
NVIDIA cuTENSOR 是一个 CUDA 数学库,提供经过优化的张量运算。张量是一种密集的多维数组或数组片段。cuTENSOR 2.0 的发布代表着功能和性能方面的重大更新,这一版本重构了其 API,使其更富有表现力,包括在 NVIDIA Ampere 和 NVIDIA Hopper GPU 架构上实现的出色性能。
虽然张量运算看起来很陌生,但它们描述了许多自然发生的算法。尤其是,这些运算在机器学习和量子化学中十分常见。
如果您已经使用 NVIDIA cuBLAS 或 BLAS,cuTENSOR 提供的三个例程可能会让您感到眼前一亮:
- 元素式 API 对应于 1 级 BLAS (向量向量运算)
- 归约 API 对应于二级 BLAS (矩阵向量运算)
- 收缩 API 对应于 3 级 BLAS (矩阵-矩阵运算)
主要区别在于,cuTENSOR 可将这些运算扩展到多维度 .cuTENSOR 使您无需担心这些运算的性能优化,而是可以依靠现成的加速例程。
cuTENSOR 的优势和进步不仅可以通过您的 CUDA 代码使用,而且还可以通过其他许多工具使用,这些工具目前均已提供对 cuTENSOR 的支持。
- Fortran 开发者可以从 NVIDIA HPC SDK 中提供的 cuTENSOR Fortran API 绑定中受益,NVFORTRAN.
- Python 开发者可以通过CuPy访问 cuTENSOR 中提供的 NVIDIA GPU 加速的张量收缩、归约和元素计算。
- cuTENSOR 也可用于 Julia 开发者使用的 Julia Lang。
借助 cuTENSOR 加速的程序数量不断增加。我们还提供使用 TensorFlow 和 PyTorch 在 C++和 Python 中入门的示例代码。
在本文中,我们讨论了 cuTENSOR 支持的各种操作,以及如何作为 CUDA 编程人员利用这些操作。我们还分享了性能注意事项和其他有用的提示和技巧。最后,我们分享了我们使用的示例代码,这些代码也可以在 /NVIDIA/CUDALibrarySamples GitHub 资源库中找到。
cuTENSOR 2.0
cuTENSOR 2.0 在性能、特征支持和易用性方面实现了重大进步,我们重构了元素运算、归约和张量收缩的 API,使其保持一致,以便所有运算遵循相同的多阶 API 设计 (图 1)。
cuTENSOR 首次引入对张量收缩的即时编译支持,使您能够编译针对特定张量收缩定制的专用核函数。这一功能对于高维张量收缩尤为有价值,因为它们经常在量子电路模拟中出现。
