputers.
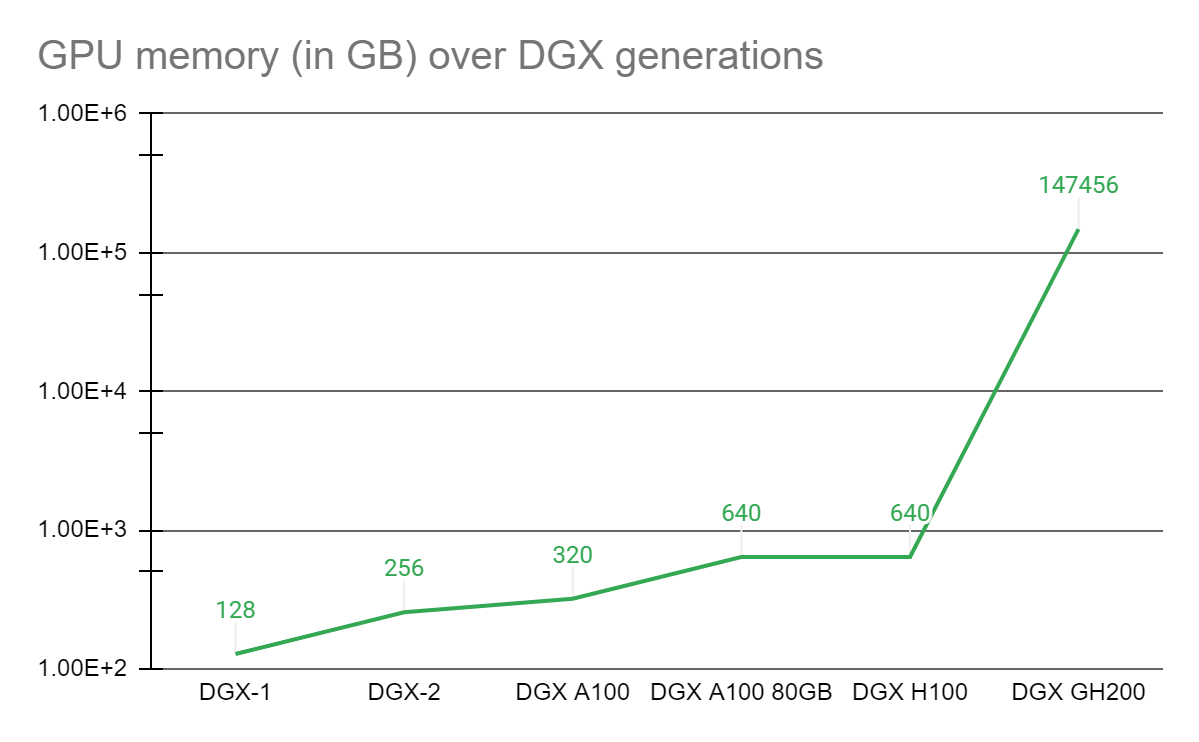
Empowering scientists needing an advanced platform for solving these challenges, NVIDIA paired the NVIDIA Grace Hopper Superchip with the NVLink Switch System, uniting up to 256 GPUs in an NVIDIA DGX GH200 system. On the DGX GH200 system, 144 terabytes of memory are accessible to the GPU-shared memory programming model at high speed over NVLink.
Compared to a single NVIDIA DGX A100 320 GB system, the NVIDIA DGX GH200 provides nearly 500x more memory to the GPU shared memory programming model over NVLink, forming a giant data center-sized GPU. NVIDIA DGX GH200 is the first supercomputer to break the 100 terabyte barrier for memory accessible to GPUs over NVLink.
NVIDIA DGX GH200 system architecture
NVIDIA Grace Hopper Superchip and NVLink Switch System are the building blocks of the NVIDIA DGX GH200 architecture. NVIDIA Grace Hopper Superchip combines the Grace and Hopper architectures using NVIDIA NVLink-C2C to deliver a CPU + GPU coherent memory model. The NVLink Switch System, powered by the fourth generation of NVLink technology, extends NVLink connection across superchips to create a seamless, high-bandwidth, multi-GPU system.
Each NVIDIA Grace Hopper Superchip in NVIDIA DGX GH200 has 480 GB LPDDR5 CPU memory, at an eighth of the power per GB, compared with DDR5 and 96 GB of fast HBM3. NVIDIA Grace CPU and Hopper GPU are interconnected with NVLink-C2C, providing 7x more bandwidth than PCIe Gen5 at one-fifth the power.
