

The NVIDIA mission is to accelerate the work of the da Vincis and Einsteins of our time. Scientists, researchers, and engineers are focused on solving some of the world’s most important scientific, industrial, and big data challenges using artificial intelligence (AI) and high performance computing (HPC).
The NVIDIA HGX A100 with A100 Tensor Core GPUs delivers the next giant leap in our accelerated data center platform, providing unprecedented acceleration at every scale and enabling innovators to do their life’s work in their lifetime.
In this post, I introduce two HGX A100 platforms to help advance AI and HPC:
- HGX A100 8-GPU connected with NVSwitch
- HGX A100 4-GPU connected with NVLink
I discuss their use cases, application benefits, and recommendations on how best to integrate HGX A100 into next-generation servers. This helps you have a more holistic, system-level view and more effectively use the latest computing technologies.
HGX A100 8-GPU connected with NVSwitch for fastest time-to-solution
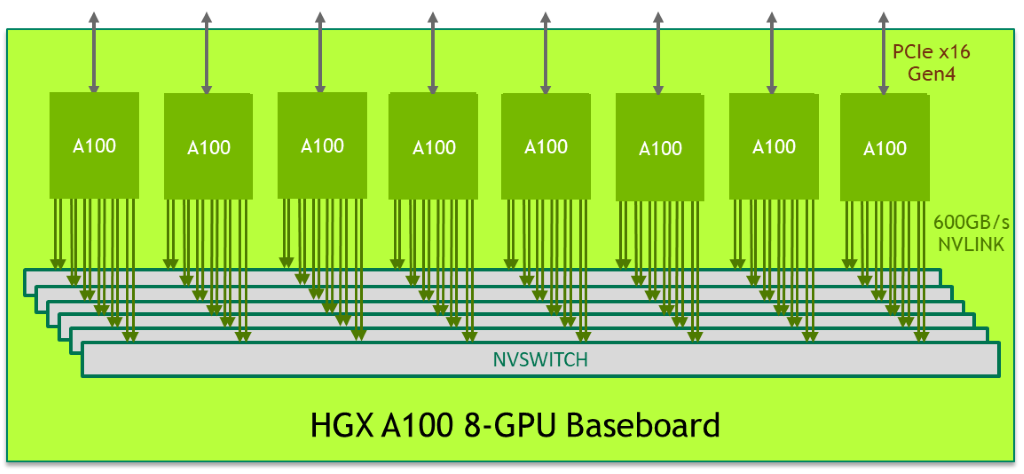
The HGX A100 8-GPU baseboard represents the key building block of the HGX A100 server platform. Figure 1 shows the baseboard hosting eight A100 Tensor Core GPUs and six NVSwitch nodes. Each A100 GPU has 12 NVLink ports, and each NVSwitch node is a fully non-blocking NVLink switch that connects to all eight A100 GPUs.
This fully connected mesh topology enables any A100 GPU to talk to any other A100 GPU at a full NVLink bi-directional speed of 600 GB/s, which is 10x times the bandwidth of the fastest PCIe Gen4 x16 bus. Two baseboards can also be connected back-to-back using NVSwitch to NVLink, enabling 16 A100 GPUs to be fully connected.

