视频质量指标用于评估视频内容的保真度。它们提供一致的量化测量,用于评估编码器的性能。
- 峰值信噪比 (PSNR):一种评估图像质量的老牌指标,用于比较参考图像的像素值与降质的图像。
- 结构相似性指数测量 (SSIM) :比较降质图像的亮度、对比度和结构与原始图像。
- 视频多方法评估融合 (VMAF):这一指标由 Netflix 推出,旨在准确捕捉人类视觉感知。
VMAF 将人类视觉建模与不断发展的机器学习技术相结合,使其能够适应新内容 .VMAF 通过结合视频质量因素的详细分析和人类视觉建模以及先进的机器学习,很好地契合了人类视觉感知。
本文展示了 CUDA 加速的 VMAF(VMAF-CUDA)如何在 NVIDIA GPU 上计算 VMAF 分数。VMAF 图像特征提取器被移植到 CUDA,使其能够使用 NVIDIA 视频编解码器 SDK。我们观察到开源工具 FFmpeg 的吞吐量提高了 4.4 倍,4K 时的延迟降低了 37 倍。加速现在正式成为 VMAF 3.0 和 FFmpeg v6.1。
VMAF-CUDA 的实现是 NVIDIA 和 Netflix 成功开源协作的结果。该协作的成果包括扩展的 libvmaf API(带有 GPU 支持)、libvmaf CUDA 特征提取器以及附带的上游 FFmpeg 过滤器 libvmaf_cuda.VMAF-CUDA 必须从源代码构建。使用 Dockerfile.cuda 作为所有必需库和步骤的参考。
VMAF 关键基本指标
VMAF 使用参考图像和扭曲图像中的关键基本指标来评估视频质量:
- 视觉信息保真度 (VIF):量化保留原始内容的程度,反映感知信息损失。
- 增量失真测量 (ADM):评估结构变化和纹理破坏情况。尤其对增量扭曲(如噪声)敏感。
- 运动特征:对于评估动态场景中的动作渲染质量至关重要。
这些指标作为支持向量机 (SVM) 回归器的输入特征,将它们融合在一起,以计算最终的 VMAF 评分。这种方法可确保视频质量的全面、准确表达。
