
GPU 驱动的渲染一直是许多游戏应用程序的主要目标。它能够提高处理大型虚拟场景的可扩展性,并减少 CPU 对游戏性能的瓶颈。
除了在 GPU 上运行游戏逻辑之外,我认为 GPU 驱动渲染的巅峰时刻就是 CPU 只发送新帧的摄像头信息,而 GPU 则负责其余工作,直到屏幕上显示的最终像素。
NVIDIA Omniverse 平台已经对 Direct3D 12 (D3D12) API 进行了改进,包括支持 ExecuteIndirect、不受限制的资源数组 和 ResourceDescriptorHeap。这些功能增强了平台的性能和灵活性,为开发者提供了更多的创作空间。
工作图形是我很期待讨论的另一个功能。工作图形提供了一种编程范式,允许 GPU 随时生成自己的工作。这为解决一些知名游戏引擎问题提供了解决方案,并开辟了新的创意思路。
本文介绍了工作图的高级概念:结构、启动模式和数据流。我将介绍如何使用 HLSL 编写工作图,以及从 CPU 启动工作图的步骤。如要充分利用本文,您应该熟悉以下内容:
- D3D12 API
- 编写和编译计算着色器
ExecuteIndirect和光线追踪 API
请注意,工作图形在 NVIDIA Ampere 架构 和 NVIDIA Ada Lovelace 架构 上需要 NVIDIA 显示驱动程序版本 551.76 或更高版本,可以通过 NVIDIA 驱动程序下载 获取。
工作图形概述
适用于 D3D12 的 Shader Model 6.8 以及许多其他功能,标志着工作图形的正式发布。名称中的“图形”一词很好地适应了其定义:一个由边连接的节点集合。在工作图形中,节点执行任务 (“工作”) 并通过图形边传递数据给其他节点。
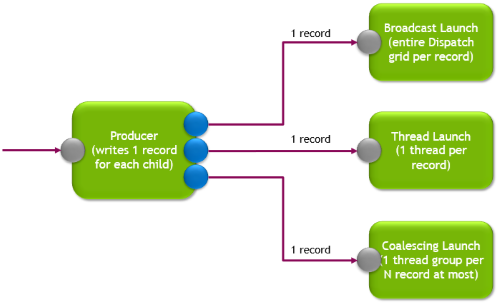
但是节点执行的工作是什么?节点执行的命令是什么?Dispatch呼叫?一个线程运行某种着色器?或者可能是一组线程运行相同的着色器?
答案是,上述所有内容。每个节点都有一个在程序员选择的特定配置中启动的着色器。这种配置或启动模式可以是一个完整的分配网格 (广播启动) 或计算线程 (线程启动)。请注意,线程启动工作可以汇集到一个可能的浪潮中运行,但每个线程仍然独立于其他线程。
通过选择目标节点并将数据传递给它来实现与其他节点的连接,这类似于通常所说的继续图形术语。目标节点接收数据并在其调用者的范围之外运行。此系统没有堆栈,只有从图形顶部到底部的数据流。
数据单元,即记录,驱动整个工作图的执行。要启动一个节点,必须为其写入记录。然后在选定的启动模式中启动节点,并使用该记录作为输入。记录是由生产者填充的数据包结构。生产者可以是 CPU 的命令 DispatchGraph 或工作图中的任何节点。节点消耗记录可以视为子生产者节点。
工作图形新功能
如前所述,D3D12 已公开功能,以帮助实现 GPU 驱动的渲染。本节重点介绍了工作图形引入的新功能与现有功能的比较。
动态着色器选择
工作图形中的每个节点都可以选择哪些子节点要运行。该决定由生成者着色器代码本身驱动。因此,可以根据前一个节点或工作负载中由 GPU 生成的信息做出决定。
另一方面,ExecuteIndirect只能按照启动时的状态工作,尤其是管线状态对象指定的着色器。需要根据 GPU 端数据启动不同着色器的应用只能发出一系列SetPipelineState和ExecuteIndirect或依赖效率低下的 Uber 着色器来覆盖某些潜在可能性。
隐式微型依赖关系模型
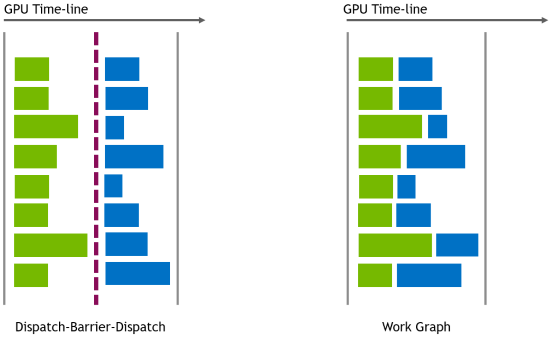
渲染一帧包括执行几个主要通道,例如深度、几何图形或照明通道。在每个通道中,数据通过并行处理,每个数据单元通过多个顺序操作。通常会在操作之间放置资源屏障,以确保前一个操作完成数据处理后再进行下一个操作。
