DEVELOPER
首页
博客
论坛
文档
下载
社区研讨会
培训
搜索
Join
数据科学
2024年 4月 3日
使用 WholeGraph 优化图形神经网络的内存和检索,第 2 部分
大规模图形神经网络 (GNN) 训练带来了艰巨的挑战,特别是在图形数据的规模和复杂性方面。这些挑战不仅涉及神经网络的正向和反向计算的典型问题,
2 MIN READ
使用 WholeGraph 优化图形神经网络的内存和检索,第 2 部分
2024年 3月 27日
借助 NVIDIA NeMo Curator 扩展和整理用于 LLM 训练的高质量数据集
大型语言模型 (LLM) 是提高运营效率和推动创新的强大工具。NVIDIA NeMo 微服务 旨在简化构建和部署模型的流程。
1 MIN READ
借助 NVIDIA NeMo Curator 扩展和整理用于 LLM 训练的高质量数据集
2024年 3月 27日
高效的 CUDA 调试:将 NVIDIA Compute Sanitizer 与 NVIDIA 工具扩展程序结合使用并创建自定义工具
NVIDIA Compute Sanitizer 是一款功能强大的工具,可以节省时间和精力,同时提高 CUDA 应用程序的可靠性和性能。
5 MIN READ
高效的 CUDA 调试:将 NVIDIA Compute Sanitizer 与 NVIDIA 工具扩展程序结合使用并创建自定义工具
2024年 3月 21日
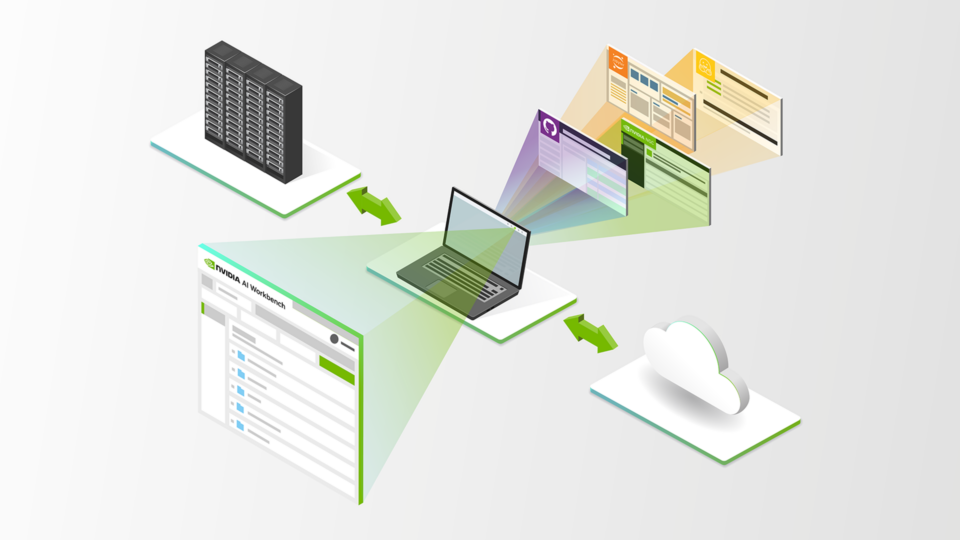
加速 AI 开发: NVIDIA AI Workbench 正式发布
NVIDIA AI Workbench 是面向 AI 和 ML 开发者的工具包。现在已正式推出 免费下载。它具有自动化功能,
1 MIN READ
加速 AI 开发: NVIDIA AI Workbench 正式发布
2024年 3月 20日
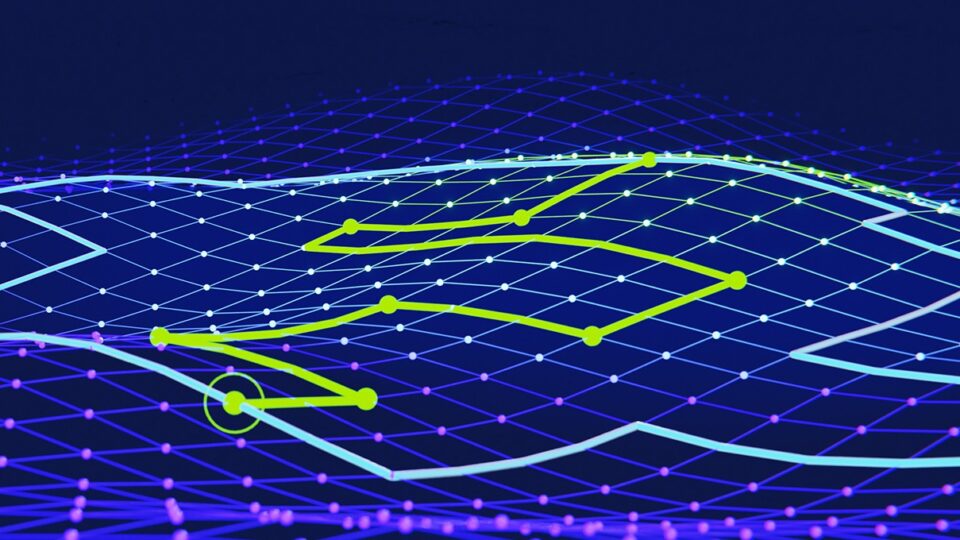
突破性的 NVIDIA cuOpt 算法将路线优化解决方案的速度提高 100 倍