VIF 和 ADM 等特征提取器不需要任何先前信息。它们只需要作为输入的参考帧和变形帧即可。与其他两种不同,动态特征提取还需要前一次动态特征提取器迭代的信息 (帧间依赖性)。
GPU 和 CPU 上的 VMAF 实现
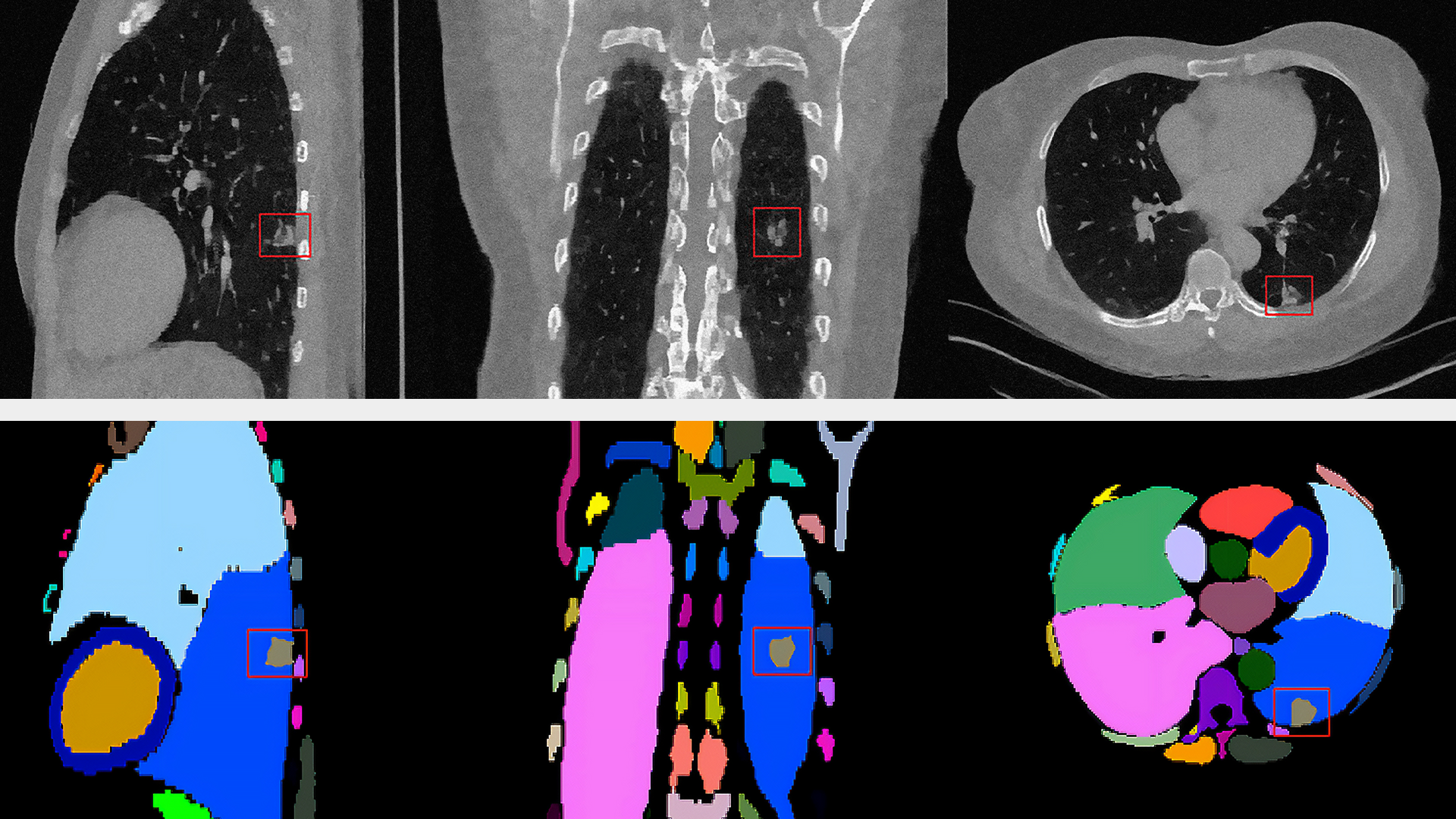
VMAF 的 CPU 实现可以将上述特征的计算分配到多个线程中,因此 VMAF 计算可以受益于更多的 CPU 核心 .CPU 实现的 VMAF 计算取决于要提取的最慢特征 (图 1)。
此外,动作特征评分计算具有时间依赖性,因此无法多线程。因此,每帧 VMAF 评分延迟与使用的线程数无关。性能分析表明,VIF 通常需要更长的计算时间,因此它是限制性特征提取器。然而,使用更多线程可以提高每秒帧数 (FPS) 的 VMAF 吞吐量。
VMAF 最近已移植到使用 NVIDIA GPU 的 CUDA 上运行。VMAF-CUDA 需要 CUDA 工具包,但除了 GPU 驱动程序之外,不需要其他额外库进行部署。
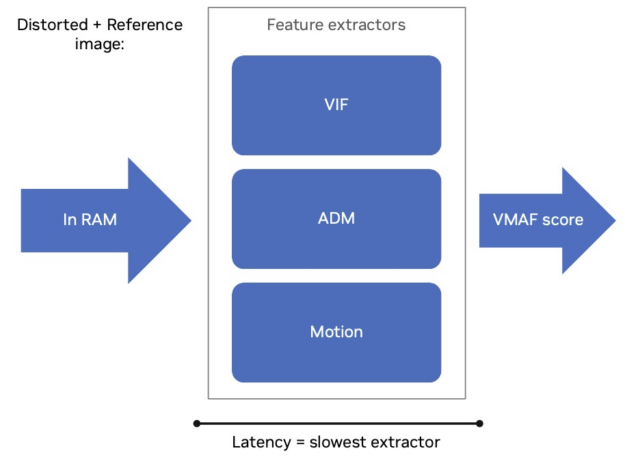
与 CPU 实现相比,VMAF-CUDA 采用了不同的方法 .CUDA 实现不会将 GPU 计算资源分配给特定的特征提取器,而是为每个特征分配整个 GPU 计算资源,并按顺序计算 (图 2)。
这会加快每个特征的计算速度,使得 VMAF 评分延迟现在取决于所有特征提取器的总和 .CUDA 实现加速了特征提取器,并且兼容不同的 VMAF 功能,例如支持 VMAF 模型 VMAF 4K 和 VMAF NEG。
VMAF-CUDA 可以作为使用 VMAF-CPU 的现有管线的替代品。如果图像位于 CPU 内存中,它会立即上传到 GPU。整个 GPU 实施包括从 GPU 到 GPU 的特征提取器计算和内存传输。它与 CPU 异步运行。
