这个 系列的第一篇文章 介绍了矢量搜索索引,解释了它们在实现广泛的重要应用中所起的作用,并使用了 RAFT 库。
在这篇文章中,我们深入探讨第 1 部分中提到的每种 GPU 加速索引方法,并简要解释了算法的工作原理,以及总结重要的微调参数。
然后,我们通过一个简单的端到端示例,用预训练的大型语言模型演示 RAFT 在问答问题上的 Python API,并在涉及同时传递给搜索算法的不同查询向量数量的几个不同场景下,将 RAFT 的算法与 HNSW 的性能进行比较。
此帖子提供:
- 可与 GPU 一起使用的矢量搜索索引算法概述
- 一个端到端的例子演示了使用 Python 在 GPU 上运行矢量搜索是多么容易
- GPU 上的矢量搜索与 CPU 上当前最先进的 HNSW 方法的性能比较
矢量搜索索引
使用矢量搜索时,矢量通常会转换为索引格式,该格式针对快速查找进行了优化。选择正确的索引算法很重要,因为它会影响索引构建和搜索时间。此外,每种不同的索引类型都有自己的一组参数,用于微调行为、权衡索引构建时间、存储成本、搜索质量和搜索速度。
当正确的索引算法与正确的参数设置配对时, GPU 上的矢量搜索为各种召回率提供了更快的构建和搜索时间。
IVF-Flat
由于它是最简单的索引类型,我们建议您从 IVF-Flat 算法 开始。在该算法中,一组训练向量首先被分割成一些聚类,然后被存储在由它们最近的聚类中心组织的 GPU 内存中。索引构建步骤比本文中介绍的其他算法更快,即使在大量簇的情况下也是如此。
为了搜索 IVF-Flat 索引,选择与每个查询向量最近的聚类,并根据这些最接近的聚类中的每个来计算 k 个最近邻居(k-NN)。因为 IVF-Flat 以原始形式存储向量,意味着没有压缩,它的优势是计算它搜索的每个簇内的精确距离。正如我们稍后在本文中所描述的,当搜索相同数量的最接近聚类时,这提供了一个优势,通常比 IVF-PQ 具有更高的召回率。当 GPU 内存可以容纳全量索引时,IVF-Flat 索引是一个很好的选择。
RAFT 的 IVF-Flat 索引包含几个参数,有助于权衡查询性能和准确性:
- 训练索引时,n_lists参数确定用于对训练数据集进行分区的簇的数量。