NVIDIA cuOpt 是一个加速优化引擎,专为解决复杂的路线规划问题而设计。它能够高效地处理各种问题,包括但不限于:休息和等待时间、
2 MIN READ
突破性的 NVIDIA cuOpt 算法将路线优化解决方案的速度提高 100 倍
2024年 3月 19日
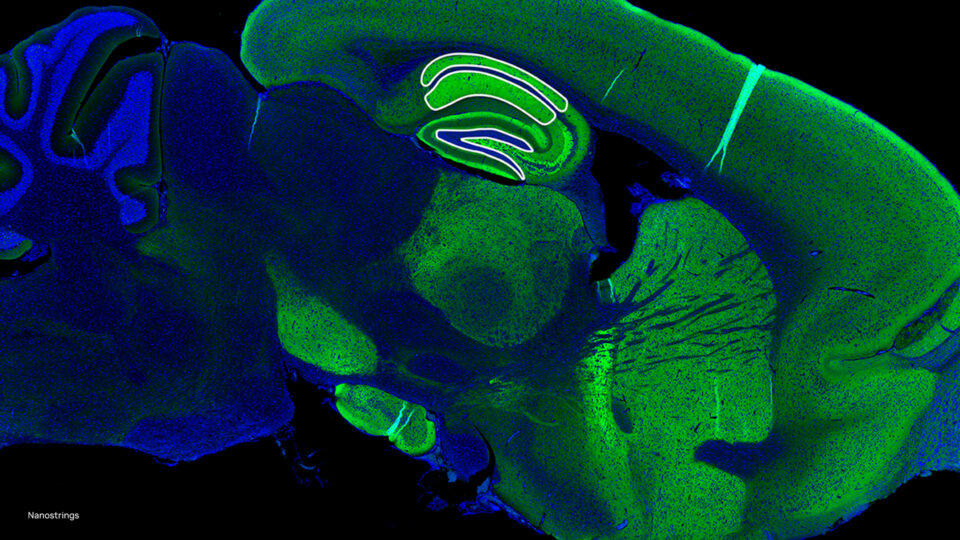
借助 GPU 加速和生成式 AI 加速多组分析
NVIDIA Parabricks v4.3 在 NVIDIA GTC 2024 上发布,引入了新的工具和工作流程,
2 MIN READ
借助 GPU 加速和生成式 AI 加速多组分析
2024年 3月 18日
如何通过四个步骤将 RAG 应用程序从试点阶段转变为生产阶段
生成式 AI 具有改变各个行业的巨大潜力。人类工作者已经开始使用 大型语言模型(LLM) 来解释、推理和解决复杂的认知任务。
2 MIN READ
如何通过四个步骤将 RAG 应用程序从试点阶段转变为生产阶段
2024年 3月 18日
RAPIDS cuDF 可将 pandas 加速近 150 倍,且无需更改代码
在 NVIDIA GTC 2024 上,我们宣布 RAPIDS cuDF 现在可以为 950 万 Pandas 用户带来 GPU 加速,
2 MIN READ
RAPIDS cuDF 可将 pandas 加速近 150 倍,且无需更改代码
2024年 3月 18日
NVIDIA NIM 提供经过优化的推理微服务,用于大规模部署 AI 模型
数字生成的生成式 AI 采用率一直很高。在 2022 年推出 OpenAI 聊天 GPT 的推动下,
2 MIN READ
NVIDIA NIM 提供经过优化的推理微服务,用于大规模部署 AI 模型
2024年 3月 8日
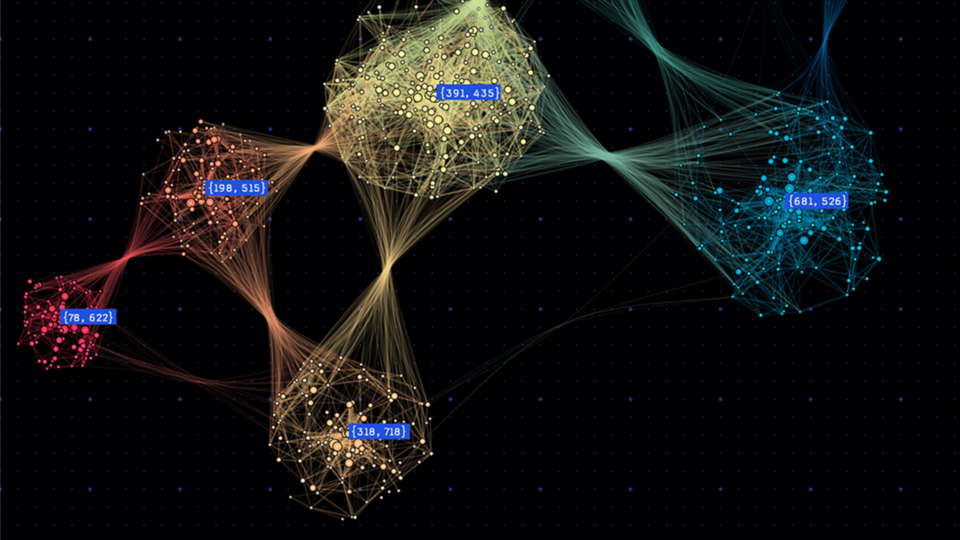
WholeGraph 存储:优化图形神经网络的内存和检索
图形神经网络 (GNN) 彻底改变了图形结构数据的机器学习。与传统神经网络不同,GNN 擅长捕捉图形中的复杂关系,
2 MIN READ
WholeGraph 存储:优化图形神经网络的内存和检索