NVIDIA 还利用 VMAF-CUDA 作为加速 PSNR 计算的机会。通常,VMAF 和 PSNR 会同时计算。我们的研究指出,如果 PSNR 在 CPU 上运行,它将成为瓶颈,因为它需要通过 PCIe 总线从 GPU 内存中获取解码图像。PCIe 传输速度有限,严重影响了性能。为此,可以在 GPU 上计算 PSNR,以实现加速,例如通过 CUDA 加速 PSNR#1175 补丁。
VMAF-CUDA 的优势
VMAF-CUDA 可在编码期间使用 . NVIDIA GPU 可在 NVENC 和 NVDEC 之外独立运行 GPU 核心的计算工作负载。NVENC 可消耗原始视频帧,而 NVDEC 可将输出帧转换为视频内存。这表示,参考帧和扭曲帧都在视频内存中,可以输入到 VMAF-CUDA (图 2)。因此,编码期间可以计算 VMAF,因为 NVENC 不需要 GPU 计算资源。
它还可用于质量监控。在将 H.264 比特流转换为 H.265 时,NVDEC 会解码输入比特流并将其帧写入 GPU VRAM (参考帧)。这个参考帧使用 NVENC 编码为 H.265,可以直接解码,从而产生扭曲的帧。这个过程会使 GPU 上的转码处于空闲状态,同时保留在 GPU 内存中的数据 .VMAF-CUDA 可以利用这些空闲资源并计算评分,而不会中断转码,也不会产生额外的内存传输。因此,与 CPU 实现相比,它是一个经济高效的选择。
VMAF-CUDA 与 FFmpeg v6.1 完全集成,支持 GPU 帧 硬件加速解码。FFmpeg 是一款行业标准的开源工具,用于处理多媒体文件和视频流。通过从源构建 VMAF 和 FFmpeg,您只需要最新的 NVIDIA GPU 驱动程序进行执行,而无需掌握 CUDA 的任何先前知识。
在 Docker 容器中的使用使得依赖项处理和编译变得十分便捷且可移植。FFmpeg 中的 VMAF-CUDA 在 GPU 上异步执行,从而释放 CPU 用于执行其他任务。
评估
我们使用 VMAF-CUDA 测量了两个指标:
- 每帧 VMAF 延迟:计算三个特征提取器以获得一帧的 VMAF 评分所需的时间。