工作图表通过生产节点将记录传递给子节点来表示这种依赖关系。子节点着色器仅在生产节点完成写入记录后才会运行,这表示数据已经准备就绪,可供子节点使用。请注意,工作图表生产节点-消费节点依赖关系的范围在于数据记录范围,而资源屏障则在于资源的所有访问。
与屏障相比,工作图依赖模型更精细。这可以翻译为更高的 GPU 占用率,因为依赖工作可以提前启动,而不是等待屏障完成。记录可以立即从生产者节点传输到消费者节点,而无需在算法步骤中完全清除Dispatch-ResourceBarrier序列。
图 2 展示了每种情况下的工作负载执行方式。在左侧,两个Dispatch分隔符,ResourceBarrier。每一行代表一个生产者线程组 (绿色) 和其消费者线程组 (蓝色)。在右侧,同样的工作负载使用工作图进行运行。
在 HLSL 中编写工作图
与光线追踪着色器类似,工作图形以计算着色器库的形式编写。一个 HLSL 文件可能包含图形中所有节点的代码,但也可以从不同来源构建图形,并在运行期间逐步连接这些节点。
以下 HLSL 代码片段演示了由两个节点 (生产者节点和消费者节点) 组成的非常简单的工作图。
struct RecordData { int myData; };
[Shader("node")]
[NodeLaunch("thread")]
[NodeIsProgramEntry]
void MyGraphRoot(
[MaxRecords(1)] NodeOutput MyChildNode)
{
ThreadNodeOutputRecords childNodeRecord =
MyChildNode.GetThreadNodeOutputRecords(1);
childNodeRecord.Get().myData = 123456;
childNodeRecord.OutputComplete();
}
[Shader("node")]
[NodeLaunch("broadcasting")]
[NodeDispatchGrid(1, 1, 1)]
[numthreads(8, 8, 1)]
void MyChildNode(
DispatchNodeInputRecord inputData,
uint2 dispatchThreadId : SV_DispatchThreadID)
{
int myData = inputData.Get().myData;
}
此代码片段展示了节点着色器基本上是带有一些附加声明的计算着色器。值得注意的是NodeLaunch属性,用于指定该节点的启动模式。图形中的根节点 (表示为NodeIsProgramEntry属性) 是线程启动节点。因此,对于每个输入记录,都会有一个计算着色器线程来处理它。根输入记录来自DispatchGraph调用命令列表。
着色器函数签名包含一个参数MyChildNode类型NodeOutput。此参数可用于生成MyChildNode节点的名称。因此,参数的名称必须与图形中的另一个节点的名称相匹配。
MyChildNode是一个广播发布节点。这意味着,向此节点推送一条记录会产生类似于Dispatch尺寸,该尺寸由此处的属性NodeDispatchGrid与您的 Omniverse 帐户关联的MyChildNode函数签名。
有关新语法和声明的详细信息,请参阅 HLSL 语法参考 中的工作图形部分。
CPU 端设置
启动工作图形需要 D3D12 中其他类型工作所需的相同步骤,具体如下:
- 执行特征支持检查
- 在离线或运行时编译着色器
- 加载着色器库并构建工作图形状态对象
- 分配背景内存
- 启动图形
功能支持检查
为了确保在目标设备上支持工作图形,必须调用 CheckFeaturesSupport 并检查 D3D12_FEATURE_DATA_D3D12_OPTIONS_21 结构中的 WorkGraphsTier 预训练模型。