2024年 3月 5日
聚焦:Honeywell 借助 NVIDIA cuDSS 加速工业流程仿真
多年来,传统的工业流程建模和仿真方法一直在努力充分利用多核 CPU 或加速设备以并行运行模拟和优化计算。
2 MIN READ
聚焦:Honeywell 借助 NVIDIA cuDSS 加速工业流程仿真
2024年 3月 5日
新视频:开创性的气候技术和缓解自然灾害影响
2022 年,澳大利亚莱斯莫尔市遭受严重的洪水袭击,造成 3000 多间房屋受损,社区受到破坏,损失金额高达 60 亿美元,
1 MIN READ
新视频:开创性的气候技术和缓解自然灾害影响
2024年 2月 27日
视频:五分钟内构建 RAG 驱动的聊天机器人
检索增强生成(RAG)作为一种提升性能的技术,其受欢迎程度呈爆炸式增长。从高度准确的问答 AI 聊天机器人到代码生成副驾驶,
1 MIN READ
视频:五分钟内构建 RAG 驱动的聊天机器人
2024年 2月 19日
体验 NVIDIA cuOpt 加速优化,提高运营效率
本周的 Model Monday 版本亮点是 NVIDIA cuOpt,这是一款创新的加速优化引擎,专为帮助团队解决复杂的路线规划问题而设计。
2 MIN READ
体验 NVIDIA cuOpt 加速优化,提高运营效率
2024年 1月 30日
使用现已推出 Beta 版的 NVIDIA AI Workbench 来创建、共享和扩展企业 AI 工作流程
NVIDIA AI Workbench 现已进入测试阶段,带来了丰富的新功能,可简化企业开发者创建、使用和共享 AI 和机器学习 (ML)…
3 MIN READ
使用现已推出 Beta 版的 NVIDIA AI Workbench 来创建、共享和扩展企业 AI 工作流程
2024年 1月 24日
借助 NVIDIA AI 软件构建企业级 AI
在推出 ChatGPT 后,全球各地的企业开始意识到 AI 的优势和功能,并竞相将其应用到工作流程中。 随着这种采用的加速,
2 MIN READ
借助 NVIDIA AI 软件构建企业级 AI
加载更多