Tensor permutations 现在还支持填充,使得输出张量可以按照任意维度进行填充,以满足任何对齐要求或避免后续核函数的预测。
从 cuTENSOR 2.0 开始,计划缓存是默认启用的。换句话说,它的默认设置从 opt-in 更改为 opt-out,这有助于以用户友好的方式减少规划开销。
最后,我们在元素运算、归约和张量归约之间的 API 设计保持一致,即所有运算都遵循张量归约的相同多阶 API 设计,这样您就可以重复使用元素运算和归约运算的计划。
本文仅介绍最新的 2.0 API。有关如何从 1.x 过渡到 2.0,请参阅 从 cuTENSOR 1.x 过渡到 cuTENSOR 2.x。
API 介绍
本节介绍了 cuTENSOR API 背后的关键概念,以及如何在代码中调用它们。有关更多信息和全面示例,请参阅 /NVIDIA/CUDALibrarySamples GitHub 资源库和 入门指南 cuTENSOR 文档。
第一步是初始化 cuTENSOR 库句柄 (每个线程一个),以便库做好准备并仅执行一次昂贵的设置工作。
cutensorStatus_t status;
cutensorHandle_t handle;
status = cutensorCreate(handle);
// [...] check status
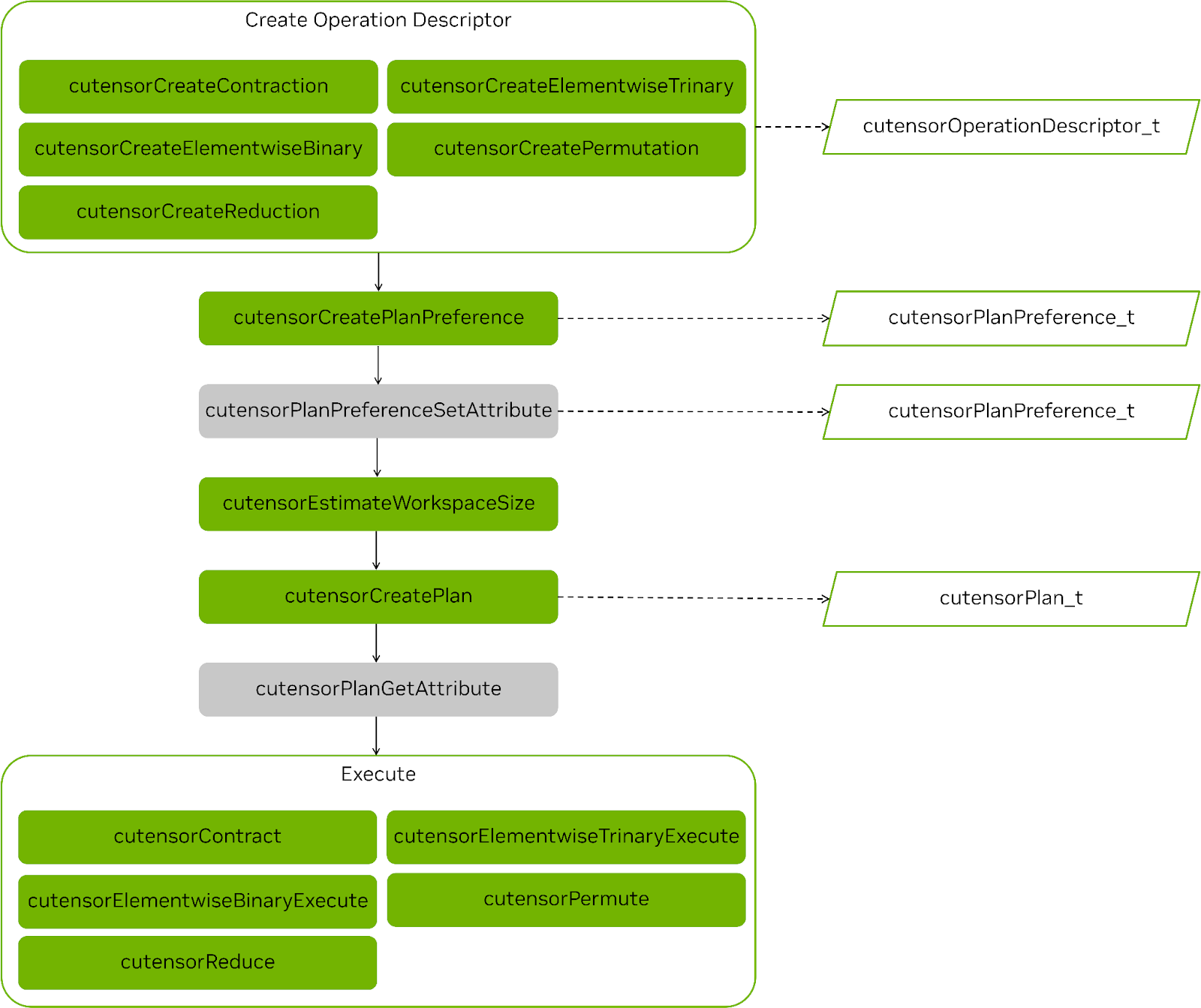
创建把握后,它可以重复用于任何后续 API 调用。从 cuTENSOR 2.0 开始,所有操作都遵循相同的工作流程:
- 创建操作描述符:
cutensorTensorDescriptor_t来捕捉张量的物理布局。cutensorOperationDescriptor_t来编码操作本身。cutensorPlanPreference_t限制可用核函数的空间。
- (可选) 设置计划首选项的属性。
- 估算工作空间需求。
- 创作
cutensorPlan_t选择用于执行操作的内核。- 调用 cuTENSOR 性能模型。
- 若启用 JIT,则可能会导致编译步骤。
- (可选) 查询计划实际使用的工作空间。
- 执行实际操作。
图 1 显示了任何操作的步骤,并突出显示了常见步骤。
Tensor 描述符是 cuTENSOR API 的重要组成部分。它可以编码以下内容:
- 密集张量的物理布局:
- 张量元件的数据类型
- 维度 (秩) 数
- 每个维度的范围
- 相同维度的两个相邻元件之间的步长 (线性内存)
- 相应数据指针的对齐要求 (通常为 256 字节,匹配 CUDA 默认对齐)
cudaMalloc).
