

今天在旧金山的一个 AI 会议上, NVIDIA 发布了 Jetson TX2 和 Jetpack3 . 0AI SDK 。 Jetson 是世界领先的低功耗嵌入式平台,为所有边缘设备提供服务器级 AI 计算性能。 Jetson TX2 具有集成的 256 核 NVIDIA Pascal GPU 、十六进制内核 ARMv8 64 位 CPU 复合体和 8GB LPDDR4 内存和 128 位接口。 CPU 复合物结合了双核心的丹佛 2 号和四核臂 Cortex-A57 。图 1 所示的 Jetson TX2 模块适合于 50 x 87 毫米、 85 克和 7 . 5 瓦的小尺寸、重量和功率(交换)占用空间。
物联网( IoT )设备通常充当简单的中继数据网关。他们依靠云连接来完成繁重的工作和数字运算。边缘计算是一种新兴的范式,它使用本地计算来实现数据源的分析。 TX2 具有超过 TFLOP / s 的性能,非常适合将高级人工智能部署到互联网连接较差或昂贵的远程现场。 Jetson TX2 还为需要任务关键型自治的智能机器提供近实时响应和最小延迟密钥。
Jetson TX2 基于 16nm NVIDIA Tegra “ Parker ”系统片上系统( SoC )(图 2 显示了一个框图)。 Jetson TX2 在 深度学习 推理方面的能效是其前代产品 Jetson TX1 的两倍,并提供比 Intel Xeon 服务器 CPU 更高的性能。效率的提高重新定义了将先进的人工智能从云端扩展到边缘的可能性。
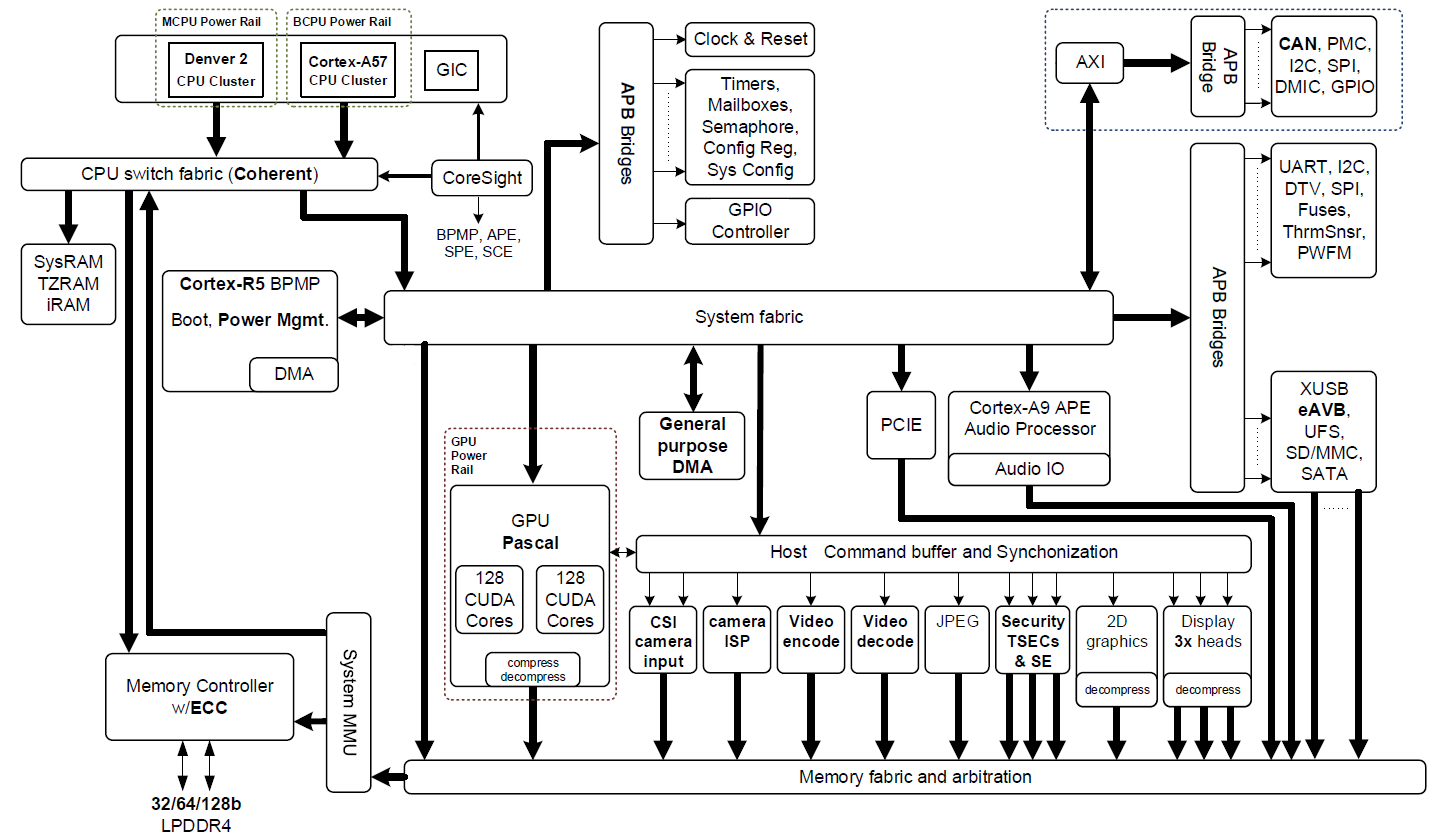
Jetson TX2 有多个多媒体流引擎,通过减轻传感器采集和分发的负担,使其 Pascal GPU 能够获得数据。这些多媒体引擎包括六个专用的 MIPI CSI-2 摄像头端口,每通道提供高达 2 . 5gb / s 的带宽和 1 . 4gb / s 的双图像服务处理器( ISP )处理,以及支持 H . 265 、每秒 4k60 帧的视频编解码器。
Jetson TX2 使用 NVIDIA cuDNN 和 TensorRT 库加速尖端深度神经网络( DNN )架构,并支持 递归神经网络 、 长短期记忆网络 和在线 强化学习 。它的双 CAN 总线控制器使自动驾驶仪集成到控制机器人和无人机,这些机器人和无人机使用 DNN 感知周围的世界,并在动态环境中安全运行。 Jetson TX2 的软件通过 NVIDIA 的 喷气背包 3 . 0 和 Linux for Tegra ( L4T ) Board Support Package ( BSP )提供。
表 1 比较了 Jetson TX2 与上一代 Jetson TX1 的特性。
| NVIDIA Jetson TX1 |
NVIDIA Jetson TX2 |
|
|---|---|---|
| CPU | Arm Cortex-A57 (quad-core) @ 1.73GHz | Arm Cortex-A57 (quad-core) @ 2GHz + NVIDIA Denver2 (dual-core) @ 2GHz |
| GPU | 256-core Maxwell @ 998MHz | 256-core Pascal @ 1300MHz |
