
대규모 언어 모델(LLM)은 데이터 사이언스에 혁명을 일으키며 자연어 이해, AI, 머신 러닝의 고급 기능을 가능하게 합니다. 도메인별 인사이트에 맞게 조정된 맞춤형 LLM은 엔터프라이즈 애플리케이션에서 점점 더 많은 관심을 받고 있습니다.
NVIDIA Nemotron-3 8B 파운데이션 모델 제품군은 엔터프라이즈용 프로덕션 지원 생성형 AI 애플리케이션을 구축하기 위한 강력하고 새로운 도구로, 고객 서비스 AI 챗봇부터 최첨단 AI 제품까지 다양한 혁신을 촉진합니다.
이러한 새로운 파운데이션 모델은 기업용으로 맞춤화된 LLM을 구축, 커스터마이징 및 배포하기 위한 엔드투엔드 프레임워크인 NVIDIA NeMo에 합류합니다. 이제 기업들은 이러한 툴을 사용하여 AI 애플리케이션을 빠르고 비용 효율적으로 대규모로 개발할 수 있습니다. 이러한 애플리케이션은 클라우드, 데이터 센터, Windows 데스크톱 및 노트북 컴퓨터에서 실행할 수 있습니다.
Nemotron-3 8B 제품군은 Azure AI 모델 카탈로그, HuggingFace 및 NVIDIA NGC 카탈로그의 NVIDIA AI 파운데이션 모델 허브에서 사용할 수 있습니다. 여기에는 다양한 다운스트림 작업을 해결하도록 설계된 기본, 채팅 및 질의응답(Q&A) 모델이 포함되어 있습니다. 표 1은 전체 파운데이션 모델 제품군을 보여줍니다.
| 모델 | 변수 | 주요 이점 |
Base | Nemotron-3-8B-Base | 파라미터를 효율적으로 미세 조정하고 도메인에 맞게 조정된 LLM을 위한 지속적인 사전 교육을 포함한 맞춤형 설정이 가능합니다. |
Chat | Nemotron-3-8B-Chat-SFT | 인스트럭션 튜닝 커스텀 모델 또는 사용자 맞춤 정렬(예: RLHF 또는 SteerLM 모델)을 위한 빌딩 블록입니다. |
| Nemotron-3-8B-Chat-RLHF | 즉시 사용 가능한 최고의 채팅 모델 성능 | |
| Nemotron-3-8B-Chat-SteerLM | 추론 시점에 유연하게 조정할 수 있는 최고의 기본 제공 채팅 모델 | |
| Question-and- Answer | Nemotron-3-8B-QA | 지식 기반에 맞춤화된 Q&A LLM |
프로덕션용 파운데이션 모델 설계
파운데이션 모델은 유용한 맞춤형 애플리케이션을 구축하는 데 필요한 시간과 리소스를 줄여주는 강력한 빌딩 블록입니다. 그러나 조직은 이러한 모델이 엔터프라이즈 요구 사항을 충족하는지 확인해야 합니다.
NVIDIA AI 파운데이션 모델은 책임감 있게 소싱된 데이터 세트를 기반으로 학습되어 수많은 목소리와 경험을 캡처합니다. 엄격한 모니터링을 통해 데이터 충실도를 높이고 진화하는 법적 규정을 준수합니다. 발생하는 모든 데이터 문제를 신속하게 해결하여 기업이 법적 규범과 사용자 개인정보 보호를 모두 준수하는 AI 애플리케이션으로 무장할 수 있도록 합니다. 이러한 모델은 공개적으로 사용 가능한 데이터 세트와 독점 데이터 세트를 모두 통합할 수 있습니다.
Nemotron-3-8B 베이스
Nemotron-3-8B 베이스(base) 모델은 사람과 유사한 텍스트 또는 코드를 생성하기 위한 컴팩트한 고성능 모델입니다. 이 모델의 MMLU 5샷 평균은 54.4입니다. 또한 이 베이스 모델은 영어, 독일어, 러시아어, 스페인어, 프랑스어, 일본어, 중국어, 이탈리아어, 네덜란드어 등 53개 언어에 능통하여 다국어 능력을 갖춘 글로벌 기업의 요구 사항을 충족합니다. 이 베이스 모델은 37개 코딩 언어에 대해서도 학습되어 있습니다.