- 搜索参数n_probes确定要搜索的最近聚类的数量,以计算一组查询点的最近邻居。
一般来说,较少的探针数量会以召回为代价,导致搜索速度更快。当探测器的数量设置为列表的数量时,会计算出确切的结果。但是,在这种情况下,RAFT 的暴力搜索表现更佳。
IVF-PQ
当数据集变得太大而无法放在 GPU 上时,您可以通过使用 IVF-PQ 索引类型 来解决。与 IVF Flat 一样,IVF-PQ 将点划分为多个簇(也由 n_lists 参数指定)并搜索最近的聚类以计算最近的邻居(也由 n_probes 参数指定),但它使用一种称为 product quantization 的方法。
压缩索引最终允许在 GPU 上存储更多的矢量。压缩量可以通过调整参数来控制,我们稍后将对此进行描述,但更高级别的压缩可以以调用为代价提供更快的查找时间。IVF-PQ 是目前 RAFT 最具内存效率的矢量索引。
RAFT 的 IVF-PQ 提供了两个控制内存使用的参数:
- pq_dim 设置压缩向量的目标维度。
- pq_bits 设置压缩后每个矢量元素的位数。
我们建议将前者设置为 32 的倍数,而将后者限制在 4-8 位的范围内。默认情况下,RAFT 根据 pq_bits,但可以调整此值以降低每个矢量的内存占用面积。使用这些参数可以查看哪些设置最适合您,这很有用。
当使用大量压缩时,refinement step 可以通过在 IVF-PQ 索引中查询比所需数量更多的邻居,并计算对结果邻居的精确搜索,以将集合减少到最终期望的数量来执行。细化步骤需要主机内存上的原始未压缩数据集。
想要获取更多关于构建 IVF-PQ 索引的信息,以及深入的细节和建议,请参阅在 GitHub 存储库上的 RAFT IVF-PQ 完整指南 笔记本 。
CAGRA
CAGRA 是 RAFT 最新的、最先进的 ANN 指数。这是一种高性能的、 GPU 加速的、基于图的方法,专门针对小批量情况进行了优化,其中每次查找只包含一个或几个查询向量。与其他流行的基于图的方法一样,如分层可导航小世界图(HNSW)和 SONG,优化的 k-NN 图是在索引训练时构建的,具有各种质量,可以在合理的召回水平上产生有效的搜索。
