
数据是模型可解释性的核心。可解释人工智能( XAI )是一个快速发展的领域,旨在深入了解人工智能算法的复杂决策过程。
在人工智能对个人生活有重大影响的领域,如信用风险评分,管理者和消费者都有权要求深入了解这些决策。领先的金融机构已经在利用 XAI 验证其模型。同样,监管机构也要求深入了解金融机构的算法环境。但在实践中如何做到这一点呢?
潘多拉的封闭盒子
人工智能越先进,对可解释性来说,数据就越重要。
现代的 ML 算法有集成方法和深度学习,即使没有数百万个模型参数,也会产生数千个。当应用于实际数据时,如果不看到它们的实际作用,就不可能掌握它们。
甚至在培训数据敏感的情况下,广泛访问数据的必要性也是显而易见的。用于信用评分和保险定价的金融和医疗数据是人工智能中使用最频繁、但也是最敏感的数据类型。
这是一个相互矛盾的难题:你想要数据得到保护,你想要一个透明的决策。
可解释的 AI 需要数据
那么,这些算法如何变得透明呢?你如何判断机器做出的模型决策?考虑到它们的复杂性,披露数学模型、实现或完整的训练数据并不能达到目的。
相反,您必须通过观察各种实际案例中的决策来探索系统的行为,并探索其对修改的敏感性。这些基于示例的假设探索有助于我们理解是什么驱动了模型的决策。
这种简单而强大的概念,即在给定输入数据变化的情况下,系统地探索模型输出的变化,也称为 local interpretability ,可以在域和 model-agnostic 按比例 中执行。因此,同样的原则可以应用于帮助解释信用评分系统、销售需求预测、欺诈检测系统、文本分类器、推荐系统等。
然而,像 SHAP 这样的局部可解释性方法不仅需要访问模型,还需要访问大量具有代表性和相关的数据样本。
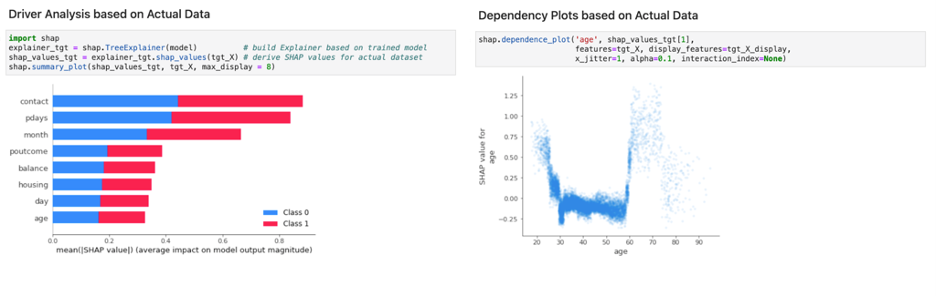
图 1 显示了一个在模型上进行的基本演示,该演示预测了客户对金融行业内营销活动的反应。查看相应的 Python 调用可以发现需要经过训练的模型,以及执行这些类型分析的代表性数据集。然而,如果该数据实际上是敏感的,并且无法被 AI 模型验证器 访问,该怎么办?