| Memory | 4GB 64-bit LPDDR4 @ 1600MHz | 25.6 GB/s | 8GB 128-bit LPDDR4 @ 1866Mhz | 59.7 GB/s |
| Storage | 16GB eMMC 5.1 | 32GB eMMC 5.1 |
| Encoder* | 4Kp30, (2x) 1080p60 | 4Kp60, (3x) 4Kp30, (8x) 1080p30 |
| Decoder* | 4Kp60, (4x) 1080p60 | (2x) 4Kp60 |
| Camera† | 12 lanes MIPI CSI-2 | 1.5 Gb/s per lane | 1400 megapixels/sec ISP | 12 lanes MIPI CSI-2 | 2.5 Gb/sec per lane | 1400 megapixels/sec ISP |
| Display | 2x HDMI 2.0 / DP 1.2 / eDP 1.2 | 2x MIPI DSI | |
| Wireless | 802.11a/b/g/n/ac 2×2 867Mbps | Bluetooth 4.0 | 802.11a/b/g/n/ac 2×2 867Mbps | Bluetooth 4.1 |
| Ethernet | 10/100/1000 BASE-T Ethernet | |
| USB | USB 3.0 + USB 2.0 | |
| PCIe | Gen 2 | 1×4 + 1 x1 | Gen 2 | 1×4 + 1×1 or 2×1 + 1×2 |
| CAN | Not supported | Dual CAN bus controller |
| Misc I/O | UART, SPI, I2C, I2S, GPIOs | |
| Socket | 400-pin Samtec board-to-board connector, 50x87mm | |
| Thermals‡ | -25°C to 80°C | |
| Power†† | 10W | 7.5W |
| Price | $299 at 1K units | $399 at 1K units |
两倍的性能,两倍的效率
在我的 在 JetPack 2 . 3 上发布 中,我演示了 NVIDIA TensorRT 如何提高 Jetson TX1 深度学习推理性能,效率比桌面类 CPU 高 18 倍。 TensorRT 通过使用 graph 优化、内核融合、 半精度浮点计算( FP16 ) 和架构自动调整来优化生产网络以显著提高性能。除了利用 Jetson TX2 对 FP16 的硬件支持之外, NVIDIA TensorRT 还能够批量同时处理多个图像,从而获得更高的性能。
Jetson TX2 和 JetPack 3 . 0 将 Jetson 平台的性能和效率提升到一个全新的水平,为用户提供了在 AI 应用中获得两倍或最多两倍于 Jetson TX1 性能的选项。这种独特的功能使 Jetson TX2 成为边缘需要高效人工智能的产品和边缘附近需要高性能的产品的理想选择。 Jetson TX2 还与 Jetson TX1 兼容,为使用 Jetson TX1 设计的产品提供了一个简单的升级机会。
