在游戏应用程序性能方面,GPU 驱动的渲染能够提升处理大型虚拟场景的可扩展性。Direct3D 12 (D3D12) 采用工作图形(work graph)编程范式,允许 GPU 在运行时生成自己的工作。有关工作图形的介绍,请参阅 在 Direct3D 12 中使用工作图推进 GPU 驱动的渲染。
本文介绍了一个 Direct3D 12 工作图形案例研究。我将介绍通过工作图形的高效着色器代码选择和执行,常见延迟着色渲染算法如何从中受益。然后,我将从此案例研究中探索工作图形的更高级主题、学习内容和建议。
工作图形选择性着色器代码执行
相较于ExecuteIndirectDirect3D 12 (D3D12) API 中的工作图形具有在微观级别动态选择和启动着色器的独特功能。例如,考虑将屏幕划分为小块。对于每个小块,必须执行某种操作,具体取决于该小块的内容。假设每个小块有 10 种可能性。您可以使用三种不同的方法来完成此操作:
- 使用带有大型着色器的 Uber 着色器
switch/case块,其中包含所有可能的代码。 - 出现全屏问题
Dispatch运行专门针对每种可能性的着色器。着色器首先确定块是否即将与着色器进行匹配。如果不是,着色器会立即退出。 - 首先,使用一个识别矩形块并计算每种可能性的矩形块数量的过程,然后使用
ExecuteIndirect以便让 GPU 调整每个调度的网格大小。
每种方法都有其缺点。对于第一种方法,超级着色器通常会导致寄存器文件中的浪费,这是因为必须让变量保持活动状态,即使它们不用于特定的执行路径,因此会降低占用率。此外,分支还会产生一些成本。switch/case块。
第二种方法会浪费大量计算线程,以便涵盖所有可能性。第三种方法听起来最有效,但它缺少了前两种方法中不存在的分类步骤。
工作图形提供了更精美的解决方案。下面的案例研究将展示如何使用推荐和有用的工具进行调试。
多 BRDF 延迟着色案例研究
延迟着色是在游戏引擎中管理光照和材质交互的一种常见技术。通常,场景中的网格会被光栅化成一个胖 G 缓冲区,该缓冲区存储每个像素的着色参数 (例如,法线、反射率和粗糙度)。然后,一个跟随光照过程的光照过程会从 G 缓冲区获取信息,并将其应用于内容,以产生照亮的像素并将其存储在 HDR 格式的颜色缓冲区中。
光照过程本身通常附带一些加速结构,使着色器只考虑影响下方像素的光源,而不是检查整个场景中的所有光源。
只要场景中的所有材质使用相同的双向反射分布函数 (BRDF),即可正常工作,但这可能会对艺术造成限制。为了支持多个 BRDF (例如,清漆、眼睛或头发),可以在 G-buffer 中添加额外参数,以指示每个像素的 BRDF。此外,照明通道必须使用switch/case这个 BRDF 值,因此它知道如何计算材质与光线的相互作用。这听起来很熟悉吗?