CAGRA 通过首先从图中随机选择候选顶点,然后扩展或遍历这些顶点来计算到其子顶点的距离,并在搜索过程中存储最近的邻居来执行搜索(图 1)。每次遍历一组顶点时,它都会执行一次迭代。
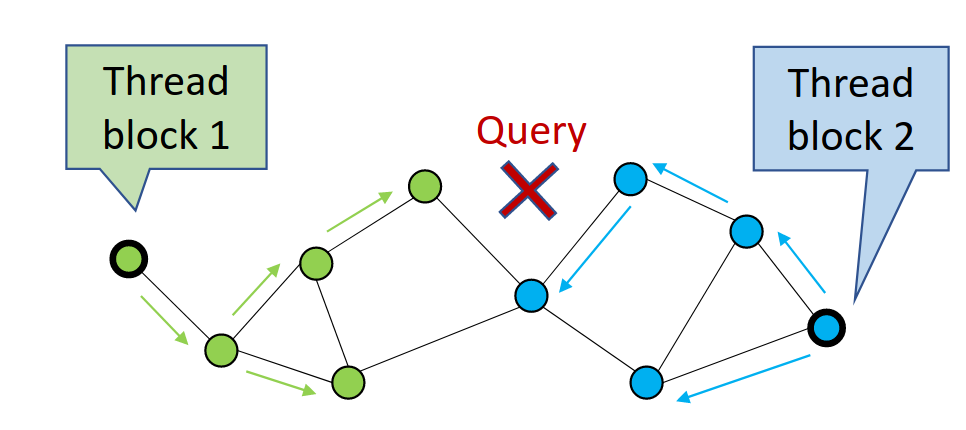
在图 1 中,CAGRA 使用多个线程块并行访问更多的图节点。这最大限度地提高了单查询搜索的 GPU 利用率。
因为 CAGRA 像前面描述的算法一样返回近似的最近邻居,所以它还提供了一些参数来控制召回和速度。
可以调整以权衡搜索速度的主要参数是itopk_size,指定内部排序列表的大小,该列表存储可以在下一次迭代中探索的节点。的较高值itopk_size在内存中保留更大的搜索上下文,这会以花费更多时间维护队列为代价来提高召回率。
参数搜索宽度定义在每次搜索迭代中为展开其子顶点而遍历的最近父顶点的数目。
另一个有用的参数是要执行的迭代次数。默认情况下,该设置是自动选择的,但可以将其更改为更高或更低的值,以换取更快的搜索。
CAGRA 的优化图是固定度的,使用参数进行调整图形度固定度通过在搜索图时保持计算次数的一致性来更好地利用 GPU 资源。它通过计算实际的 k-NN 来构建初始 k-NN 图,例如通过使用前面解释的 IVF-PQ 来计算训练数据集中所有点的最近邻居。
的编号k-最近的邻居(k)可以使用一个名为中间图形度以权衡最终可搜索的 CAGRA 图的质量。
可以使用更大的中间图形度值,这意味着最终优化的图更有可能找到产生高召回率的最近邻居。RAFT 提供了几个有用的参数来调整 CAGRA 算法。想了解更多详细信息,请参阅CAGRA API 文档。
同样,这个参数可以用来控制搜索对整个空间的覆盖程度,但这也是以必须进行更多搜索才能找到最近的邻居为代价的,这降低了搜索性能。
pylibraft 入门
Pylibraft 是 RAFT 的轻量级 Python 库,使您能够使用 RAFT 的 ANN 算法在 Python 中进行矢量搜索。Pylibraft 可以接受任何支持 __CUDA_array_interface__ 的库,例如 Torch 或 CuPy。
以下示例简要演示了如何使用 Pylibraft 构建和查询 RAFT CAGRA 索引。