在本文中,我们使用维度和模式互换使用。
这可能很抽象,因此请考虑图 2.这是一个三维张量,其元素按照它们在内存中的排列顺序编号。这个张量在每个维度中具有三个元素的范围。其第一个维度的步长为 1,第二个维度的步长为 3,最后一个维度的步长为 9.这对应于维度中两个元素之间的位置差异。
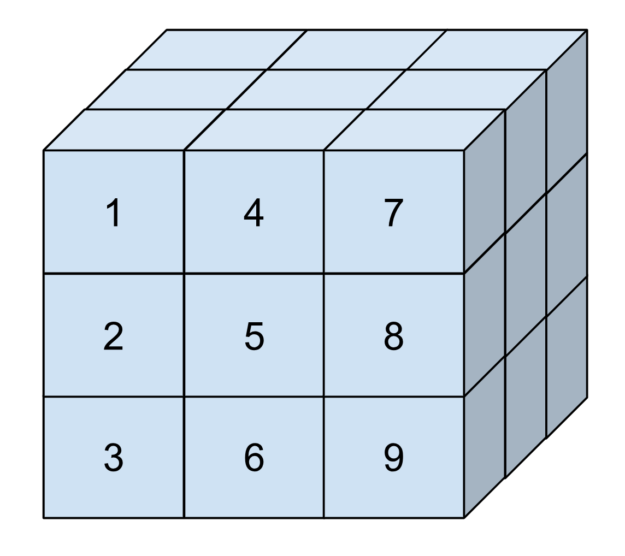
步长允许您表示子张量(由更大的张量切片构成的张量)。在 cuTENSOR 中,步长始终以元件为单位提供,就像极限一样。
例如,如要表示图中的张量,您可以调用以下代码:
int64_t extents[] = {3, 3, 3};
int64_t strides[] = {1, 3, 9};
uint32_t alignment = 256; // bytes (default of cudaMalloc)
cutensorTensorDescriptor_t tensor_desc;
status = cutensorCreateTensorDescriptor(handle, tensor_desc,
3 /*num_modes*/,
extents, strides,
CUTENSOR_R_32F, alignment);
您还可以传递 NULL 指针,而不是步长。在这种情况下,cuTENSOR 会自动从极限范围中推理步长,假设是通用列式内存布局。即,步长从左到右增加,最左侧模式的步长为 1.任何其他布局,包括通用行式布局,均可通过提供适当的步长实现。
步长还可用于访问子张量。例如,以下代码示例用于编码前一张量的二维非连续水平面:
int64_t extents_slice[] = {3, 3};
int64_t strides_slice[] = {3, 9};
status = cutensorCreateTensorDescriptor(handle, tensor_desc,
2 /*num_modes*/,
extents_slice, strides,
CUTENSOR_R_32F, alignment);
Einsum 符号
cuTENSOR 的元素化、归约和收缩 API 遵循 Einsum 符号,每个维度都有一个独特的标签。通过重排或省略模式,可以以用户友好的方式表示张量运算,如转置和收缩。未在输出中出现的模式会被收缩。有关更多信息,请参阅 PyTorch 文档中的 torch.einsum 。
例如,对于存储在 GPU 上的四维张量, 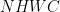

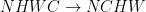
前面的字母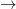
同样,矩阵-矩阵乘法可以表示为 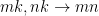

收缩
张量收缩可以看作是矩阵-矩阵乘法的更高维度版本。唯一的区别是操作数是多维矩阵,而不仅仅是二维矩阵。有关详细方程式,请参阅 cuTENSOR 函数。
在本文中,我们使用张量收缩示例展示了 cuTENSOR API 的使用方法 操作。但其他 API 的行为类似。从开始到结束,执行此操作需要执行以下步骤:
- 创建操作描述符。
- 创建计划首选项。
- 查询工作空间大小。
- 制定计划。
- (可选) 查询精确的工作空间大小使用情况。
- 执行收缩。
创建操作描述符
如前所述,您首先要创建张量描述符。完成此步骤后,继续对实际收缩执行编码:
cutensorComputeDescriptor_t descCompute = CUTENSOR_COMPUTE_DESC_32F;
cutensorOperationDescriptor_t desc;
cutensorCreateContraction(handle, &desc,
descA, {‘a’,’b’,’k’}, /* unary op A*/ CUTENSOR_OP_IDENTITY,
descB, {‘m’,’k’,’n’}, /* unary op B*/ CUTENSOR_OP_IDENTITY,
descC, {‘m’,’a’,’n’,’b’}, /* unary op C*/ CUTENSOR_OP_IDENTITY,
descC, {‘m’,’a’,’n’,’b’},
descCompute)
代码示例会对两个三维输入进行张量收缩,以创建四维输出;。API 与相应的 einsum 符号类似:
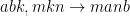
性能准则
本节假设是一种通用的列式数据布局,其中最左侧模式的步长最小。
虽然 cuTENSOR 可以使用任何顺序提供的模式,但顺序可能会影响性能。我们通常推荐以下性能准则:
- 尝试在所有张量中以类似的方式排列模式 (即增加步长)。例如,
而不是
.。
- 尽量将批处理模式保留为最慢变化模式 (即最大步长)。例如,
而不是
。
- 尽可能保持最快变化模式的范围 (s试用一次模式) 尽可能大。
创建计划首选项
下一步是通过创建cutensorPlanPreferrence_t例如,您可以使用 plan_preference 修复cutensorAlgo_t指定具体核函数,如果您希望实现自动调整或启用即时编译,
cutensorAlgo_t algo = CUTENSOR_ALGO_DEFAULT;