- 总吞吐量:如何快速计算视频序列的 VMAF 评分。
所用的硬件是一个 56C/112T 双英特尔至强 8480 计算节点和一个 NVIDIA L4 GPU。
VMAF 延迟改进
使用 NVIDIA 工具扩展程序 (NVTX) 来测量帧级特征提取器的延迟,该程序被放置在 VMAF 库中的特定范围内(libvmaf)。此外,还利用 Nsight Systems 工具来捕获追踪,这些追踪基于 VMAF 工具,这些工具来自 VMAF 库的 GitHub 资源库。
在本例中,延迟是指计算三个特征提取器所需的时间,以获得单帧 VMAF 评分 .NVTX 允许您在 CPU 和 GPU 上测量函数或操作的运行时间。在测量中,CPU 和 GPU 特征提取器在 4K 和 1080p 测试序列中独立运行。
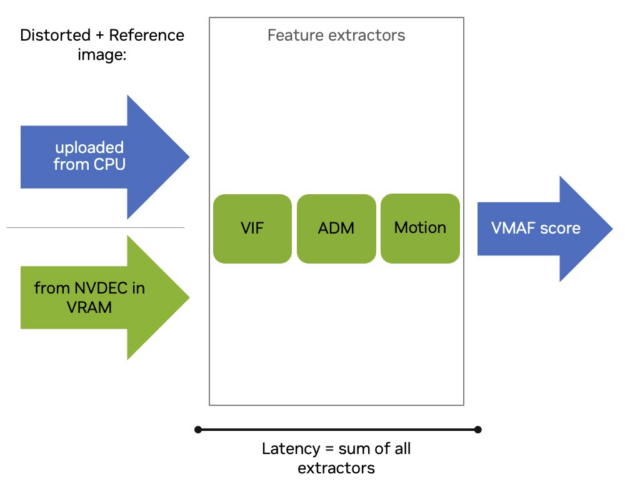
用于这项测量的硬件是一个 56C/112T 双英特尔至强 8480 计算节点和一个 NVIDIA L4 GPU。测量结果显示,在 NVIDIA L4 上处理一张图像的特征提取器延迟比使用英特尔至强 8480 CPU 时快 30 到 90 倍 (图 3)。
在 1080p 等较低分辨率下,VMAF-CUDA 不会饱和单个 NVIDIA L4,因此与在 4K 等较高分辨率下的 VMAF-CPU 相比,您会看到更好的延迟改进。
图 4 显示了平均 VMAF 评分访问延迟。
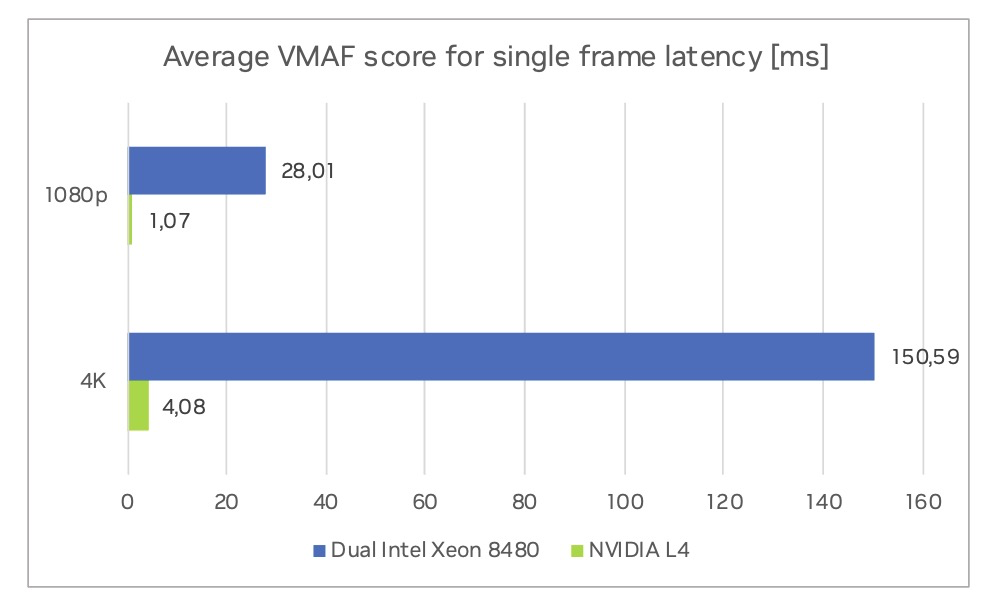
NVIDIA L4 GPU 延迟时间是指在 GPU 上顺序运行的每个特征提取器的平均运行时间之和。双英特尔至强计算节点的平均延迟时间由运行在多个核心上并行的最慢的特征提取器决定。在 4K 分辨率下访问单帧 VMAF 评分时,VMAF-CUDA 的速度比双英特尔至强 8480 快 36.9 倍;在 1080p 分辨率下,速度比双英特尔至强 8480 快 26.1 倍。
FFmpeg 性能提升