用于跨团队扩展 XAI 的合成数据
在人工智能采用的早期,通常是同一组工程师开发模型并对其进行验证。在这两种情况下,他们都使用了真实的生产数据。
考虑到算法对个人的现实影响,现在越来越多的人认识到,独立小组应该检查和评估模型及其影响。理想情况下,这些人会从工程和非工程背景中提出不同的观点。
与外部审计师和认证机构签订合同,以建立额外的信心,确保算法是公平、公正和无歧视的。然而,隐私问题和现代数据保护法规(如 GDPR )限制了对代表性验证数据的访问。这严重阻碍了模型验证的广泛开展。
幸运的是,模型验证可以使用高质量的人工智能生成的 synthetic data 来执行,它可以作为敏感数据的高度准确、匿名的替代品。例如, AI 的 综合数据平台 主要使组织能够以完全自助、自动化的方式生成合成数据集。
图 2 显示了使用合成数据对模型执行的 XAI 分析。比较图 1 和图 2 时,结果几乎没有任何明显的差异。同样的见解和检查也可以通过利用 AI 的隐私安全合成数据来实现,这最终使真正的协作能够在规模和连续的基础上执行 XAI 。
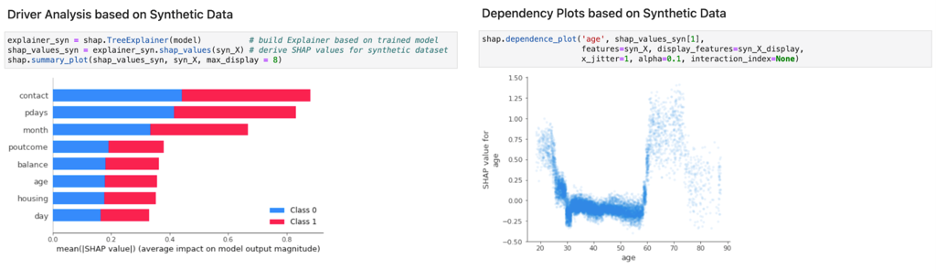
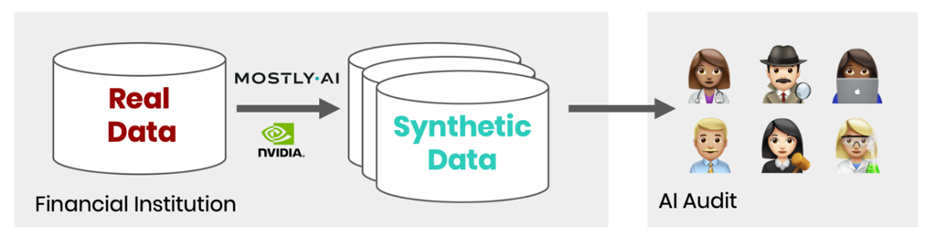
图 3 显示了跨团队扩展模型验证的过程。组织在其受控的计算环境中运行最先进的合成数据解决方案。它不断生成其数据资产的合成副本,可以与内部和外部 AI 验证器的不同团队共享。
使用 GPU 扩展到真实数据量