为了测试 Jetson TX2 和 JetPack 3 . 0 的性能,我们将其与服务器类 CPU 、 Intel Xeon E5-2690 v4 进行比较,并使用 GoogLeNet 深度图像识别网络测量深度学习推理吞吐量(每秒图像数)。如图 3 所示, Jetson TX2 在低于 15W 的功率下运行的性能优于在接近 200W 的情况下运行的 CPU ,从而使数据中心级的 AI 能力处于边缘。
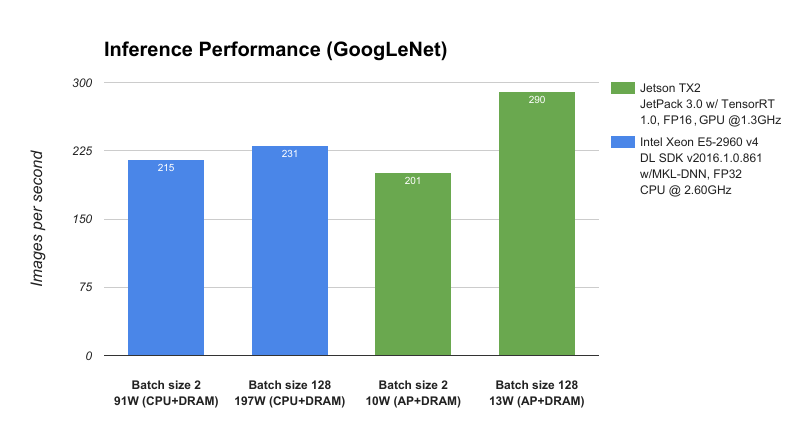
Jetson TX2 的卓越 AI 性能和效率源于新的 Pascal GPU 架构和动态能量配置文件( Max-Q 和 Max-P )、 JetPack 3 . 0 附带的优化深度学习库以及大内存带宽的可用性。
Max-Q 和 Max-P
Jetson TX2 设计用于 7 . 5W 功率下的峰值处理效率。这一性能水平被称为 Max-Q ,代表功率/吞吐量曲线的峰值。模块上的每个组件(包括电源)都经过优化,以提供最高的效率。 GPU 的最大 Q 频率为 854 MHz ,而 Arm A57 CPU 的最大 Q 频率为 1 . 2 GHz 。 JetPack 3 . 0 中的 L4T BSP 包括用于将 Jetson TX2 设置为 Max-Q 模式的预设平台配置。 Jetpack3 . 0 还包括一个名为 nvpmodel 的新命令行工具,用于在运行时切换配置文件。
虽然动态电压和频率缩放( DVFS )允许 Jetson TX2 的 Tegra “ Parker ” SoC 在运行时根据用户负载和功耗调整时钟速度,但 Max-Q 配置设置了时钟上限,以确保应用程序仅在最有效的范围内运行。表 2 显示了在运行 GoogLeNet 和 AlexNet 深度学习基准测试时, Jetson TX2 和 Jetson TX1 的性能和能效。在 Max-Q 模式下运行的 Jetson TX2 的性能与在最大时钟频率下运行的 Jetson TX1 的性能相似,但只消耗一半的功率,因此能量效率提高了一倍。
尽管功率预算有限的大多数平台将从 Max-Q 行为中受益最大,但其他平台可能更喜欢使用最大时钟来达到峰值吞吐量,尽管这样做会导致更高的功耗和更低的效率。 DVFS 可以配置为在其他时钟速度范围内运行,包括欠时钟和超频。 Max-P 是另一种预设平台配置,可在不到 15W 的时间内实现最大系统性能。启用 Arm A57 群集或启用丹佛 2 群集时, GPU 的 Max-P 频率为 1122 MHz , CPU 的 Max-P 频率为 2 GHz ,当两个群集都启用时, Max-P 频率为 1 . 4 GHz 。您还可以创建具有中频目标的自定义平台配置,以便在应用程序的峰值效率和峰值性能之间实现平衡。下表 2 显示了从 Max-Q 到 Max-P 的性能如何提高,以及如何在效率逐渐降低的情况下提高 GPU 时钟频率。
| NVIDIA Jetson TX1 |
NVIDIA Jetson TX2 |
||||
|---|---|---|---|---|---|
| Max Clock (998 MHz) |
Max-Q (854 MHz) |
max-P (1122 MHz) |
Max Clock (1302 MHz) |
||
|
GoogLeNet |