cutensorJitMode_t jitMode = CUTENSOR_JIT_MODE_NONE;
cutensorPlanPreference_t planPref;
cutensorCreatePlanPreference(handle,
&planPref,
algo, jitMode);
使用此计划首选项创建的任何计划都依赖于 cuTENSOR 性能模型来选择最适合的预编译内核:CUTENSOR_ALGO_DEFAULT.在本例中,您已禁用 JIT 编译。
正如之前所述,JIT 编译可以在运行时为特定操作生成专用内核,从而显著提高性能。要利用 cuTENSOR JIT 功能,请设置 jitMode = CUTENSOR_JIT_MODE_DEFAULT。有关更多信息,请参阅JIT 编译和性能详细介绍。
查询工作空间大小
现在,您已初始化收缩描述符并创建计划优先级,您可以使用cutensorEstimateWorkspaceSize.
借助 API,您可以通过cutensorWorksizePreference_t. CUTENSOR_WORKSPACE_DEFAULT是一个很好的默认值,因为它旨在实现高性能,同时减少工作空间要求。如果内存占用空间不是问题,则CUTENSOR_WORKSPACE_MAX可能是更好的选择。
uint64_t workspaceSizeEstimate = 0;
cutensorWorksizePreference_t workspacePref = CUTENSOR_WORKSPACE_DEFAULT;
cutensorEstimateWorkspaceSize(handle,
desc,
planPref,
workspacePref,
&workspaceSizeEstimate);
制定计划
下一步是创建实际计划,它编码了操作的执行,并选择核函数。这一步涉及查询 cuTENSOR 性能模型,通常是设置阶段的最耗时步骤。因此,自 cuTENSOR 2.0.0 开始,它将在用户控制的缓存中自动缓存。有关更多信息,请参阅计划缓存和增量自动调整详细介绍。
创建计划也是如果启用的话,会导致内核即时编译的步骤。
cutensorPlan_t plan;
cutensorCreatePlan(handle, &plan, desc, planPref, workspaceSizeEstimate);
cutensorCreatePlan接受工作空间大小限制作为输入 (在本例中,workspaceSizeEstimate) 并确保创建的计划不超过此限制。
(可选) 查询精确的工作空间大小使用情况
从 cuTENSOR 2.0.0 开始,您可以查询创建的计划,以了解其实际使用的工作空间大小。虽然这一步可选,但我们建议您执行此步骤,以减少所需的工作空间大小。
uint64_t actualWorkspaceSize = 0;
cutensorPlanGetAttribute(handle,
plan,
CUTENSOR_PLAN_REQUIRED_WORKSPACE,
&actualWorkspaceSize,
sizeof(actualWorkspaceSize));
执行收缩
剩下的工作是执行收缩运算,并提供 GPU 需要访问的数据指针。关于数据如何在主机上保留的更多信息,请参阅 使用 NVIDIA cuTENSORMg 扩展块周期张量以支持多 GPU。
cutensorContract(handle,
plan,
(void*) α, A_d, B_d,
(void*) β, C_d, C_d,
work, actualWorkspaceSize, stream);
元素化运算
元素级别 操作是 cuTENSOR 中最简单的操作。元素级别其中参与者张量的大小不会降低任何方式。换句话说,您可以按元素级别执行操作。常见的元素级别操作包括复制张量、重排序张量、加法张量或元素级别乘法张量 (也称为哈达姆德乘法)。
根据输入张量的数量,cuTENSOR 提供三个元素级 API:
- cutensorCreatePermute 创建一个输入张量
- cutensorCreateElementwiseBinary 创建两个输入张量的元素级二元运算。
- cutensorCreateElementwiseTrinary 创建一个三元运算操作,该操作作用于三个输入张量。
例如,考虑一个 permutation。在这种情况下,张量 A (源) 和张量 B (目标) 是 rank-4 张量,您可以将其模式从NHWC扩展至NCHW.操作描述符的创建可以通过以下方式实现,与上一节中的步骤 1 和 6 相比较。
float alpha = 1.0f;
cutensorOperator_t op = CUTENSOR_OP_IDENTITY;
cutensorComputeDescriptor_t descCompute = CUTENSOR_COMPUTE_DESC_32F;
cutensorOperationDescriptor_t permuteDesc;
status = cutensorCreatePermutation(handle, &permuteDesc,
α, descA, {‘N’, ‘H’, ‘W’, ‘C’}, op,
descB, {‘N’, ‘C’, ‘H’, ‘W’},
descCompute, stream);