我们通过在 FFmpeg 中计算 VMAF 来测量吞吐量 (FPS)。与 VMAF 工具不同,FFmpeg 能够直接将编码视频读入 GPU 或 CPU RAM,而不是从磁盘读取原始字节流。我们使用libvmaf_cudaGPU 实现的视频滤镜,libvmafCPU 实现的视频滤镜。我们使用 YUV420 每通道 8 位、4K 和 1080p HEVC 编码测试序列作为输入。
以下 FFmpeg 命令使用 GPU 实现计算 VMAF 评分:
ffmpeg -hwaccel cuda -hwaccel_output_format cuda -i distorted.mp4 -hwaccel cuda -hwaccel_output_format cuda -i reference.mp4 -filter_complex "[0:v]scale_npp=format=yuv420p[dis],[1:v]scale_npp=format=yuv420p[ref],[dis][ref]libvmaf_cuda" -f null –
-hwaccel cuda -hwaccel_output_format cuda:为硬件加速的视频帧启用 CUDA。使用 NVDEC 在 GPU 上解码视频,并将其输出到 GPU VRAM。这对于实现高吞吐量至关重要,因为它可以避免由于从 CPU 到 GPU 的内存传输而导致吞吐量降低。-filter_complex:启动一个描述视频处理管线的复杂过滤器。每个步骤都是用逗号分隔的视频过滤器,并且始于用方括号括起的输入。[0:v]scale_npp=format=yuv420p[dis]:获取第一个输入视频 (distorted.mp4),在这里0:v并将其格式化为yuv420使用scale_npp,因此,它与 VMAF 兼容 .VMAF 支持 8 位、10 位或 12 位的 YUV420、YUV422 和 YUV444,但 NVDEC 将 YUV420 输出为 NV12,这需要这种重新格式化。