我构建了一个基于此用例的示例,以探索工作图可以如何帮助。完整文档的示例代码实现了多 BRDF 延迟着色渲染器,可通过 NVIDIAGameWorks/donut_examples 获取。它展示了两种方法:uber 着色器和工作图。
此示例使用精简的 G 缓冲区布局,该布局仅存储常规和材质 ID,而非所有材质参数。这对于多 BRDF 材质非常合适,因为每种 BRDF 都可以有不同的参数集来表示材质。在着色过程中,使用材质类型来确定材质参数提取和评估的逻辑。
场景由多个舞台组成,每个舞台上都有由动画立方体组成的人群。天花板上充满了反射球,它们会在每个舞台上投射移动光线。各种颜色的移动聚光灯也照亮了场景。
此场景完全采用程序化方式生成和动画。几个控件管理场景复杂性 (网格数量、光线和材质)。材质可以使用一种几种类型 (或 BRDF),以某种方式渲染 (例如,Lambert、Phong、Metallic 或 Velvet)。
慢慢调整代码并尝试不同的场景参数,以了解这些更改对性能的影响。
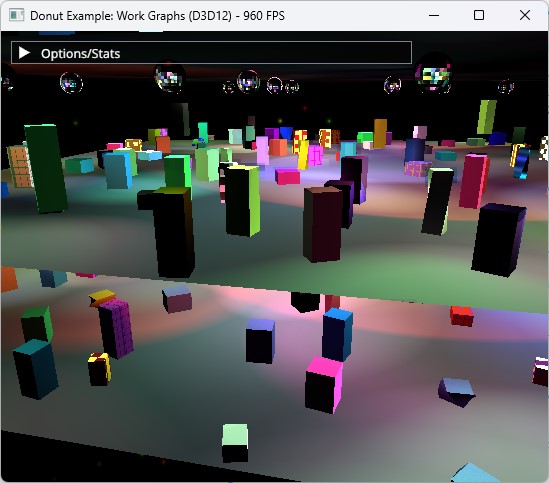
标准延迟着色计算通道使用两个计算分配:
- 瓷砖光线剔除:屏幕被划分为每个 8×4 像素的小块。对于每个小块,所有影响该小块的光线都会被收集并存储在缓冲区中。
- 使用超级着色器进行延迟着色:每块瓷砖都会再次处理,这次使用瓷砖收集的光线。所有瓷砖中发现的材质都会在超级着色器中进行评估。
最重要的是,此示例使用工作图实现了相同的延迟着色通道。
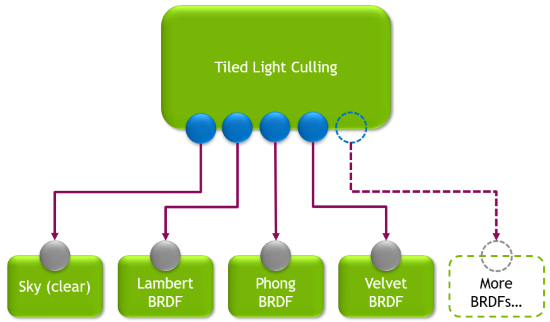
工作图技术完全取代了之前提到的两个步骤。相反,图形使用广播启动节点来复制同样的光板剪切概念。图形的根节点执行于每个屏幕矩形,节点为矩形剪切光线,并将结果存储在记录中以发送到图形的下一步。
根节点可以选择一个包含多个输出的数组,每个输出都专门用于某种 BRDF (或屏幕清除)。剔除光线列表放置在图形中的正确节点中,该节点可以处理瓷砖中的材质类型。在包含多个不同的 BRDF 的情况下,根节点会生成多个记录,以便使用所有正确的节点覆盖相同的瓷砖。
性能
GeForce RTX 4090 GPU 在 0.8 毫秒到 0.95 毫秒之间照亮了 1920 x 1080 的场景,而 Uber 着色器调度技术则需要 0.98 毫秒。下面将详细介绍这些因素。
- 工作图形执行不是免费的。管理图形记录和调度工作会产生相关成本,这些成本会吃掉工作图形取得的部分收益。
- 使用工作图形的光照性能更好地响应屏幕内容。当屏幕中包含大量天幕纹理时,光照通道的完成速度会更快。在这种情况下,屏幕中包含网格的屏幕与屏幕中包含网格的一半的屏幕 (视图不同) 的性能差异大约为 0.2 毫秒。超级着色器的性能不能很好地响应屏幕内容。它在各种视图下呈现稳定的时间。
- 工作图形中的节点着色器专门用于处理每个 BRDF,而超级着色器则必须处理所有可能的 BRDF。因此,节点着色器更有可能通过编译器优化。
- BRDF 节点着色器可以在根节点分类瓷砖后立即启动。超级着色器技术涉及资源屏障分离的两次调度,这意味着第二次调度只能在第一次调度完成后启动。
这些结果反映了我在使用工作图形的冒险中学到的一个教训,即性能提升必须超过工作图形执行所产生的开销,以便在性能方面实现盈余。示例展示了延迟着色通道如何受益于工作图形,尽管这种工作图形版本仅限于计算着色器。
内容串流游戏引擎
本节将探讨使用工作图形的渲染器如何支持大型游戏世界。考虑一下支持艺术家创作材质着色器的引擎。多 BRDF 概念仅适用于材质本身,每种材质都有自己的着色器,执行其独特的计算,甚至整个 BRDF。
当玩家在游玩游戏或移动游戏世界的不同部分时,游戏中的其他内容逐渐加载材质时,可能会出现问题。这通常被称为内容串流从图形编程的角度来看,它涉及实时加载资源,包括纹理、网格和材质。
在处理整个场景所有材质的单个工作图形方案中,如何在运行期间根据需要增加图形来处理更多材质?