Nemotron-3-8B 채팅
이 제품군에 추가된 Nemotron-3-8B 채팅(chat) 모델은 LLM 기반 챗봇 상호작용을 대상으로 합니다. 세 가지 채팅 모델 버전이 있으며, 각각 고유한 사용자별 조정을 위해 설계되었습니다:
- 감독된 미세 조정(SFT)
- 사람의 피드백을 통한 강화 학습(RLHF)
- NVIDIA SteerLM
Nemotron-3-8B-SFT 모델은 인스트럭트 튜닝의 첫 번째 단계로, 채팅 품질에 대해 가장 많이 인용되는 지표인 8B 범주 내에서 가장 높은 MT-Bench 점수를 가진 RLHF 모델을 구축합니다. 최상의 즉각적인 채팅 상호 작용을 위해 8B-chat-RLHF로 시작하는 것이 좋지만, 최종 사용자의 선호도에 맞게 고유하게 정렬하는 데 관심이 있는 기업에게는 자체 RLHF를 적용하면서 SFT 모델을 사용하는 것을 권장합니다.
마지막으로, 최신 정렬 방법인 SteerLM은 추론 시 LLM을 학습하고 사용자 지정할 수 있는 새로운 수준의 유연성을 제공합니다. SteerLM을 사용하면 사용자가 원하는 모든 속성을 정의하고 이를 단일 모델에 포함시킬 수 있습니다. 그런 다음 모델이 실행되는 동안 특정 사용 사례에 필요한 조합을 선택할 수 있습니다.
이 방법을 사용하면 지속적인 개선 주기를 유지할 수 있습니다. 사용자 맞춤화 모델의 응답은 향후 트레이닝 실행을 위한 데이터로 사용되어 모델을 새로운 수준의 유용성으로 끌어올릴 수 있습니다.
Nemotron-3-8B 질문과 답변
Nemotron-3-8B-QA 모델은 대상 사용 사례에 초점을 맞춘 대량의 데이터를 기반으로 미세 조정된 질의응답(QA) 모델입니다.
Nemotron-3-8B-QA 모델은 자연 질문 데이터 세트에서 41.99%의 제로 샷 F1 점수를 달성하는 등 최첨단 성능을 제공합니다. 이 지표는 생성된 답변이 QA에서 진실과 얼마나 유사한지를 측정합니다.
Nemotron-3-8B-QA 모델은 파라미터 크기가 더 큰 다른 최신 언어 모델과 비교하여 테스트되었습니다. 이 테스트는 NVIDIA에서 생성한 데이터 세트와 자연어 질문 및 Doc2Dial 데이터 세트에 대해 수행되었습니다. 테스트 결과 이 모델이 우수한 성능을 발휘하는 것으로 나타났습니다.
NVIDIA NeMo 프레임워크로 맞춤형 LLM 구축하기
NVIDIA NeMo는 여러 모델 아키텍처를 위한 엔드투엔드 기능과 컨테이너화된 레시피를 제공하여 맞춤형 엔터프라이즈 생성형 AI 모델을 구축하는 경로를 간소화합니다. 개발자는 Nemotron-3-8B 모델 제품군을 통해 특정 사용 사례에 맞게 쉽게 조정할 수 있는 NVIDIA의 사전 학습된 모델에 액세스할 수 있습니다.
빠른 모델 배포
NeMo 프레임워크를 사용하면 데이터를 수집하거나 인프라를 설정할 필요가 없습니다. NeMo는 프로세스를 간소화합니다. 개발자는 기존 모델을 커스터마이즈하여 프로덕션 환경에 빠르게 배포할 수 있습니다.
최적의 모델 성능
또한 모델 성능을 최적화하는 NVIDIA TensorRT-LLM 오픈 소스 라이브러리와 추론 제공 프로세스를 가속화하는 NVIDIA Triton 추론 서버와도 원활하게 통합됩니다. 이러한 툴의 조합을 통해 최첨단 정확도, 짧은 지연 시간, 높은 처리량을 구현할 수 있습니다.
데이터 개인 정보 보호 및 보안
NeMo는 안전 및 보안 규정을 준수하는 안전하고 효율적인 대규모 배포를 지원합니다. 예를 들어, 데이터 개인정보 보호가 비즈니스의 주요 관심사인 경우 NeMo 가드레일을 사용하여 성능이나 안정성을 저하시키지 않으면서 고객 데이터를 안전하게 저장할 수 있습니다.