最后,它将结果存储在一个变量中:dis同样,参考输入视频 (reference.mp4),在这里1:v并将其存储在ref。[dis][ref]libvmaf_cuda:获取输出dis和ref从上一个过滤器和输入中获取libvmaf_cuda视频滤镜,可计算两个输入视频的 VMAF 评分。与其他指标不同,这里的输入顺序非常重要,因为指标不是对称的。
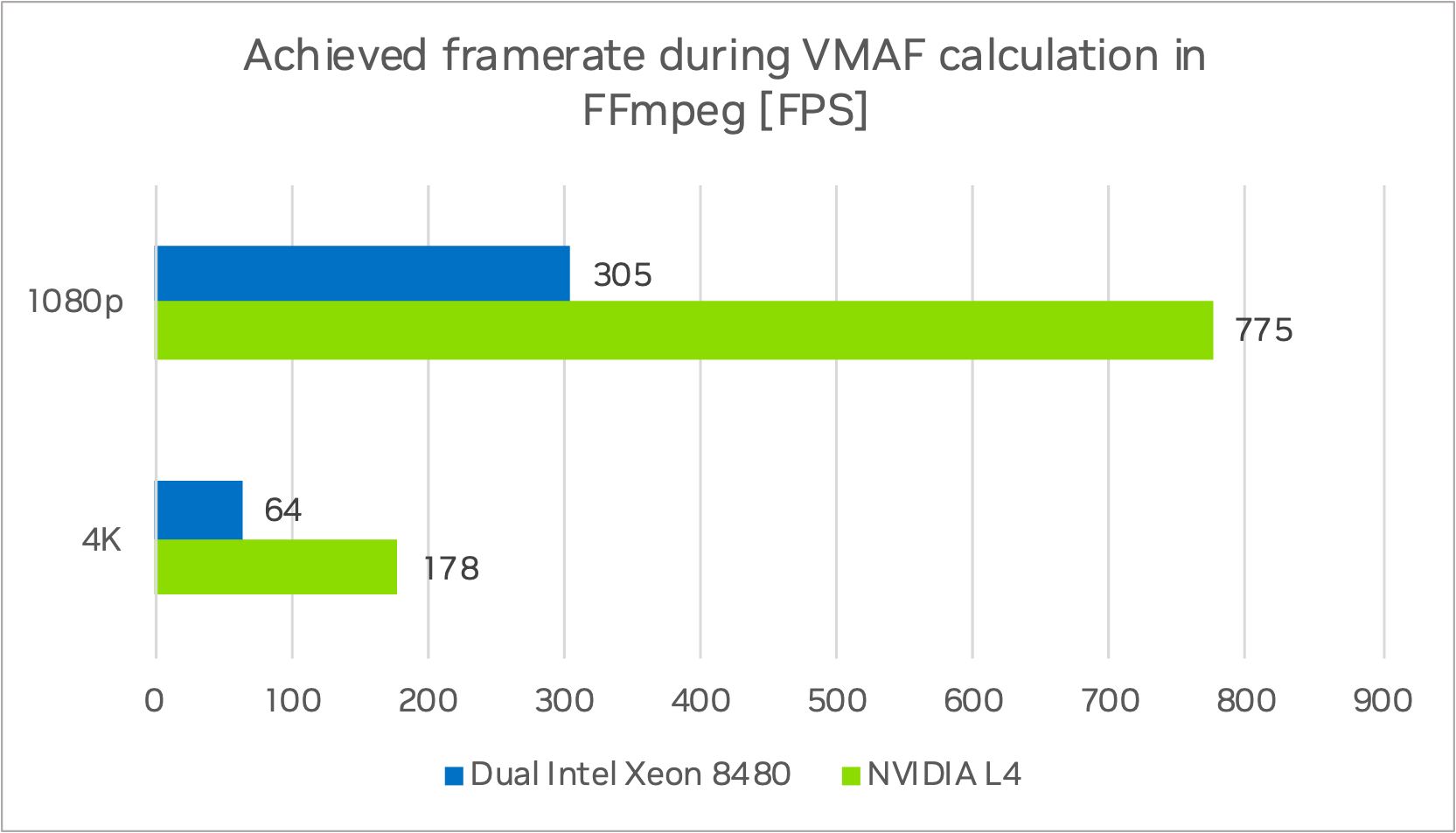
NVIDIA L4 在 4K 分辨率下达到 178 FPS,在 1080p 分辨率下达到 775 FPS,而双路英特尔至强 8480 计算节点在 4K 分辨率下达到 64 FPS,在 1080p 分辨率下达到 176 FPS (图 5)。在处理单个视频流时,4K 序列的速度提升了 2.8 倍,1080p 序列的速度提升了 2.5 倍。
美元成本分析
对于成本分析,我们基于通常在数据中心中使用的标准 2U 服务器进行计算。
NVIDIA L4 采用单插槽半高外形规格,可以在配备廉价英特尔至强或 AMD Rome 处理器的 2U 服务器中安装 8 个 NVIDIA L4 单元。在 VMAF 计算期间,单个 FFmpeg 进程/实例无法充分利用双路英特尔至强 8480 计算节点,而 NVIDIA L4 处于 100%占用率。
图 6 显示了使用多个 FFmpeg 进程对 2U 双英特尔至强系统的总计算性能进行测试,以充分利用 CPU 的结果,以及 2U 八个 L4 服务器的 FPS 数字。
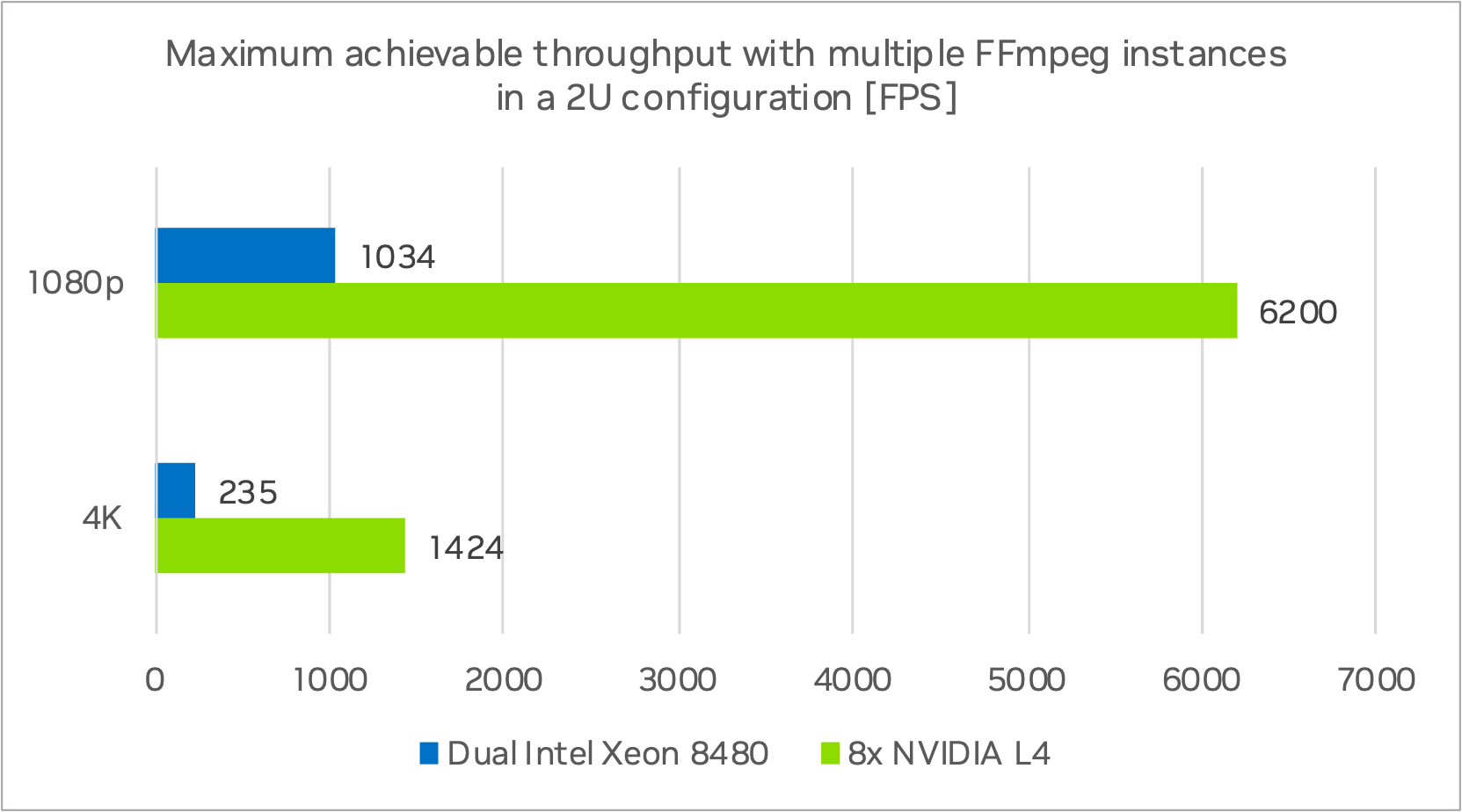
Dual Intel Xeon 8480 和八个 NVIDIA L4 上的多个 FFmpeg 实例
Dual Intel Platinum 8480 节点的总吞吐量为 1034 FPS 在 1080p 分辨率下和 235 FPS 在 4K 分辨率下,使用多个 FFmpeg 实例/进程.8 台 NVIDIA L4 GPU 的 2U 服务器系统的总吞吐量为 6200 FPS 在 1080p 分辨率下和 1424 FPS 在 4K 分辨率下。在相同功耗水平下,1080p 和 4K 分辨率的速度提升了约 6 倍。