Putting the HGX A100 8-GPU server platform together
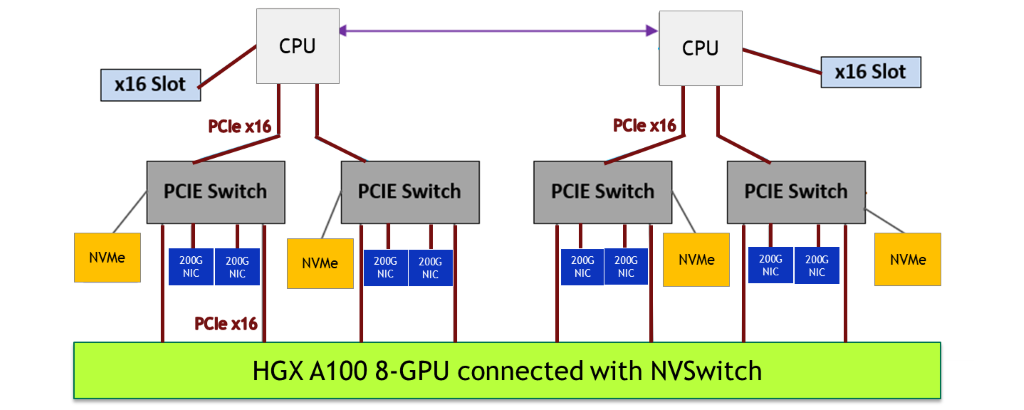
With the GPU baseboard building block, the NVIDIA server-system partners customize the rest of the server platform to specific business needs: CPU subsystem, networking, storage, power, form factor, and node management. To deliver the highest performance, we recommend the following system design considerations:
- Select two highest-end server CPUs to pair with the eight A100 GPUs, to keep up with the A100.
- Use plenty of PCIe links. Use a minimum of four PCIe x16 links between the two CPUs and eight A100 GPUs, to make sure there is enough bandwidth for the CPUs to push commands and data into the A100 GPU.
- For the best AI training performance at scale (many nodes together running a single training job), networking performance between nodes is critical. Use a ratio of up to 1:1 A100 GPUs to network interface cards (NICs). The Mellanox ConnectX-6 200-Gb/s NIC is the best option.
- Attach NIC and NVMe storage to the PCIe switch and place it close to the A100 GPU. Use a shallow and balanced PCIe tree topology. The PCIe switch enables the fastest peer-to-peer transfer from NIC and NVMe in and out of the A100 GPU.
- Adopt GPUDirect Storage, which reduces read/write latency, lowers CPU overhead, and enables higher performance.
NVSwitch benefit
The HGX A100 8-GPU baseboard brings in the latest NVSwitch design. Besides enabling the fastest A100-to-A100 peer communication at 600 GB/s, NVSwitch also helps improve productivity, enables new use cases, and enhances deployment flexibility:
- Easier to program—You do not need to worry about the specific topology between A100 GPUs. Any A100 GPU can talk to any other A100 GPU at full 600 GB/s NVLink speed. You can focus more time on solving the science and less time worrying about specific system implementations.
- Much larger AI models—Larger AI models often help improve prediction accuracy. Model parallelism divides up a large model and distributes to the memory of different A100 GPUs. NVSwitch ensures that the intense communication within the model is not a bottleneck. Model parallelism is now more feasible.
- Flexible multi-tenant isolation—When multiple users share an HGX A100 GPU system, with each user owning one or more A100 GPUs, the NVSwitch node can turn off NVLink ports to isolate tenants, while maintaining full peer-to-peer NVLink speed between the A100 GPUs that an individual tenant owns.
HGX A100 4-GPU connected with NVLink for general purpose acceleration
While the HGX A100 8-GPU with NVSwitch provides the fastest performance, there are application scenarios where a HGX A100 4-GPU server node is optimal. For example, you might have the following scenarios:
- The target workloads, such as certain scientific applications, prefer more CPU capacity to match the fast A100 GPU. Four A100 GPUs to two CPUs is a more balanced ratio.
- Some data centers have limited rack power, due to infrastructure limitations. A lower GPU count platform with lower server power is preferred.
- Some site administrators like to allocate resources to users in node granularity (with a minimum of 1 node) for simplicity. An HGX A100 4-GPU node enables a finer granularity and helps support more users.
HGX A100 4-GPU baseboard
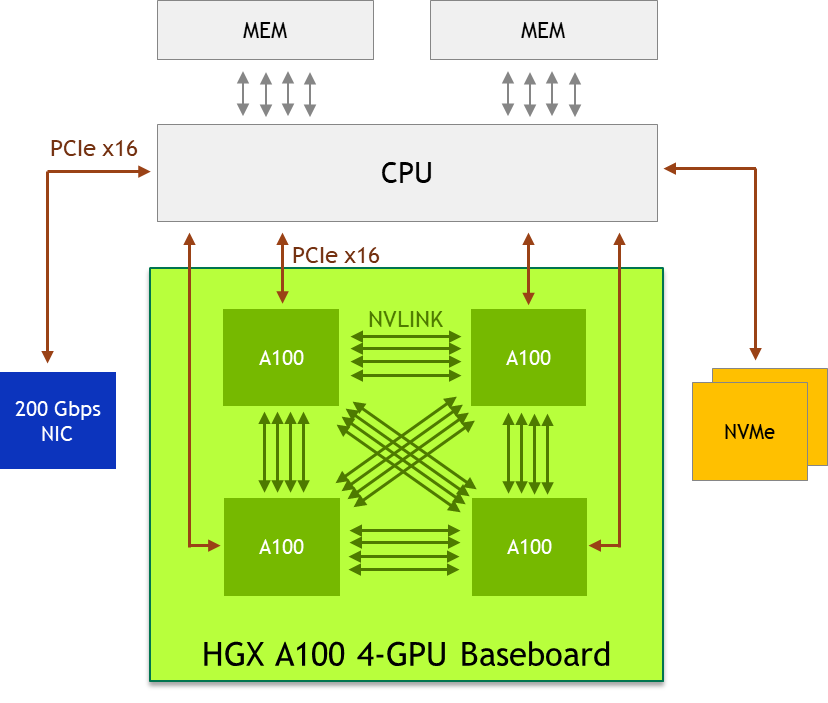
The four A100 GPUs on the GPU baseboard are directly connected with NVLink, enabling full connectivity. Any A100 GPU can access any other A100 GPU’s memory using high-speed NVLink ports. The A100-to-A100 peer bandwidth is 200 GB/s bi-directional, which is more than 3X faster than the fastest PCIe Gen4 x16 bus.

Putting the HGX A100 4-GPU server platform together
To deliver the most efficient acceleration, we recommend the following system design considerations:
- Use a single, high core count CPU if the workload does not require extra CPU capacity. This lowers system BOM and power and simplifies scheduling.
- Free the PCIe switch! Direct connect from the CPU to the A100 GPU to save system BOM and power.
- Equip the node with one or two 200-Gb/s NIC and NVMe to cover a wide variety of use cases. The Mellanox ConnectX-6 200Gb/s NIC is the best option.
- Adopt GPUDirect Storage, which reduces read/write latency, lowers CPU overhead, and enables higher performance.
Most powerful server platform for AI and HPC
NVIDIA is working closely with our ecosystem partners to bring the HGX A100 server platform to the cloud later this year. We are looking forward to putting this most powerful computing tool in your hands, helping you solve the world’s most pressing challenges in business and research.