一种简单的方法是完全重构图形中的 HLSL 代码,并将新材质的着色器代码注入其中。这不仅会导致大量极其缓慢的字符操作,而且编译成本可能过高,从而导致游戏中出现明显的卡顿现象。请勿采用这种方法。
一种更为成熟的方法是完全重新创建图形,并为新材质添加预编译的 DXIL 库。
理想的方法是使用 AddToStateObject API,该 API 用于在光线追踪应用程序中支持流式传输场景。Working Graphics 使得通过稀疏节点输出数组可以轻松扩展任何特定生产者的目标节点。
在这种情况下,负责材质分类的节点可以将目标输出声明为稀疏输出数组。数组的每个输出都映射到一个表示特定材质着色器的节点,而这些节点可以通过动态选择的整数值索引。有关详细信息,请参阅 DirectX 规格 以了解如何使用此功能。
推荐内容
在使用工作图之后,我收集了一些学习和建议,这些学习和建议应该有助于让流程更有趣,并减少不愉快的惊喜。
- 在设计或调整现有算法以处理图形时,了解从上到下传输的数据的心智模型,从而推动可能扩展的工作。
- 工作图形擅长根据不同的条件执行不同的着色器。避免使用超级着色器节点。相反,将着色器分解为单个更简单的特殊节点着色器,这些特殊节点着色器可以受益于减少的寄存器压力和更少的执行偏差。
- 致力于节点着色器,而不是小型操作集合。否则,工作图形的成本将主要受到执行开销的影响。
- 尽可能避免在图形中对相同资源进行 UAV 读取和写入。这些资源需要
globallycoherent以保证正确性,但这个指针也会对此类资源的访问速度产生很大影响。使用记录在节点之间传输工作数据。 - 对于直播启动节点,如果可以静态确定调度大小,则使用
NodeDispatchGrid指定尺寸,而不是将网格尺寸作为SV_DispatchGrid输入记录中的值。请记住,可以覆盖NodeDispatchGrid并根据屏幕分辨率和其他质量设置等某些运行时条件进行调整。 - 尽可能保持属性中指定的数字,例如
NodeMaxDispatchGrid和MaxRecords尽可能紧密。了解工作图形的各个节点的广播/聚合性质,并使用这种了解来确定工作大小估算的合适值。这应该有助于减少图形所需的背景内存大小。 - 考虑将节点输出标记为
MaxRecordsSharedWith属性。一个显而易见且常见的例子是,如果生产节点线程将一个输出记录写入其中一个子节点中。 - 尽早在着色器中输出节点记录,并使用
OutputComplete以标记完成。这有助于改善占用率。 - 首先简单地验证每个步骤是否正确,然后再添加代码以启动下一个节点。很容易出错,尤其是在请求输出记录时。由于工作图形是一项新功能,因此调试工具尚未达到最佳状态。
分析和调试工具
