
虽然 第 1 部分 专注于使用全新的 NVIDIA cuTENSOR 2.0 CUDA 数学库,但本文将介绍其他使用模式,特别是 Python 和 Julia 的使用。我们还将展示基于基准测试的 cuTENSOR 性能在多个应用领域中的表现。
PyTorch 和 TensorFlow
我们提供 Cutensor Python 软件包,其中包含用于 Einsum 样式的界面。该包利用 cuTENSOR,可以类似于 PyTorch 和 TensorFlow 的原生 einsum 实现。有关更多信息,请参阅 Installation 部分。
例如,cuTENSOR 可以作为 torch.einsum 使用,如下代码示例所示:
from cutensor.torch import EinsumGeneral
output = EinsumGeneral('kc,nchw->nkhw', input_a, input_b) // similar to torch.einsum(...)
CuPy
CuPy 最近增加了对 cuTENSOR 2.0 的支持,这使得 Python 开发者能够轻松利用 cuTENSOR 提升性能。要将 cuTENSOR 作为 CuPy 的后端,请导出 CUPY_ACCELERATORS=cub, cutensor 环境变量并安装正确的 CuPy 版本。
使用 pip:
pip install cupy-cuda12x cutensor-cu12
使用 conda:
conda install -c conda-forge cupy "cutensor>=2" cuda-version=X.Y
启用 cuTENSOR 后,它会自动加速 CuPy einsum 函数:
import cupy as cp
# tensor contraction can be accelerated by cuTENSOR
a = cp.random.random((3, 4, 5))
b = cp.random.random((4, 5, 6))
c = cp.random.random((6, 7))
out = cp.einsum(“abc,bcd,de->ae”, a, b, c)
此外,CuPy 还可以直接访问 cuTENSOR 的低级 API,以便表示以下 einsum 函数:
import cupy as cp
import cupyx.cutensor as cutensor
alpha = 1.0
beta = 0.0
mode_a = ('a', 'b', 'c')
mode_b = ('b', 'c', 'd')
mode_c = ('d', 'e')
mode_ab = ('a', 'd')
mode_abc = ('a', 'e')
a = cp.random.random((3, 4, 5))
b = cp.random.random((4, 5, 6))
c = cp.random.random((6, 7))
ab = cp.empty((3, 6))
abc = cp.empty((3, 7))