GPU 加速的库,如 RAPIDS 和 Plotly ,能够以实际遇到的实际用例所需的规模进行模型验证。这同样适用于生成合成数据,其中以 AI 为动力的合成解决方案(主要是 AI )可以通过在全栈加速计算平台上运行而受益匪浅。有关更多信息,请参阅 加速信用风险管理的可信 AI 。
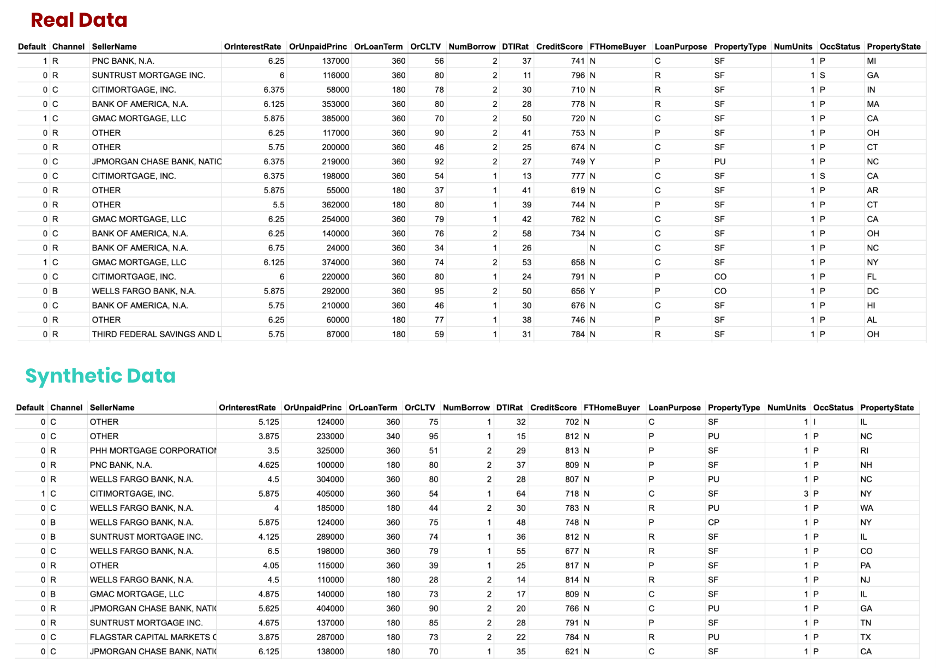
为了证明这一点,我们参考了房利美(Fannie Mae,FNMA)发布的抵押贷款数据集,目的是【VZX19】。我们首先生成一个具有统计代表性的训练数据合成副本,由数千万个合成贷款组成,由几十个合成属性组成(图4)。
所有数据都是人工创建的,没有一条记录可以链接回原始数据集中的任何实际记录。然而,数据的结构、模式和相关性被忠实地保留在合成数据集中。
这种捕获数据多样性和丰富性的能力对于模型验证至关重要。该过程旨在验证模型行为,不仅针对占主导地位的多数阶级,还针对人口中代表性不足和最脆弱的少数群体。
给定生成的合成数据,然后可以使用 GPU 加速的 XAI 库来计算感兴趣的统计信息,以评估模型行为。
例如,图 5 显示了 SHAP 值的并列比较:贷款拖欠模型在真实数据上解释,在合成数据上解释之后。通过使用高质量的合成数据作为敏感原始数据的替代品,可以可靠地得出关于该模型的相同结论。
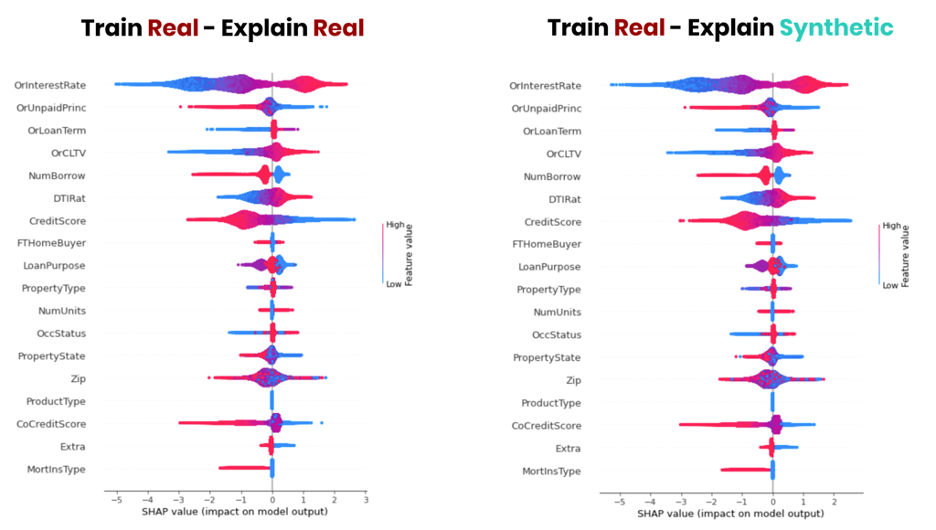
图 5 显示,合成数据可以作为解释模型行为的实际数据的安全替代品。
此外,合成数据生成器生成任意数量新数据的能力使您能够显著改进较小组的模型验证。
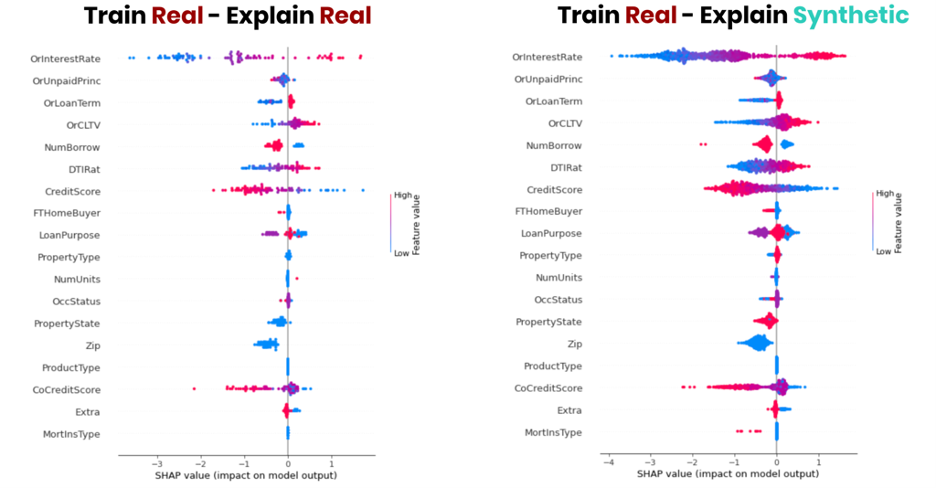