전반적으로 NeMo 프레임워크로 커스텀 LLM을 구축하는 것은 품질이나 보안 표준을 희생하지 않고 엔터프라이즈 AI 애플리케이션을 빠르게 제작할 수 있는 효과적인 방법입니다. 개발자에게 커스터마이징 측면에서 유연성을 제공하는 동시에 대규모로 빠르게 배포하는 데 필요한 강력한 도구를 제공합니다.
Nemotron-3-8B 시작하기
Nemotron-3-8B 모델에서 추론을 쉽게 실행할 수 있는 NeMo 프레임워크는 NVIDIA GPU에서 효율적이고 쉬운 LLM 추론을 위한 고급 최적화를 제공하는 오픈 소스 라이브러리인 TensorRT-LLM을 활용합니다. 다음과 같은 다양한 최적화 기법을 기본으로 지원합니다:
- KV 캐싱
- 효율적인 어텐션 모듈(MQA, GQA, 페이징 어텐션 포함)
- 인플라이트(또는 연속) 배칭
- 저정밀(INT8/FP8) 정량화 등 다양한 최적화 지원.
NeMo 프레임워크 추론 컨테이너에는 Nemotron-3-8B 제품군과 같은 NeMo 모델에 TensorRT-LLM 최적화를 적용하고 Triton 추론 서버로 이를 호스팅하는 데 필요한 모든 스크립트와 종속성이 포함되어 있습니다. 배포하면 추론 쿼리를 보낼 수 있는 엔드포인트가 노출됩니다.
전제 조건
지침에 따라 배포 및 추론하려면 다음에 액세스할 수 있어야 합니다:
- NVIDIA 데이터센터 GPU: 최소 (1) A100 – 40GB/80GB, (2) H100 – 80GB 또는 (3) L40S.
- NVIDIA NeMo 프레임워크: Nemotron-3-8B 모델 제품군을 사용자 지정하거나 배포할 수 있는 트레이닝 및 추론 컨테이너를 모두 제공합니다.
Azure ML 배포 단계
Nemotron-3-8B 제품군의 모델은 Azure ML 관리형 엔드포인트에 배포하기 위해 Azure ML 모델 카탈로그에서 사용할 수 있습니다. AzureML은 사용하기 쉬운 ‘코드 없는 배포’ 플로우 햇(flow hat)을 제공하여 Nemotron-3-8B 제품군 모델을 매우 쉽게 배포할 수 있습니다. NeMo 프레임워크 추론 컨테이너인 기본 배관은 플랫폼 내에 통합되어 있습니다.
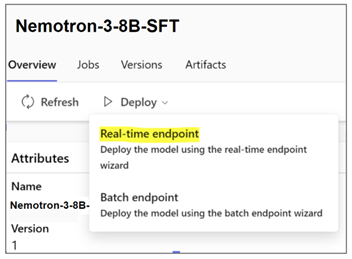
추론을 위해 Azure ML에 NVIDIA 파운데이션 모델을 배포하려면 다음 단계를 따르세요:
- Azure 계정에 로그인: https://portal.azure.com/#home
- Azure ML 머신 러닝 스튜디오로 이동합니다.
- 작업 공간을 선택하고 모델 카탈로그로 이동합니다.
NVIDIA AI 파운데이션 모델은 Azure에서 미세 조정, 평가 및 배포에 사용할 수 있습니다. 모델 커스터마이징은 NeMo 트레이닝 프레임워크를 사용하여 Azure ML 내에서 수행할 수 있습니다. 트레이닝 및 추론 컨테이너로 구성된 NeMo 프레임워크는 이미 AzureML 내에 통합되어 있습니다.
기본 모델을 미세 조정하려면 원하는 모델 변형을 선택하고 ‘미세 조정’을 클릭한 다음 작업 유형, 사용자 지정 학습 데이터, 학습 및 유효성 검사 분할, 컴퓨팅 클러스터와 같은 매개 변수를 입력합니다.
모델을 배포하려면 원하는 모델 변형을 선택하고 ‘실시간 엔드포인트’를 클릭한 다음 인스턴스, 엔드포인트 및 기타 파라미터를 선택하여 배포를 사용자 지정합니다. 배포를 클릭하여 엔드포인트에 추론을 위한 모델을 배포합니다.
Azure ML에서 미세 조정 작업 및 배포를 실행하기 위해 Azure CLI 및 SDK 지원도 사용할 수 있습니다. 자세한 내용은 Azure ML 설명서의 파운데이션 모델을 참조하세요.