Perf | 141 FPS | 138 FPS | 176 FPS | 201 FPS |
| Power (AP+DRAM) | 9.14 W | 4.8 W | 7.1 W | 10.1 W | |
| Efficiency | 15.42 | 28.6 | 24.8 | 19.9 | |
| GoogLeNet batch=128 |
Perf | 204 FPS | 196 FPS | 253 FPS | 290 FPS |
| Power (AP+DRAM) |
11.7 W | 5.9 W | 8.9 W | 12.8 W | |
| Efficiency | 17.44 | 33.2 | 28.5 | 22.7 | |
| AlexNet batch=2 |
Perf | 164 FPS | 178 FPS | 222 FPS | 250 FPS |
| Power (AP+DRAM) | 8.5 W | 5.6 W | 7.8 W | 10.7 W | |
| Efficiency | 19.3 | 32 | 28.3 | 23.3 | |
| AlexNet batch=128 |
Perf | 505 FPS | 463 FPS | 601 FPS | 692 FPS |
| Power (AP+DRAM) | 11.3 W | 5.6 W | 8.6 W | 12.4 W | |
| Efficiency | 44.7 | 82.7 | 69.9 | 55.8 | |
Jetson TX2 执行 GoogLeNet 推理的速度高达 33 . 2 图像/秒/瓦,几乎是 Jetson TX1 的两倍,效率比 Intel Xeon 高出近 20 倍。
端到端人工智能应用
两个 Pascal 流式多处理器( SMs )是 Jetson TX2 高效性能的重要组成部分,每个处理器有 128 个 CUDA 核。 Pascal GPU 架构 提供了重大的性能改进和电源优化。 TX2 的 CPU 复合体包括双核 7 路超标量 NVIDIA Denver 2 ,用于动态代码优化的高单线程性能,以及用于多线程处理的四核 Arm Cortex-A57 。
相干的丹佛 2 和 A57 CPU 都有一个 2MB 的二级缓存,并通过由 NVIDIA 设计的高性能互连结构进行连接,以在异构多处理器( HMP )环境中实现两个 CPU 的同时操作。一致性机制允许根据动态性能需求自由地对任务进行 MIG 评级,以减少开销的方式有效地利用 CPU 核心之间的资源。
Jetson TX2 是自主机端到端 AI 管线的理想平台。 Jetson 有线传输实时高带宽数据:在处理 GPU 数据后,可同时接收多个传感器的数据,执行媒体解码/编码、组网和低级命令控制协议。图 4 显示了使用高速接口阵列(包括 CSI 、 PCIe 、 USB3 和千兆以太网)连接传感器的常见管道配置。 CUDA 预处理和后处理阶段通常包括色域转换(成像 DNN 通常使用 BGR 平面格式)和对网络输出的统计分析。
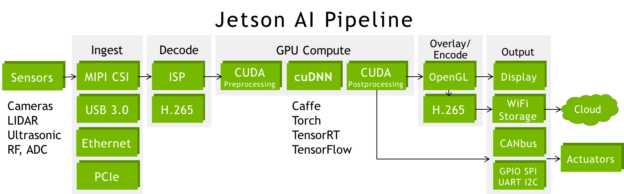
由于内存和带宽是 Jetson TX1 的两倍, Jetson TX2 能够同时捕获和处理额外的高带宽数据流,包括立体摄像机和 4K 超高清输入和输出。通过管道,深度学习和计算机视觉将来自不同来源和光谱域的多个传感器融合在一起,从而增强了自动导航期间的感知能力和态势感知能力。