// next stages (such as plan creation) omitted …
cutensorPermute(handle, plan, α, A_d, C_d, nullptr /* stream */));
此代码示例仅突出了与前一个收缩示例的不同之处。除了创建操作描述符和实际执行之外,所有阶段均与收缩相同。唯一的例外是元素式运算不需要任何工作空间。
cuTENSOR 2.0 还提供了对张量重排序输出张量进行填充的支持。如果需要满足对齐要求,例如启用向量化加载,这可能非常有用。
以下代码示例详细介绍了如何使用零填充输出张量。具体来说,第四个模式的左侧和右侧各添加一个填充元,其余模式均未填充。
cutensorOperationDescriptorSetAttribute(handle, permuteDesc,
CUTENSOR_OPERATION_DESCRIPTOR_PADDING_RIGHT,
{0,0,0,1},
sizeof(int) * 4));
cutensorOperationDescriptorSetAttribute(handle, permuteDesc,
CUTENSOR_OPERATION_DESCRIPTOR_PADDING_LEFT,
{0,0,0,1},
sizeof(int) * 4));
float paddingValue = 0.f;
cutensorOperationDescriptorSetAttribute(handle, permuteDesc,
CUTENSOR_OPERATION_DESCRIPTOR_PADDING_VALUE,
&paddingValue, sizeof(paddingValue));
有关更多信息以及完全功能的填充示例,请参阅 /NVIDIA/CUDALibrarySamples GitHub 资源库。
归约
cuTENSOR张量归约操作 接受单个张量作为输入,并使用归约运算(如求和、乘法、最大值或最小值)来减少张量的维度。有关更多信息,请参阅 cutensorOperator-t.
与收缩和元素化运算类似,张量归约也使用相同的多阶段 API。此 API 示例仅限于不同之处。
cutensorOperationDescriptor_t desc;
cutensorOperator_t opReduce = CUTENSOR_OP_ADD;
cutensorCreateReduction(handle, &desc,
descA, {‘a’, ‘b’, ‘c’}, CUTENSOR_OP_IDENTITY,
descC, {‘b’, ‘a’,}, CUTENSOR_OP_IDENTITY,
descC, {‘b’, ‘a’,},
opReduce, descCompute);
// next stages (such as plan creation) omitted …
cutensorReduce(handle, plan,
(const void*)α, A_d,
(const void*)β, C_d,
C_d,
work, actualWorkspaceSize, stream);
输入张量不一定要完全归约为一个标量,但某些模式仍然可以保留。此外,模式的确切顺序没有任何限制,这有效地将转换和归约融合到一个内核中。例如,张量归约不仅缩短了
也会改变剩余模式的顺序。
即时编译
正如我们在优化cuTENSOR 2.0 中所介绍的,我们引入了对张量收缩的即时编译支持,以便在运行时为特定的张量收缩提供专用的核函数。这对于处理高维张量收缩等具有挑战性的任务特别有价值,因为预构建的核函数可能不够丰富。
启用即时编译可通过传递CUTENSOR_JIT_MODE_DEFAULT扩展至cutensorCreatePlanPreference 相应的张量收缩运算。
cutensorAlgo_t algo = CUTENSOR_ALGO_DEFAULT;
cutensorJitMode_t jitMode = CUTENSOR_JIT_MODE_DEFAULT;
cutensorPlanPreference_t planPref;
cutensorCreatePlanPreference(handle,
&planPref,
algo, jitMode);
然后使用 NVIDIA nvrtc 编译器进行 CUDA C++编译,并在第一次调用 cutensorCreatePlan 时运行时编译内核。成功编译的内核会被自动添加到内部内核缓存中,这样任何后续调用相同的操作描述符和计划优先级只会导致缓存查询,而不是重新编译。
为了进一步减少即时编译的开销,cuTENSOR 提供了 cutensorReadKernelCacheFromFile 和 cutensorWriteKernelCacheToFile,允许您读取和写入内部内核缓存到文件,以便在多个程序执行中重复使用。
cutensorReadKernelCacheFromFile(handle, "kernelCache.bin");
// execution (possibly with JIT-compilation enabled) omitted…
cutensorWriteKernelCacheToFile(handle, "kernelCache.bin");
For more information, please see the Just-In-Time Compilation section.