cutensor.contraction(alpha, a, mode_a, b, mode_b, beta, ab, mode_ab)
cutensor.contraction(alpha, ab, mode_ab, c, mode_c, beta, abc, mode_abc)
Julia Lang
CUDA.jl (v5.2.0) 新增了对 cuTENSOR 2.0 的支持,使得 Julia 开发者能够轻松利用 cuTENSOR 的性能提升。要在 Julia 中使用 cuTENSOR,请安装 CUDA.jl 包。
安装 CUDA.jl 后,它会使用 CuTensor 对象自动使用 cuTENSOR 加速收缩。
using CUDA
using cuTENSOR
dimsA = (3, 4, 5)
dimsB = (4, 5, 6)
indsA = ['a', 'b', 'c']
indsB = ['b', 'c', 'd']
A = rand(Float32, (dimsA...,))
B = rand(Float32, (dimsB...,))
dA = CuArray(A)
dB = CuArray(B)
ctA = CuTensor(dA, indsA)
ctB = CuTensor(dB, indsB)
ctC = ctA * ctB # cuTENSOR is used to perform the contraction
C, indsC = collect(ctC)
CUDA.jl 还提供了直接访问 cuTENSOR 的更低级别 API,因此上述收缩也可以表示为:
using CUDA
using cuTENSOR
dimsA = (3, 4, 5)
dimsB = (4, 5, 6)
dimsC = (3, 6)
indsA = ['a', 'b', 'c']
indsB = ['b', 'c', 'd']
indsC = ['a', 'd']
A = rand(Float32, (dimsA...,))
B = rand(Float32, (dimsB...,))
C = zeros(Float32, (dimsC...,))
dA = CuArray(A)
dB = CuArray(B)
dC = CuArray(C)
alpha = rand(Float32)
beta = rand(Float32)
opA = cuTENSOR.OP_IDENTITY
opB = cuTENSOR.OP_IDENTITY
opC = cuTENSOR.OP_IDENTITY
opOut = cuTENSOR.OP_IDENTITY
comp_type = cuTENSOR.COMPUTE_DESC_TF32
plan = cuTENSOR.plan_contraction(dA, indsA, opA,
dB, indsB, opB,
dC, indsC, opC, opOut;
compute_type=comp_type)
dC = cuTENSOR.contract!(plan, alpha, dA, dB, beta, dC)