from pylibraft.neighbors import cagraimport cupy as cp# On small batch sizes, using "multi_cta" algorithm is efficientindex_params = cagra.IndexParams(graph_degree=32)search_params = cagra.SearchParams(algo="multi_cta")corpus_embeddings = cp.random.random((1500,96), dtype=cp.float32)query_embeddings = cp.random.random((1,96), dtype=cp.float32)cagra_index = cagra.build(index_params, corpus_embeddings)# Find the 10 closest vectorshits = cagra.search(search_params, cagra_index, query_embeddings, k=10) |
随着 LLM 的最近成功,语义搜索已经成为展示使用 RAFT 的向量相似性搜索的完美方式。在以下示例中,DistilBERT transformer 模型与三个神经网络指标中的每一个指标相结合,用于解决一个简单的问题检索问题。简单英语维基百科数据集用于回答用户的搜索查询。
语言模型首先将训练语句转换为插入 RAFT ANN 索引的向量嵌入。推理是通过对查询进行编码并使用我们训练的 ANN 索引来找到与编码的查询向量相似的向量来完成的。你返回给用户的答案是简单维基百科中最近的文章,你可以使用相似性搜索中最接近的向量来获取它。
您可以使用 pylibraft 和本笔记本开始 RAFT 的问题检索任务:
基准
使用 GPU 作为矢量搜索应用程序的硬件加速器可以提高性能,这在大型数据集上表现得尤为明显。您可以通过参考 RAFT 的端到端基准测试文档来完全复制这个基准。我们的基准测试假设数据已经可以用于计算,这意味着数据传输没有被考虑在内,尽管由于最近 NVIDIA 硬件的高传输速度(超过 25 GB/s),这应该不会造成显著的差异。