온-프레미스 또는 다른 클라우드에 배포하기 위한 단계
Nemotron-3-8B 제품군의 모델에는 모범 사례로 권장되는 추론 요청에 대한 고유한 프롬프트 템플릿이 있지만, 동일한 기본 아키텍처를 공유하므로 배포 지침은 유사합니다.
NeMo 프레임워크 추론 컨테이너를 사용하는 최신 배포 지침은 https://registry.ngc.nvidia.com/orgs/ea-bignlp/teams/ga-participants/containers/nemofw-inference 을 참조하세요.
데모를 위해 Nemotron-3-8B-Base-4k를 배포해 보겠습니다.
1. NGC 카탈로그에 로그인하고 추론 컨테이너를 가져옵니다.
# log in to your NGC organization
docker login nvcr.io
# Fetch the NeMo framework inference container
docker pull nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.102. Nemotron-3-8B-Base-4k 모델 다운로드. 8B 모델 제품군은 NGC 카탈로그와 Hugging Face에서 사용할 수 있습니다. 두 곳 중 한 곳에서 모델을 다운로드할 수 있습니다.
NVIDIA NGC
NGC에서 모델을 다운로드하는 가장 쉬운 방법은 CLI를 사용하는 것입니다. NGC CLI가 설치되어 있지 않은 경우 시작하기 지침에 따라 설치 및 구성합니다.
# Downloading using CLI. The model path can be obtained from it’s page on NGC
ngc registry model download-version "dztrnjtldi02/nemotron-3-8b-base-4k:1.0"Hugging Face 허브
다음 명령은 git-lfs를 사용하지만 허깅 페이스에서 지원하는 모든 방법을 사용하여 모델을 다운로드할 수 있습니다.
git lfs install
git clone https://huggingface.co/nvidia/nemotron-3-8b-base-4knemotron-3-8b-base-4k_v1.03. 대화형 모드에서 NeMo 추론 컨테이너를 실행하여 관련 경로를 로드합니다.
# Create a folder to cache the built TRT engines. This is recommended so they don’t have to be built on every deployment call.
mkdir -p trt-cache
# Run the container, mounting the checkpoint and the cache directory
docker run --rm --net=host \
--gpus=all \
-v $(pwd)/nemotron-3-8b-base-4k_v1.0:/opt/checkpoints/ \
-v $(pwd)/trt-cache:/trt-cache \
-w /opt/NeMo \
-it nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10 bash4. 모델을 변환하고 TensorRT-LLM 백엔드를 사용하여 Triton 추론 서버에 배포합니다.
python scripts/deploy/deploy_triton.py \
--nemo_checkpoint /opt/checkpoints/Nemotron-3-8B-Base-4k.nemo \
--model_type="gptnext" \
--triton_model_name Nemotron-3-8B-4K \
--triton_model_repository /trt-cache/ \
--max_input_len 3000 \
--max_output_len 1000 \
--max_batch_size 2이 명령이 성공적으로 완료되면 쿼리할 수 있는 엔드포인트가 노출됩니다. 이를 수행하는 방법을 살펴보겠습니다.
추론 실행 단계
서비스를 통합하려는 방식에 따라 추론을 실행하는 데 사용할 수 있는 몇 가지 옵션이 있습니다:
- NeMo 프레임워크 추론 컨테이너에서 사용할 수 있는 NeMo 클라이언트 API 사용
- PyTriton을 사용하여 사용자 환경에서 클라이언트 앱 만들기
- 배포된 서비스가 HTTP 엔드포인트를 노출하므로 HTTP 요청을 보낼 수 있는 라이브러리/도구 사용.
옵션 1의 예시인 NeMo 클라이언트 API 사용은 다음과 같습니다. 동일한 머신 또는 서비스 IP 및 포트에 액세스할 수 있는 다른 머신의 NeMo 프레임워크 추론 컨테이너에서 이 방법을 사용할 수 있습니다.
from nemo.deploy import NemoQuery
# In this case, we run inference on the same machine
nq = NemoQuery(url="localhost:8000", model_name="Nemotron-3-8B-4K")
output = nq.query_llm(prompts=["The meaning of life is"], max_output_token=200, top_k=1, top_p=0.0, temperature=0.1)
print(output)다른 옵션의 예는 추론 컨테이너의 README에서 확인할 수 있습니다.