NVIDIA Nsight Graphics 为分析和调试图形应用程序提供全面支持。它公开渲染管线并可视化工作负载,帮助您识别和解决优化需求。
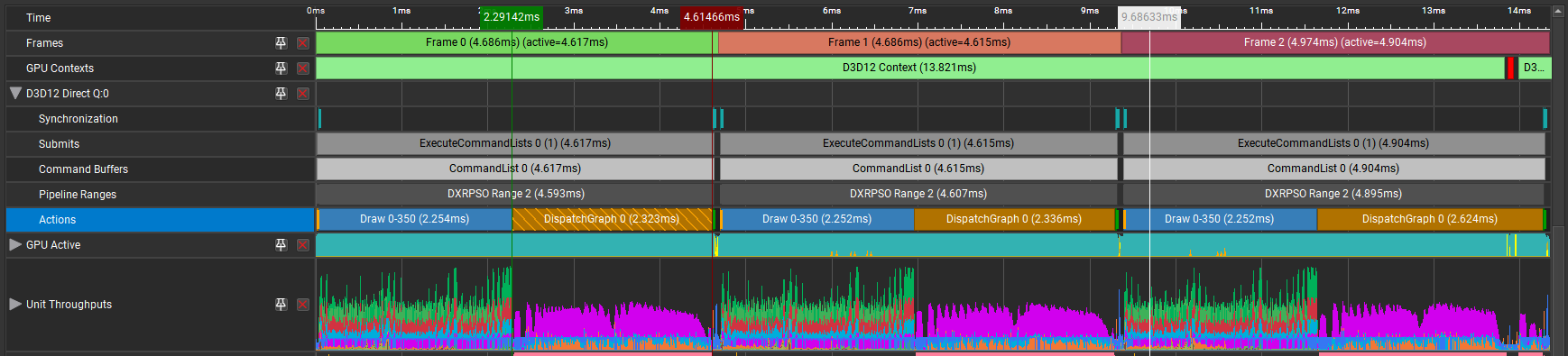
您可以在 Nsight Graphics 帧调试器中检查 D3D12 工作图,该调试器可以逐帧检查 GPU 进程。通过捕获和重放工作图,帧调试器可以显示 API 参数、资源绑定和内存缓冲区的内容。
函数 DispatchGraph 将工作图形推送到 GPU,并协调图形结构中任务的执行方式,从而实现高效并行性和任务依赖性管理。此功能在 Nsight Graphics GPU Trace 中以时间轴事件的形式显示,因此您可以查看 GPU 的性能指标。
未来方向
许多算法都涉及大量独立数据通过一系列步骤流动,并在各个步骤进行扩展。处理层次数据的算法是实现工作图的理想候选者。例如,从虚拟场景到可见区域,再到处理和转换网格,最后到三角形光栅化,这一过程可以在单个工作图中很好地实现。
尽管目前工作图形仅限于计算着色器,但可以在计算中甚至使用 内联光线追踪。随着工作图形添加向光栅化器提交三角形的支持,这应该不再成为问题。
工作图形迈出了迈向完全由 GPU 驱动的帧处理的巨大步骤。但是,一个工作图不可能表达整个帧的工作 (例如,剔除、光栅化 G 缓冲区、照明和后期处理)。虽然一个工作图可以表示多个帧的渲染步骤,但仍有一些操作无法在单个工作图中高效完成。操作时出现的问题包括:
- 在图形执行期间如何管理资源状态?
- 如何将三角形提交至硬件光栅化器?三角形光栅化后的工作图形是否可以继续运行?
- 如何表示多通道算法 (例如后处理链)?
直到这些问题得到解决,CPU 将继续在帧序列中发挥主导作用。现在,我们可以将更多的数据依赖性步骤完全移至 GPU,从而使 CPU 得以释放用于管理场景剔除和推送命令的所有可见对象的任务。因此,我们尚未达到 CPU 只提交一个调用DispatchGraph来绘制整个帧,但这个版本的工作图形有助于将更多部分的帧转换为 GPU 驱动,从而减少 CPU 会成为应用程序性能瓶颈的情况。
总结
本帖子探讨了一个具体的使用案例,该案例可以利用 Direct3D 12 中工作图形的功能来调整现有渲染算法。此外,我还讨论了关于工作图形的一些高级主题,包括性能注意事项和流式传输游戏引擎的操作。我还介绍了 NVIDIA Nsight Graphics 的最新版本中对工作图形的支持。如需了解构建和运行工作图形所需的所有详细信息,请访问 NVIDIAGameWorks/donut_examples 项目在 GitHub 上提供。
致谢
感谢 NVIDIA Nsight Graphics 团队的 Avinash Baliga 和 Robert Jensen 对本文的贡献。