我们使用在 H100 GPU 上的 DEEP-100M 数据集,以将 RAFT 索引与运行在 Intel Xeon Platinum 8480CL CPU 上的 HNSW 进行比较。
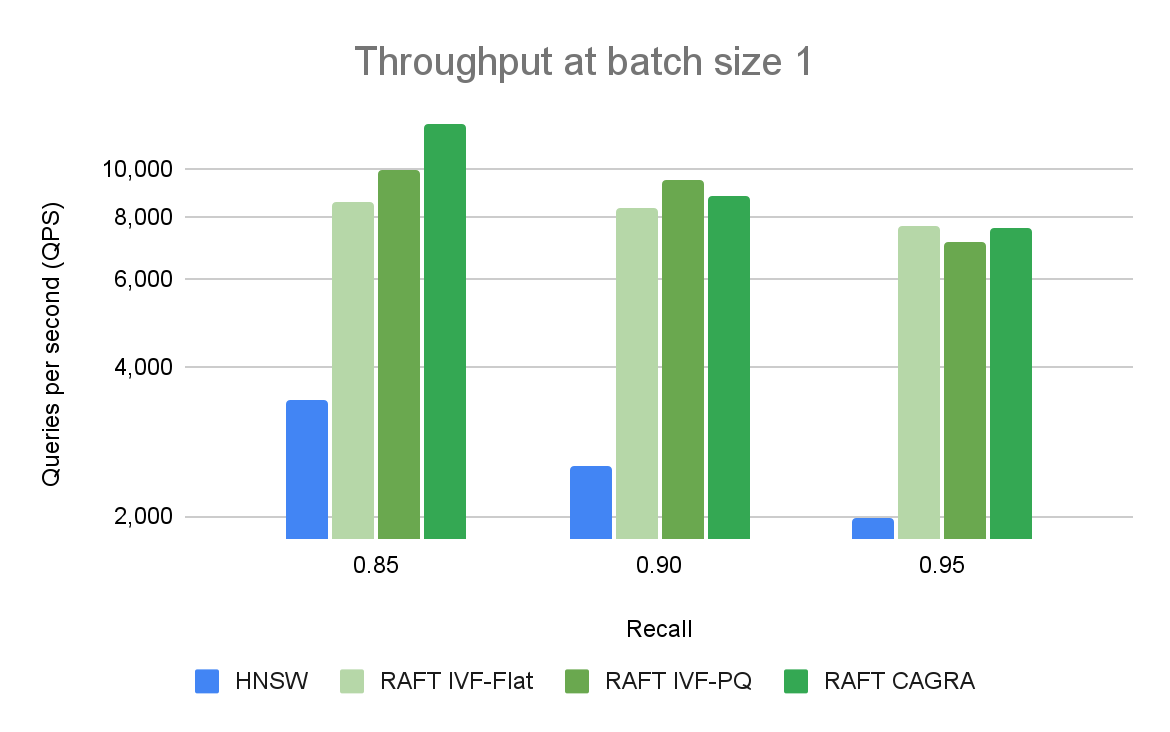
图 2 比较了单个查询在不同召回率和吞吐量水平下的 ANN 算法。在高召回率下,RAFT 的方法显示出比其他替代库更高的吞吐量。
我们一次对单个向量的查询进行性能比较,称为在线搜索。它是矢量搜索的主要用例之一。与使用 CPU 或 GPU 的其他库相比,基于 RAFT 的索引提供了更高的吞吐量(以每秒查询量(QPS)衡量)。
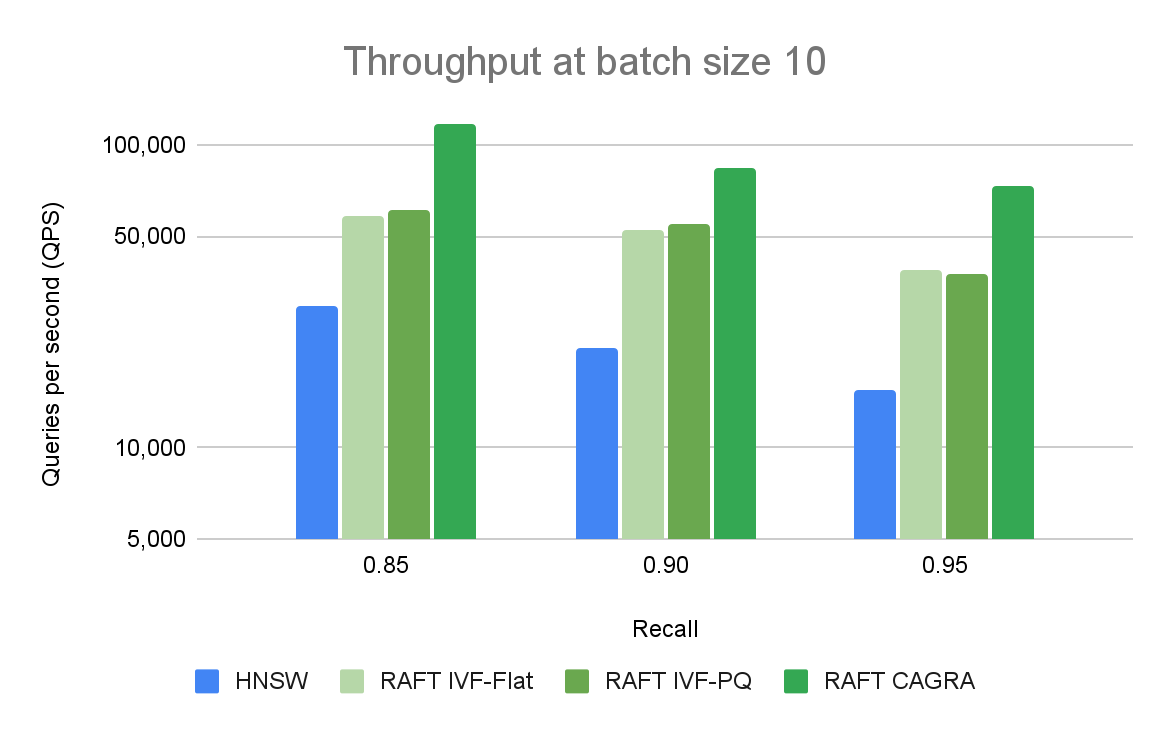
图 3 比较了不同召回和吞吐量级别的 ANN 算法与 10 个查询的批量大小。RAFT 的方法在所有实验中都表现出比 HNSW 更高的吞吐量。
将 GPU 用于矢量搜索应用程序的好处在更大的批量中最为普遍。 CPU 和 GPU 之间的性能差距很大,可以很容易地扩大规模。图 3 显示,对于批量大小为 10 的情况,当比较每秒的查询数时,只有基于 RAFT 的索引是相关的。对于 10k 的批量大小(图 4),CAGRA 迄今为止优于所有其他指数。
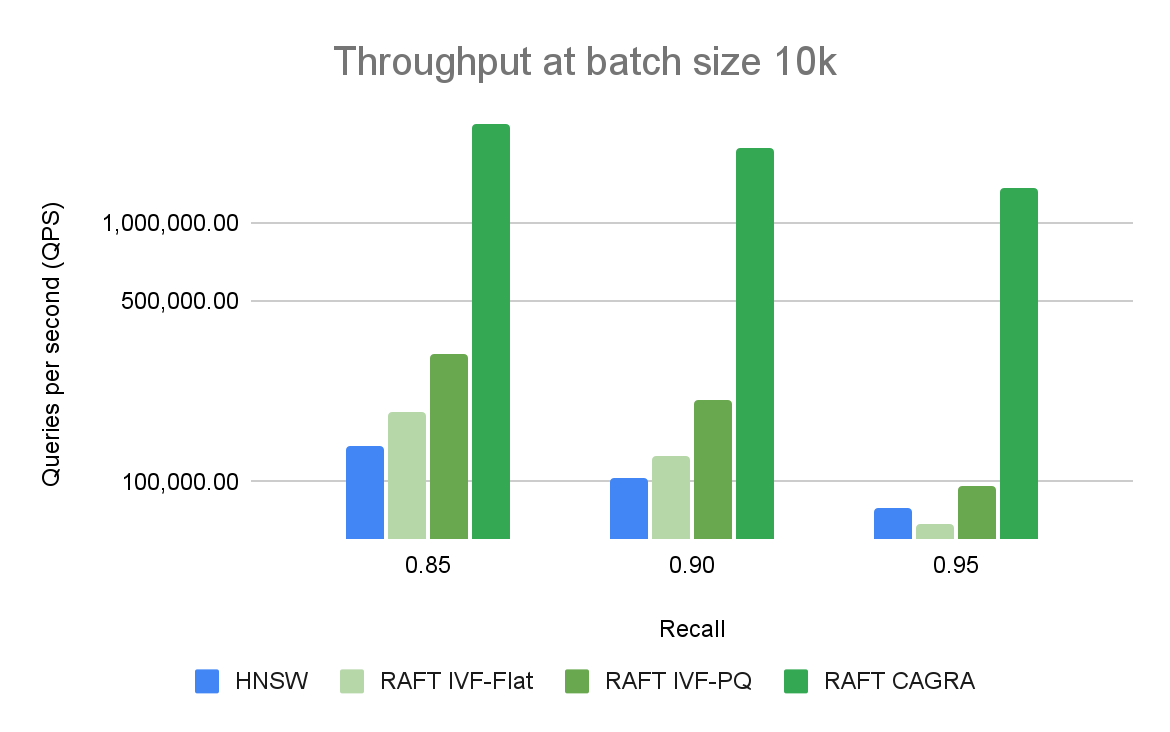
图 4 将不同召回和吞吐量级别的 ANN 算法与批量大小为 10K 的查询进行了比较。RAFT 的方法在所有实验中都表现出比 HNSW 更高的吞吐量。
总结
每种不同的矢量搜索索引类型都有优缺点,最终取决于您的需求。这篇文章概述了其中的一些优点和缺点,简要解释了每种不同算法的工作原理,以及一些最重要的参数,这些参数可以用来权衡存储成本、构建时间、搜索质量和搜索性能。在所有情况下, GPU 都可以提高索引构建和搜索性能。
RAPIDS RAFT 是完全开源的,可在 /rapidsai/raft GitHub 上获取。您可以通过阅读 文档,运行 可复现的基准测试 套件,或基于示例矢量搜索 模板项目 来了解。此外,请务必在 Milvus、Redis 和 FAISS 中查找启用 RAFT 索引的选项。最后,您可以在 Twitter 上关注我们 @rapidsai。