Jetson TX2 开发工具包入门
首先, NVIDIA 为 Jetson TX2 开发工具包 提供了一个参考的小型 ITX 载体板( 170 毫米 x 170 毫米)和一个 500 万像素的 MIPI CSI-2 相机模块。开发工具包包括文档和设计示意图以及 JetPack-L4T 的免费软件更新。图 5 显示了开发工具包,显示了 Jetson TX2 模块和标准 PC 连接,包括 USB3 、 HDMI 、 RJ45 千兆以太网、 SD 卡和 PCIe x4 插槽,这使得 Jetson 的应用程序开发更加容易。

要超越开发到定制部署平台,您可以修改开发工具包载体板和相机模块的参考设计文件,以创建自定义设计。或者, Jetson 生态系统合作伙伴为部署 Jetson TX1 和 Jetson TX2 模块提供现成的解决方案,包括微型载体、外壳和摄像头。 NVIDIA Developer Forums 为 Jetson 建造者和 NVIDIA 工程师社区提供技术支持和协作之家。表 3 列出了主要文件和有用的资源。
| Embedded Developer Portal : developer.nvidia.com/embedded | |
|---|---|
| Jetson TX2 Module Datasheet | Jetson TX2 OEM Design Guide |
| Jetson TX2 Thermal Design Guide | Jetson Developer Kit Carrier Specification |
| Jetson TX1-TX2 Interface Comparison and Migration | Jetson Developer Kit Carrier Design Files |
| L4T Accelerated GStreamer Guide | Jetson Camera Module Design Guide |
| Jetson TX2 Developer Forums | Jetson TX2 Wiki – eLinux.org/Jetson_TX2 |
Jetson TX2 开发工具包可通过 NVIDIA 在线商店 以 599 美元的价格预订。 3 月 14 日开始在北美和欧洲发货,其他地区也将陆续发货。 Jetson TX2 教育折扣 还提供: 299 美元用于学术机构的附属机构。 NVIDIA 已将 Jetson TX1 开发工具包的价格降至 499 美元。
JetPack 3 . 0 SDK 开发包
最新的 NVIDIA JetPack 3.0 支持 Jetson TX2 使用业界领先的 AI 开发工具和硬件加速 API(见表4),包括 NVIDIA CUDA 工具包版本8.0、cuDNN、TensorRT、VisionWorks、GStreamer 和 OpenCV,这些都是在 Linux 内核v4.4、L4T R27.1 BSP 和 Ubuntu 16.04 LTS 的基础上构建的。Jetpack3.0 包括用于交互式分析和调试的Tegra系统探查器和Tegra图形调试器工具。Tegra多媒体API包括低级摄像头捕获和Video4Linux2(V4L2)编解码器接口。在闪烁的同时,JetPack会自动使用所选的软件组件配置Jetson TX2,从而实现开箱即用的完整环境