图 6 显示了数据集中特定邮政编码的 SHAP 值的并排比较。虽然原始数据在给定地理位置的贷款不到 100 笔,但我们利用 10 倍的数据量来检查该区域的模型行为,从而实现更详细和更丰富的见解。
使用合成样品进行单独水平检验
虽然汇总统计和可视化是分析一般模型行为的关键,但我们对模型的理解还可以通过逐个检查单个样本获得更多好处。
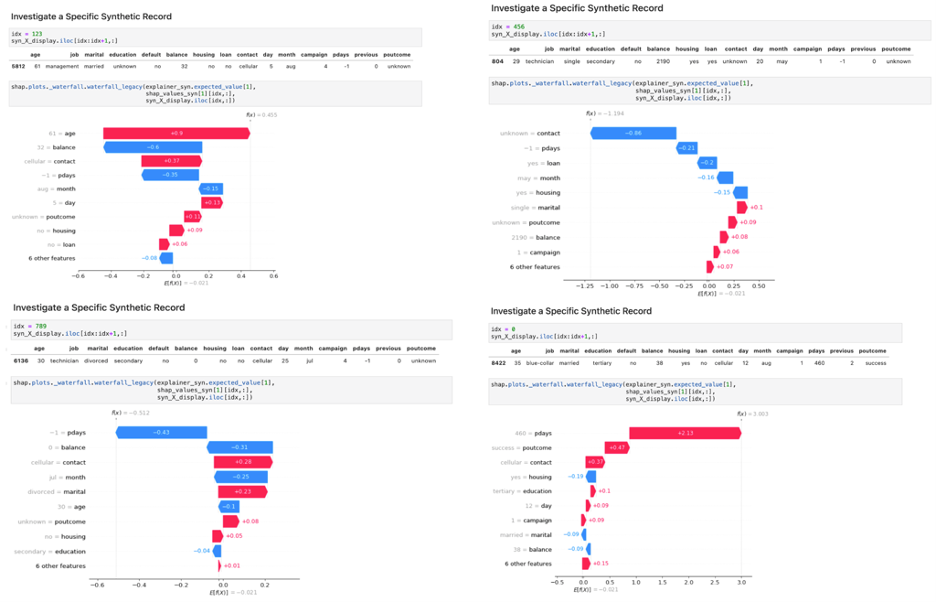
XAI 工具揭示了多个信号对最终模型决策的影响。只要合成数据真实且具有代表性,这些案例不一定是实际案例。
图 7 显示了四个随机生成的合成案例,以及它们的最终模型预测和每个输入变量的相应分解。这使您能够在不暴露任何个人隐私的情况下,深入了解对无限潜在案例的模型决策有多大影响的因素和方向。
利用合成数据进行有效的 AI 治理
人工智能驱动的服务越来越多地出现在私营和公共部门,在我们的日常生活中发挥着越来越大的作用。然而,我们只是在人工智能治理的黎明。
虽然像欧洲提议的人工智能法案这样的法规需要时间才能体现出来,但开发人员和决策者今天必须负责任地采取行动,并采用 XAI 最佳实践。合成数据支持广泛的协作环境,而不会危及客户的隐私。它是一个强大、新颖的工具,可以支持开发和治理公平、健壮的人工智能。
有关银行业中 AI 可解释性的更多信息,请参阅以下参考资料:
- 点播网络研讨会: 利用合成数据加快人工智能在银行业的应用,以实现隐私、公平和 XAI
- GTC session: 金融服务中的可解释人工智能:以数据为中心的方法