计划缓存和增量自动调整
规划是最耗时的设置阶段,因为它会调用 cuTENSOR 性能模型。建议您存储规划并使用不同的数据指针多次重复使用。
然而,由于这种重复使用可能并不总是可行,或者在用户端实施时可能需要花费大量时间,因此 cuTENSOR 2.0 采用了默认激活的软件管理计划缓存。您仍然可以在 CUTENSOR_CACHE_MODE_NONE 操作级别上进行调整。
计划缓存可缩短cutensorCreatePlan速度提升了约 10 倍。
计划缓存采用最近使用 (LRU) 驱逐策略,其默认容量为 64 条记录。理想情况下,您希望缓存的容量与独特张量收缩的数量相同或更高 .cuTENSOR 提供以下选项来更改缓存容量:
int32_t numEntries = 128;
cutensorHandleResizePlanCachelines(&handle, numEntries);
与内核缓存类似,计划缓存也可以通过磁盘进行序列化,从而在不同的程序执行中重复使用:
uint32_t numCachelines = 0;
cutensorHandleReadPlanCacheFromFile(handle, "./planCache.bin", &numCachelines);
// execution (possibly with JIT-compilation enabled) omitted…
cutensorHandleWritePlanCacheToFile(handle, "./planCache.bin");
增量自动调整是计划缓存的选择性功能。它允许不同候选或核函数执行连续的相同操作,具有可能不同的数据指针。在探索用户定义的数量候选时,系统会存储速度最快的候选,以供特定操作使用。
与其他自动调整方法相比,使用计划缓存的增量自动调整具有以下优势:
- 从用户角度来看,它不需要对现有代码进行其他修改,除了启用该功能之外。此外,它还尽可能减少了测量开销,因为它不使用计时循环或同步。
- 候选内容在硬件缓存状态与生产环境相匹配的时刻进行评估。换句话说,硬件缓存状态反映了现实情况。
在计划首选项创建期间,可以启用增量自动调整,如下所示:
const cutensorAutotuneMode_t autotuneMode = CUTENSOR_AUTOTUNE_MODE_INCREMENTAL;
cutensorPlanPreferenceSetAttribute(
&handle,
&find,
CUTENSOR_PLAN_PREFERENCE_AUTOTUNE_MODE_MODE,
&autotuneMode ,
sizeof(cutensorAutotuneMode_t));
// Optionally, also set the maximum number of candidates to explore
const uint32_t incCount = 4;
cutensorPlanPreferenceSetAttribute(
&handle,
&find,
CUTENSOR_PLAN_PREFERENCE_INCREMENTAL_COUNT,
&incCount,
sizeof(uint32_t));
有关 cuTENSOR 的计划缓存和增量自动调整功能的更多信息,请参阅 计划缓存文档。
多 GPU 支持
有关更多信息,请参阅 利用 NVIDIA cuTENSORMg 扩展块周期张量,实现多 GPU 支持。
总结
在处理密集张量时,cuTENSOR 提供了一个全面的例程集合,使您作为 CUDA 开发者的生活更加轻松,并且不必担心低级别性能优化。许多您想要应用到张量的算法都可以使用现有的 cuTENSOR 例程来表达。
作为 CUDA 库用户,您还可以从任何未来的 NVIDIA 架构和其他性能改进中受益,因为我们不断优化 cuTENSOR 库。
有关更多信息,请参阅 cuTENSOR 2.0:应用程序和性能。
开始使用 cuTENSOR 2.0
开始使用 cuTENSOR 2.0。
深入了解 cuTENSOR 2.0,并在开发者论坛中讨论。