| NVIDIA JetPack 3.0 — Software Components | |
|---|---|
| Linux kernel 4.4 | Ubuntu 16.04 LTS aarch64 |
| CUDA Toolkit 8.0.56 | cuDNN 5.1.10 |
| TensorRT 1.0 GA | GStreamer 1.8.2 |
| VisionWorks 1.6 | OpenCV4Tegra 2.4.13-17 |
| Tegra System Profiler 3.7 | Tegra Graphics Debugger 2.3 |
| Tegra Multimedia API | V4L2 Video Codec Interfaces |
Jetson 是一个高性能的嵌入式解决方案,用于部署 Caffe 、 Torch 、 Theano 和 TensorFlow 等深度学习框架。这些和许多其他深度学习框架已经将 NVIDIA 的 cuDNN 库与 GPU 加速集成在一起,并且只需要很少的 MIG 定量工作就可以在 Jetson 上部署。 KZV3 的软件和应用程序通常在云计算中心和服务器上无缝部署[KZV3]软件和应用程序。
还有两天就要演示了
NVIDIA Two Days to a Demo 是一个帮助任何人开始部署深度学习的倡议。 NVIDIA 提供计算机视觉原语,包括图像识别、目标检测+定位和分割,以及用 DIGITS 训练的 神经网络 模型。您可以将这些网络模型部署到 Jetson 上,以便使用 NVIDIA TensorRT 进行有效的深度学习推断。“两天一个演示”提供了示例流式应用程序,以帮助您体验实时摄像头提要和真实世界的数据,如图 6 所示。

两天的演示代码是 在 GitHub 上提供 ,以及易于遵循的测试和重新训练网络模型的分步指导,为您的定制主题扩展了视觉原语。这些教程演示了数字工作流的强大概念,向您展示了如何在云端或 PC 机上迭代地训练网络模型,然后将其部署到 Jetson 上进行运行时推断和进一步的数据收集。
通过使用预先训练的网络和转移学习,此工作流使您可以轻松地使用自定义对象类来定制基础网络以满足您的任务。一旦一个特定的网络体系结构被证明适用于某个原语或应用程序,那么针对特定的用户定义的应用程序(例如包含新对象的训练数据)对其进行重新调整或重新训练通常会非常容易。
正如在 这个平行的 博客文章中所讨论的, NVIDIA 在数字 5 上增加了对分段网络的支持,现在可以在 Jetson TX2 上使用,演示时间为两天。分割原语使用完全卷积 Alexnet 架构( FCN-Alexnet )对视野中的单个像素进行分类。由于分类发生在像素级,与图像识别中的图像级不同,分割模型能够提取对周围环境的全面了解。这克服了自主导航机器人和无人机所面临的重大障碍,这些机器人和无人机可以直接使用分割区域进行路径规划和障碍物回避。
分段制导的自由空间探测使地面车辆能够安全地在地面上导航,而无人机则通过视觉识别和跟踪地平线和天空平面,以避免与障碍物和地形发生碰撞。感知和避免功能是智能机器与环境安全交互的关键。在 Jetson TX2 上使用 TensorRT 处理要求计算量大的分段网络,对于避免事故所需的低响应延迟至关重要。