참고: 채팅 모델(SFT, RLHF 및 SteerLM)은 “”로 응답을 종료하도록 학습되었기 때문에 출력에 대한 사후 처리가 필요하지만, NemoQuery API는 아직 이 특수 토큰이 생성될 때 자동으로 생성을 중지하는 기능을 지원하지 않습니다. 이는 다음과 같이 output을 수정하면 가능합니다:
output = nq.query_llm(...)
output = [[s.split("<extra_id_1>", 1)[0].strip() for s in out] for out in output]8B 모델 제품군 소개
NVIDIA Nemotron-3-8B 제품군의 모델은 사전 학습된 공통 기반을 공유합니다. 그러나 채팅을 조정하는 데 사용되는 데이터 세트(SFT, RLHF, SteerLM) 및 QA 모델은 특정 목적에 맞게 사용자 지정됩니다. 또한 이러한 모델을 구축하는 데는 서로 다른 훈련 기법이 사용됩니다. 따라서 이러한 모델은 훈련된 방식과 유사한 템플릿을 따르는 맞춤형 프롬프트를 사용하는 것이 가장 효과적입니다.
이러한 모델에 권장되는 프롬프트 템플릿은 각 모델 카드에서 찾을 수 있습니다.
예를 들어, 다음은 Nemotron-3-8B-Chat-SFT 및 Nemotron-3-8B-Chat-RLHF 모델에 적용할 수 있는 단일 턴 및 다중 턴 형식입니다:
| Nemotron-3-8B-Chat-SFT and Nemotron-3-8B-Chat-RLHF | |
| 단일 턴 프롬프트 | 멀티 턴 또는 소수 샷 |
<extra_id_0>System | <extra_id_0>System |
프롬프트 및 응답 필드는 입력할 위치에 해당합니다. 다음은 단일 턴 템플릿을 사용하여 입력 서식을 지정하는 예시입니다.
PROMPT_TEMPLATE = """<extra_id_0>System
{system}
<extra_id_1>User
{prompt}
<extra_id_1>Assistant
"""
system = ""
prompt = "Write a poem on NVIDIA in the style of Shakespeare"
prompt = PROMPT_TEMPLATE.format(prompt=prompt, system=system)
print(prompt)참고: Nemotron-3-8B-Chat-SFT 및 Nemotron-3-8B-Chat-RLHF 모델의 경우, 시스템 프롬프트를 비워 두는 것이 좋습니다.
추가 교육 및 사용자 맞춤화
NVIDIA Nemotron-3-8B 모델 제품군은 도메인별 데이터 세트에 대한 추가 사용자 정의에 적합합니다. 이를 위한 몇 가지 옵션이 있는데, 체크포인트를 통한 지속적인 사전 훈련, SFT 또는 매개변수 효율적 미세 조정, RLHF를 사용한 인간 데모에 대한 정렬 또는 NVIDIA의 새로운 SteerLM 기술 사용 등이 있습니다.
앞서 언급한 기법에 대한 사용하기 쉬운 스크립트는 NeMo 프레임워크 트레이닝 컨테이너에 있습니다. 또한 데이터 큐레이션, 트레이닝 및 추론을 위한 최적의 하이퍼파라미터 식별, 온프레미스 DGX 클라우드, 쿠버네티스 지원 플랫폼 또는 클라우드 서비스 제공업체 등 원하는 하드웨어에서 NeMo 프레임워크를 실행하기 위한 도구도 제공합니다.
자세한 내용은 NeMo 프레임워크 사용 가이드 또는 컨테이너 README를 참조하세요.
Nemotron-3-8B 모델 제품군은 다양한 사용 사례를 위해 설계되었으며, 다양한 벤치마크에서 경쟁력 있는 성능을 발휘할 뿐만 아니라 여러 언어를 지원합니다.
직접 사용해 보시고 댓글로 의견을 남겨 주세요.
관련 리소스
- DLI 과정: 대화형 AI 애플리케이션 구축하기
- GTC 세션: AI 워크플로우로 AI 솔루션 개발 가속화하기
- GTC 세션: NVIDIA NeMo 서비스 | 맞춤형 생성형 AI 모델로 엔터프라이즈 생산성 향상
- SDK: NeMo
- 웨비나: 대규모 언어 모델 구현하기
- 웨비나: AI 팀이 생성형 AI에 대해 알아야 할 사항