下表对 2U 服务器的每 VMAF 帧的成本进行了细分。
| NVIDIA L4 | Dual Intel Platinum 84801 | |
| 1000 小时的 4K 视频,帧速率为 30 FPS | 1 亿帧 | 1 亿帧 |
| 服务器类型 | 2U | 2U |
| 处理器数量 | 8 | 2 |
| 总吞吐量 | 1424 FPS | 235 FPS |
| 计算 VMAF 评分所需的时间 | 21.0 小时 | 127.6 小时 |
| 3 年总体拥有成本 | 3 万美元 | 20000 美元 |
| 计算 1000 小时 4K 视频 30 FPS 时的 VMAF 成本 | 24 美元 | 97 美元 |
1仅使用 CPU 的服务器 (2U 机箱,双 Intel Platinum 8480,512GB RAM,1TB SSD,网卡) | L4 服务器 (2U 机箱、2S 32C CPU、128GB RAM、1TB SSD、CX6 网卡)
与 Dual Intel Platinum 8480 相比, NVIDIA 系统可节省高达 75%的成本。
合作伙伴成功案例
我们希望展示我们的合作伙伴取得的一些成就和经验,重点介绍他们在软件和视频处理流程中使用 VMAF-CUDA 和 NVIDIA GPU 取得的成就 .Snap (作为测试版用户) 提供的宝贵反馈对于 VMAF-CUDA 的发展至关重要。
捕捉
Snap 可以跟踪视频质量指标的时间变化,其中包括 CUDA 加速的 VMAF,以确保转码质量始终如一。
他们目前正在使用 VMAF-CUDA 来确定特定编码是否达到质量阈值,并根据需要重新编码。引入 VMAF-CUDA 优化了处理流程。以前,由于 VMAF 计算的高计算成本,Snap 不敢使用优化的转码设置。但是,借助 VMAF-CUDA,他们可以在每次转码后评估 Snapchat Memories,并使用优化的设置进行重新编码,而不会产生额外的开销。