The NVLink Switch System forms a two-level, non-blocking, fat-tree NVLink fabric to connect 256 Grace Hopper Superchips in a DGX GH200 system fully. Every GPU in DGX GH200 can access the memory of other GPUs and extended GPU memory of all NVIDIA Grace CPUs at 900 GBps.
Compute baseboards hosting Grace Hopper Superchips are connected to the NVLink Switch System using a custom cable harness for the first layer of NVLink fabric. LinkX cables extend the connectivity in the second layer of NVLink fabric.
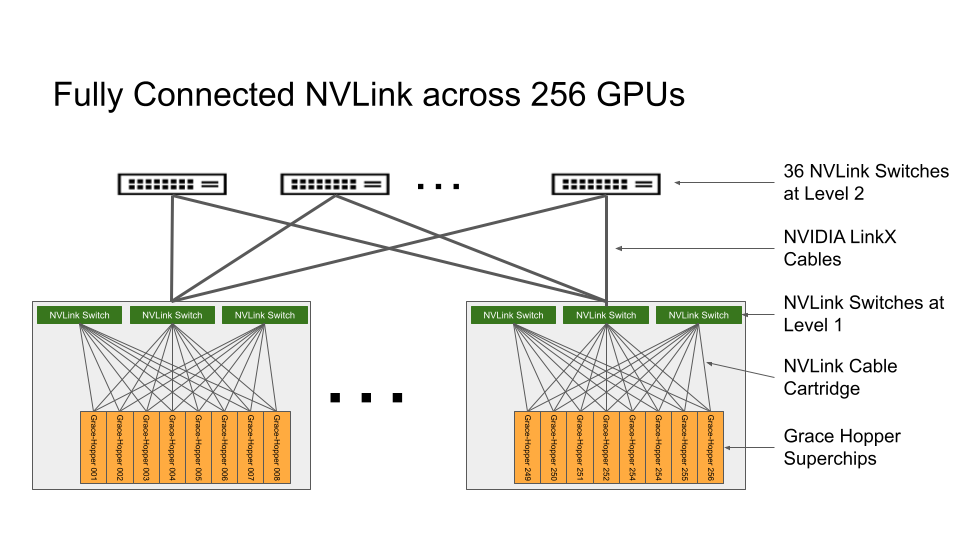
In the DGX GH200 system, GPU threads can address peer HBM3 and LPDDR5X memory from other Grace Hopper Superchips in the NVLink network using an NVLink page table. NVIDIA Magnum IO acceleration libraries optimize GPU communications for efficiency, enhancing application scaling with all 256 GPUs.
Every Grace Hopper Superchip in DGX GH200 is paired with one NVIDIA ConnectX-7 network adapter and one NVIDIA BlueField-3 NIC. The DGX GH200 has 128 TBps bi-section bandwidth and 230.4 TFLOPS of NVIDIA SHARP in-network computing to accelerate collective operations commonly used in AI. It also doubles the effective bandwidth of the NVLink Network System by reducing the communication overheads of collective operations.
For scaling beyond 256 GPUs, ConnectX-7 adapters can interconnect multiple DGX GH200 systems to scale into an even larger solution. The power of BlueField-3 DPUs transforms any enterprise computing environment into a secure and accelerated virtual private cloud, enabling organizations to run application workloads in secure, multi-tenant environments.
Target use cases and performance benefits
The generational leap in GPU memory significantly improves the performance of AI and HPC applications bottlenecked by GPU memory size. Many mainstream AI and HPC workloads can reside entirely in the aggregate GPU memory of a single NVIDIA DGX H100. For such workloads, the DGX H100 is the most performance-efficient training solution.