两天的演示包括一个使用 FCN Alexnet 的空中分割模型(图 7 ),以及相应的 horizon 第一人称视图( FPV )数据集。空中分割模型可作为无人机和自主导航的范例。您可以使用自定义数据轻松扩展模型,以识别用户定义的类,如着陆平台和工业设备。一旦以这种方式增强,你就可以把它部署到装备了 Jetson 的无人机上,比如 Teal 和 Aerialtronics 的无人机。
为了鼓励开发更多的自主飞行控制模式,我在 GitHub 上发布了空中训练数据集、分段模型和工具。 NVIDIA Jetson TX2 和 Two Days to a Demo 使在该领域开始使用先进的深度学习解决方案比以往任何时候都更容易。
Jetson 生态系统
Jetson TX2 的模块化外形使其能够部署到各种环境和场景中。 NVIDIA 的开源参考载波设计来自于 Jetson TX2 开发工具包,为缩小或修改单个项目需求的设计提供了一个起点。一些小型化的载体与 Jetson 模块本身具有相同的 50x87mm 的占地面积,从而实现了紧凑的组装,如图 8 所示。使用 NVIDIA 提供的文档和设计辅助资料,或尝试现成的解决方案。今年 4 月, NVIDIA 将推出 Jetson TX1 和 TX2 模块,价格分别为 299 美元和 399 美元,数量为 1000 台或更多。

生态系统合作伙伴{ ConnectTech ® Auvidea ®提供与 Jetson TX1 和 TX2 共享插座兼容的可部署微型载体和外壳,如图 8 所示。 Image partners & 豹纹成像 ® 山脊跑 提供摄像头和多媒体支持。加固专家 阿巴科系统 ↓ 沃尔夫先进技术 ®为在恶劣环境下操作提供 MIL 规范的资质。

除了用于部署到野外的紧凑型载体和外壳外, Jetson 的生态系统覆盖范围超出了典型的嵌入式应用。 Jetson TX2 的多核 Arm / GPU 体系结构和卓越的计算效率也让高性能计算( HPC )行业备受关注。高密度 1U 机架式服务器现已提供万兆以太网和多达 24 个 Jetson 模块。图 9 显示了一个可伸缩阵列服务器的示例。 Jetson 的低功耗和被动冷却对于轻量级、可扩展的云任务(包括低功耗的 web 服务器、多媒体处理和分布式计算)很有吸引力。视频分析和代码转换后端通常与部署在现场的智能摄像机和物联网设备上的 Jetson 配合工作,可以从 Jetson TX2 增加的每个处理器支持的同步数据流和视频编解码器的比率中获益。
AI 在边缘
Jetson TX2 无与伦比的嵌入式计算能力将尖端 DNN 和下一代人工智能带到板上边缘设备上。 Jetson TX2 提供服务器级的高能效性能。它的原始深度学习性能比 Intel Xeon 高出 1 . 25 倍,计算效率提高了近 20 倍。 Jetson 紧凑的占地面积、计算能力和具有深度学习功能的 JetPack 软件堆栈使开发人员能够使用 AI 解决 21 世纪的挑战。今天就开始使用 Jetson TX2 部署您自己的高级 AI 。 Preorders 可在 3 月 14 日前提供,或在线申请 学术折扣 。 NVIDIA 的 嵌入式开发人员门户 有更多信息。