C = collect(dC)
性能
本节将详细了解 cuTENSOR 2.0 的性能,并将其与其他工具进行比较。
cuTENSOR 2.0.0 与 1.7.0 的对比
cuTENSOR 2.0.0 的性能比其 1.x 前身有显著提升,其中关键的改进包括以下内容:
- 核函数的改进
- 改进性能模型以选择最佳内核
- 引入即时编译支持
图 1 概述了 cuTENSOR 2.0.0 在 NVIDIA GA100 和 GH100 GPU 上对各种张量收缩的 cuTENSOR 1.7.0 的速度提升情况,其中不包括 JIT。
此图中显示的加速速度依赖于 CUTENSOR_ALGO_DEFAULT,它会调用 cuTENSOR 性能模型。值得注意的是,对于 NVIDIA Hopper 架构 (GH100),性能提升尤为显著。
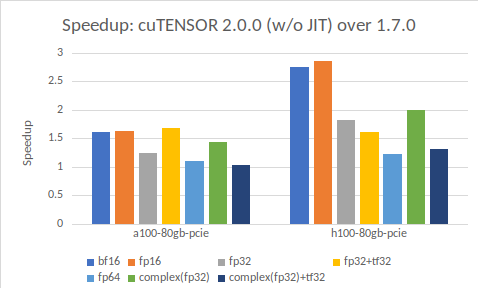
左: NVIDIA A100 80GB PCIe;右: NVIDIA H100 80 GB PCIe。不同的数据类型采用不同的颜色编码。
图 2 仅关注 JIT 编译带来的性能提升,即在 NVIDIA GH100 GPU 上比较不使用 JIT 的 cuTENSOR 2.0 与使用 JIT 的 cuTENSOR 2.。
图 2 将收缩分为两个独特的基准测试:
- 类似于 QC是一个基准测试,可以捕捉常见的量子电路模拟中的张量收缩结构,张量平均维度为 19.。
- rand1000 是一个 公共收缩基准测试,它包含随机收缩,平均张量维度为 4。
对于类似 QC 的基准测试,由于 JIT 的加速效果更大,这并不令人惊讶,因为这些缩减过程更复杂。它们通常会导致偏差缩减,因此需要专用核函数,这些核函数无法通过固定的预构建核函数有效地解决问题。
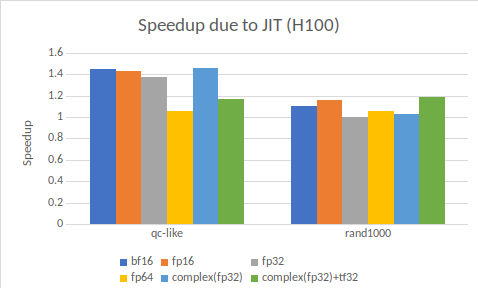
量子电路模拟
本小节概述了 cuTENSOR 为基于张量网络的 53 位 Sycamore 量子电路提供的张量网络量子电路模拟性能提升。
我们基于两种不同的切割选择演示了张量网络收缩的性能,以限制最大中间张量的大小为 16 GB 或 32 GB。这种不同的收缩路径(张量合并顺序)。有关更多信息,请参阅 经典模拟量子优势电路。
理想情况下,您希望尽可能少切割模式,以减少浮点运算 (FLOP),但这也会增加所需的内存,从而使某些切割选项变得不可行。
具体来说,由于增加的内存需求,PyTorch 无法适用于更好的切割选项,从而产生 32 GB 中间张量。相比之下,cuTENSOR 不受同样的限制,因为它的直接收缩内核不需要任何辅助内存。
我们在所有框架中对张量模式进行了相同的订阅,以确保做出公平的比较。有关更多信息,请参阅 中间张量模式顺序的重要性 和 在现代 GPU 上使用张量网络方法实现高效的量子电路模拟。
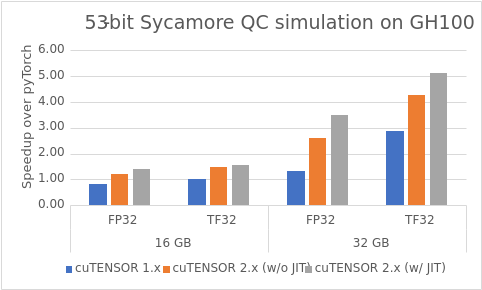
图 3 重点介绍了 cuTENSOR 2.0 与 PyTorch 2.1.0 在 Sycamore QC 模拟中的加速情况。总结如下:
- cuTENSOR 2.0 的性能始终优于 PyTorch。
- cuTENSOR 2.0 的性能优于上一代产品 (类似于图 3)
- 即时编译可进一步提升性能 (类似于图 4)
- 与 FP32 相比,TF32 显著提升了性能。
- 与 PyTorch 相比,速度提升尤为明显,这是因为 PyTorch 消耗了过多的内存,因此无法使用更具计算效率的收缩路径。我们比较了 PyTorch 仍然能够计算的最佳路径:与 16 GB 中间张量相对应的路径。
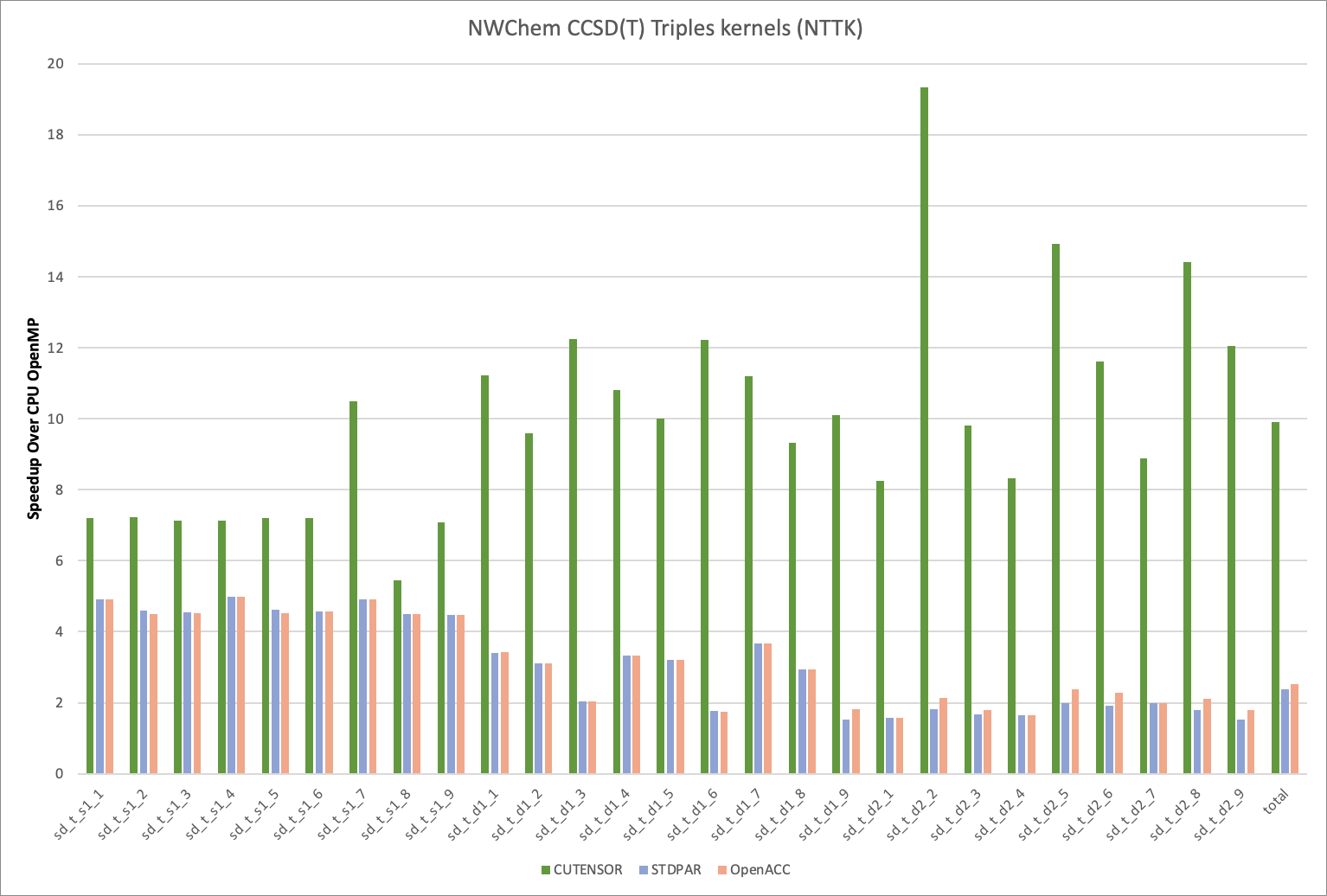
量子化学多体理论
带有单电子、双电子和扰动三电子激发 (CCSD (T)) 的耦合簇是一种备受赞誉的量子化学方法,它在计算分子电子结构方面具有极高的准确性,尤其适用于电子相互作用至关重要的系统。在量子化学计算领域,它常被称为黄金标准,尤其适用于电子相互作用至关重要的系统。
CCSD (T) 方法通过一系列激发级别整合相关电子运动,从而增强了 Hartree-Fock 方法。在此方法中,单电子和双电子激发通过迭代方式计算,而三电子激发则通过非迭代方式应用偏差修正。
这种方法特别适用于准确预测基态能量、反应能量和屏障高度,尤其是在弱电子相互作用系统中。尽管它具有较高的计算需求,但 CCSD (T) 在准确性和计算成本之间取得了良好平衡,因此在计算化学领域备受欢迎。
图 4 重点展示了在 NVIDIA H100 GPU 上运行的 cuTENSOR 与在 72 核 NVIDIA Grace CPU 上基于 OpenMP 的实现相比,速度提升的情况。该基准测试使用了 NWChem TCE CCSD (T) 循环驱动核函数,这是 NWChem Tensor Contraction Engine (TCE) 模块中 CCSD (T) 三重核心的独立驱动程序。
开始使用 cuTENSOR 2.0
如果您有关于 cuTENSOR 的功能请求,例如计算例程或不同的计算或数据类型,请联系我们 Math-Libs-Feedback@nvidia.com.
开始使用 cuTENSOR 2.0 详细了解 cuTENSOR 2.0。访问 开发者论坛 获取更多讨论和资源。
[1] Huang, Cupjin, et al. “Classical simulation of quantum supremacy circuits.” arXiv preprint arXiv:2005.06787 (2020).
[2] Springer, Charara, Hoehnerbach. SIAM CSE’23, “The Importance of Middle Tensor Mode Order.”
[3] Pan, Feng, et al. “Efficient Quantum Circuit Simulation by Tensor Network Methods on Modern GPU.” arXiv preprint arXiv:2310.03978 (2023).