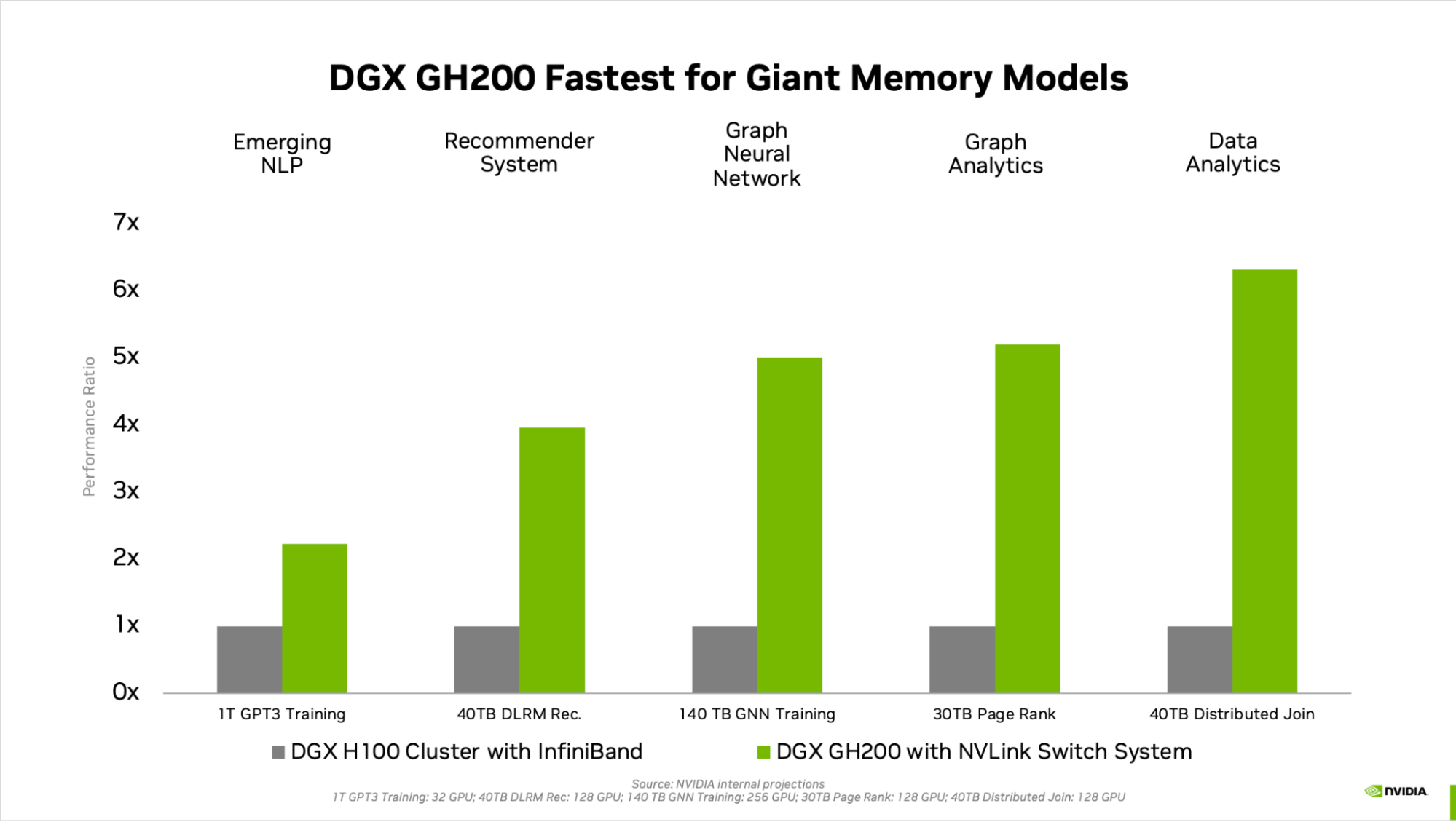
Other workloads—such as a deep learning recommendation model with terabytes of embedded tables, a terabyte-scale graph neural network training model, or large data analytics workloads—see speedups of 4x to 7x with DGX GH200. This shows that the DGX GH200 is a better solution for the more advanced AI and HPC models requiring massive memory for GPU-shared memory programming.
The mechanics of speedup are described in detail in the NVIDIA Grace Hopper Superchip Architecture whitepaper.
Purpose-designed for the most demanding workloads
Every component throughout DGX GH200 is selected to minimize bottlenecks while maximizing network performance for key workloads and fully using all scale-up hardware capabilities. The result is linear scalability and high utilization of the massive, shared memory space.
To get the most out of this advanced system, NVIDIA also architected an extremely high-speed storage fabric to run at peak capacity. It handles a variety of data types (text, tabular data, audio, and video) in parallel and with unwavering performance.
Full-stack NVIDIA solution
DGX GH200 comes with NVIDIA Base Command, which includes an OS optimized for AI workloads, cluster manager, libraries that accelerate compute, storage, and network infrastructure optimized for DGX GH200 system architecture.
DGX GH200 also includes NVIDIA AI Enterprise, providing a suite of software and frameworks optimized to streamline AI development and deployment. This full-stack solution enables customers to focus on innovation and worry less about managing their IT infrastructure.

Supercharge giant AI and HPC workloads
NVIDIA is working to make the DGX GH200 available at the end of this year. NVIDIA is eager to provide this incredible first-of-its-kind supercomputer and empower you to innovate and pursue your passions in solving today’s biggest AI and HPC challenges. Learn more.