Snap 通常可以将处理时间加快 2.5 倍,这是因为它能够在 GPU 上独立运行 VMAF 计算,从而使 VMAF 比基于 CPU 的方法更具成本效益 .Snap 使用 Amazon EC2 g4dn.2xlarge 实例和 T4 GPU 进行 VMAF 计算。
CUDA 加速的 VMAF 使 Snap 能够实现之前无法实现的项目 .Snap 希望扩大 VMAF-CUDA 的使用范围,并完全从基于 CPU 的 VMAF 计算过渡到基于 GPU 的 VMAF 计算。
V-Nova
V-Nova 正在探索 CUDA 加速的 VMAF 计算在几个用例中的优势。这些用例包括在 LCEVC (MPEG-5 第 2 部分) 编码过程中的离线指标计算和实时决策中的实用性。集成 VMAF-CUDA 可显著加速离线指标计算。
2023 年,V-Nova 的视频质量工具 (包括 Video Quality Framework 和 Parallel Performance Runner (PAPER)) 每周处理大约 2 万个编码作业 .VMAF-CUDA 已证明能够至少将指标计算速度提升 2 倍。
从长远来看,由 VMAF-CUDA 提供支持的实时内环 VMAF 计算可为算法增强提供额外优势,例如优化 LCEVC 模式决策和速率控制这一指标。
更多资源
关于 VMAF 及其相关主题(如 VMAF 黑客)的更多信息,请参阅以下资源。请务必参加我们的 NVIDIA GTC 2024 会议,VMAF CUDA:以转码的速度运行。
- 实用的感知视频质量指标
- 为视频社区提供更好的质量指标
- Hacking VMAF and VMAF-NEG: Exploiting Vulnerabilities in Different Preprocessing Methods