编译着色器
工作图形需要将 HLSL 源代码编译为lib_6_8着色器目标。除了其他着色器类型使用的标准开关之外,无需向编译器传递任何特定要求。
加载着色器库
编译器的二进制文件必须加载并D3D12_STATE_OBJECT_DESC必须准备具备工作图形所需的所有部件。必须提供大量信息,包括:
- 要使用的 DXIL 库 (即预编译的着色器二进制文件)。
- 工作图形使用的根签名。
- 哪些节点组成图形 (所有节点或某个特定子集)。
- 覆盖已在着色器库中设置的某些属性 (如果需要)。这些覆盖可以使用运行时确定的值驱动工作图中的静态值。
分配背景内存
此外,图形还需要在执行期间使用辅助内存。在创建状态对象后,必须查询图形所需的辅助内存,并在启动图形之前进行分配。如果报告的辅助内存要求的最小大小不同于最大大小,则建议遵循最大大小,以实现图形执行的最佳性能。
启动图形
此步骤与启动计算着色器非常相似。命令列表必须处于良好状态,其中包括描述符缓冲区、根签名、根参数和描述符表。
启动图形需要调用SetProgram在命令列表中首先执行此调用。此调用指定要启动的图形、它的后盾内存,以及如果需要的其他启动标志。
一个重要的标志是D3D12_SET_WORK_GRAPH_FLAG_INITIALIZE.这个标志必须在工作图形首次使用其后备内存时传递。如果后备内存未被图形以外的其他内容使用,则后续启动可以省略此标志。
最后,调用DispatchGraph此时,可以为图形的根指定输入记录,这些记录可以从 CPU 或 GPU 显存提供。
参考示例代码的LoadWorkGraphPipelines和PopulateDeferredShadingWorkGraph函数显示和说明整个 CPU 端设置过程中的每个步骤。
使用工作图表表达算法
了解工作图如何运作以及它们的功能和局限性至关重要。借此了解,您可以选择任何算法,并决定如何以更高效的方式将其表示为工作图。
工作图形推动数据流和转换操作,即必须通过一系列步骤流动的独立数据,并且可能在流程中扩展,最终达到最终结果。
使用此版本的工作图形时需要考虑以下事项:
- 除 root 输入记录、具体数字或上限外,图形中的工作大小和潜在扩展必须指定。例如,广播启动节点必须使用固定的分配网格大小,或者为其提供上限。作为开发者,您必须能够从算法和其输入的潜在大小中获得这些数字。
- 节点只能使用一种输入记录类型。不允许使用多种输入记录类型。这意味着单个节点不能作为不同生产者的“join”目标。虽然可以通过手动实现此类“join”来绕过此问题,但我建议避免这种情况。此类“join”意味着数据记录在图形执行内存中停留,直到所有输入记录准备就绪,并且“join”目标可以启动。请注意,融合节点不适用于解决此问题,因为它们的启动条件不保证输入记录的数量,并且可能启动的数量较低。
- 图形中不能包含任何循环,唯一例外是节点可以循环到自身。
- 图形的深度不得超过 32 个节点。每个节点的最大自环数也会计入这个数字。
- 节点目前还不能生成绘图调用,但请记住,可以使用
TraceRayInline。 - 资源在执行工作图形期间无法转换到不同的状态。
总结
Direct3D 12 API 中的工作图形帮助解决了一些知名问题,并启发了新的创意想法。在本文中,我介绍了不同的启动节点,以及如何通过记录传递数据。我还讨论了工作图形的 HLSL 代码,以及从 CPU 启动工作图的步骤。最后,我介绍了此功能背后的心智模型,以及如何最好地将 GPU 算法映射到此版本的工作图。如需了解构建和运行工作图所需的所有详细信息,请访问 GitHub 的 NVIDIAGameWorks/donut_examples。
如需详细了解工作图形 (包括高级主题和案例研究),请参阅 Direct3D 12 中的工作图:延迟着色案例研究。



