
동급 최고의 AI 성능을 위해서는 효율적인 병렬 컴퓨팅 아키텍처, 생산적인 툴 스택, 고도로 최적화된 알고리즘이 필요합니다. NVIDIA는 NVIDIA H100 Tensor 코어 GPU의 핵심인 NVIDIA Hopper 아키텍처를 위한 최신 커널 최적화가 포함된 오픈 소스 NVIDIA TensorRT-LLM을 출시했습니다. 이러한 최적화를 통해 Llama 2 70B와 같은 모델은 추론 정확도를 유지하면서 H100 GPU에서 가속화된 FP8 연산을 사용하여 실행할 수 있습니다.
최근 런칭 이벤트에서 AMD는 H100 GPU의 추론 성능과 MI300X 칩의 추론 성능을 비교했습니다. 공유된 결과는 최적화된 소프트웨어를 사용하지 않았으며, 제대로 벤치마크했을 경우 H100이 2배 더 빠릅니다.
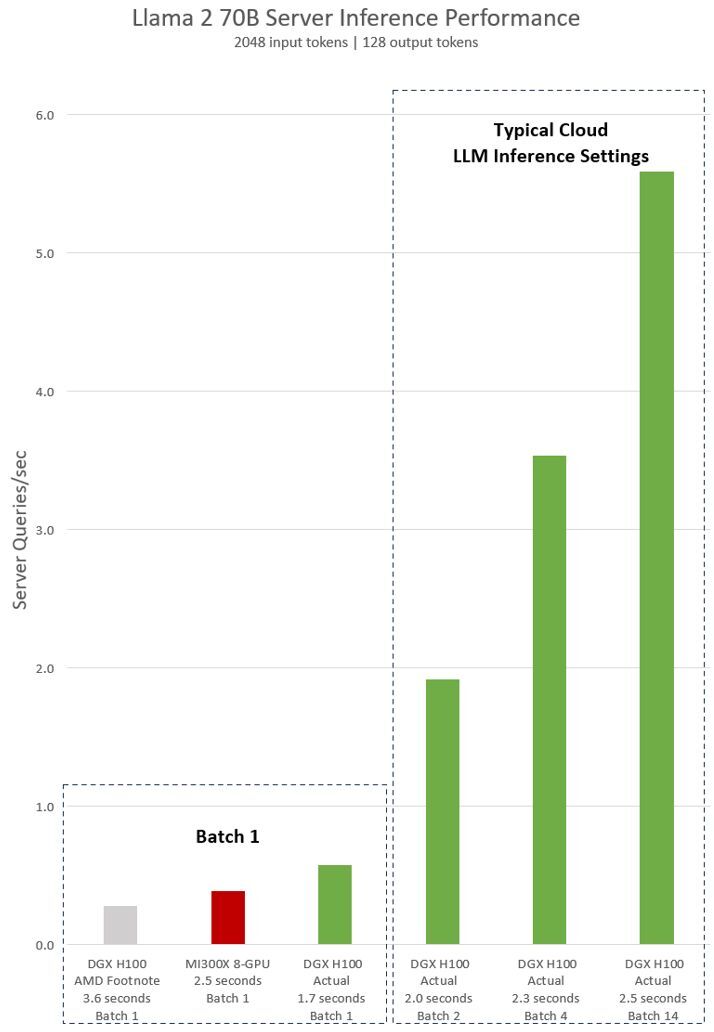
다음은 Llama 2 70B 모델에서 8개의 NVIDIA H100 GPU가 장착된 단일 NVIDIA DGX H100 서버의 실제 측정된 성능입니다. 여기에는 추론 요청이 한 번에 하나씩 처리되는 ‘Batch-1’의 결과와 고정 응답 시간 처리를 사용한 결과가 모두 포함됩니다.
AMD의 H100에 대한 주장은 AMD의 발표 자료 주석 #MI300-38에서 측정된 구성을 기반으로 합니다. vLLM v.02.2.2 추론 소프트웨어와 NVIDIA DGX H100 시스템, 입력 시퀀스 길이 2,048, 출력 시퀀스 길이 128의 Llama 2 70B 쿼리를 사용했습니다. 8x GPU MI300X 시스템이 장착된 DGX H100과 비교하여 상대적으로 성능이 우수하다고 주장했습니다.
NVIDIA 측정 데이터의 경우, 공개적으로 사용 가능한 NVIDIA TensorRT-LLM, batch 1의 경우 v0.5.0, 지연 임계값 측정의 경우 v0.6.1이 적용된 80GB HBM3을 갖춘 8x NVIDIA H100 Tensor 코어 GPU가 장착된 DGX H100을 사용했습니다. 워크로드 세부 정보는 각주 #MI300-38과 동일합니다.
DGX H100은 batch 크기 1, 즉 한 번에 하나의 추론 요청을 사용하여 단일 추론을 1.7초 내에 처리할 수 있습니다. batch 크기가 1이면 모델을 제공할 때 가능한 가장 빠른 응답 시간을 얻을 수 있습니다. 응답 시간과 데이터 센터 처리량을 모두 최적화하기 위해 클라우드 서비스에서는 특정 서비스에 대해 고정 응답 시간을 설정합니다. 이를 통해 여러 추론 요청을 더 큰 ‘batch’로 결합하고 서버의 초당 전체 추론 수를 늘릴 수 있습니다. MLPerf와 같은 업계 표준 벤치마크도 이 고정 응답 시간 메트릭으로 성능을 측정합니다.
응답 시간을 조금만 조정해도 서버가 실시간으로 처리할 수 있는 추론 요청의 수가 크게 늘어날 수 있습니다. 2.5초의 고정 응답 시간 예산을 사용하는 8-GPU DGX H100 서버는 초당 5건 이상의 Llama 2 70B 추론을 처리할 수 있는 반면, batch 1을 사용하면 초당 1건 미만을 처리할 수 있습니다.
AI는 빠르게 발전하고 있으며, NVIDIA CUDA 에코시스템을 통해 스택을 신속하고 지속적으로 최적화할 수 있습니다. 저희는 소프트웨어를 업데이트할 때마다 AI 성능을 지속적으로 개선할 예정이니, 성능 페이지와 GitHub 사이트에서 최신 소식을 확인해 주세요.
이러한 AI 추론 결과를 재현하는 방법
그림 1의 DGX H100 AMD Footnote는 아래 vLLM 기반의 벤치마킹 스크립트및 명령어를 통해 AMD Footnote에서 제공한 구성을 기반으로 vLLM에서 NVIDIA에 의해 측정된 값입니다.
$ python benchmarks/benchmark_latency.py --model "meta-llama/Llama-2-70b-hf" --input-len 2048 --output-len 128 --batch-size 1 -tp 8MI300X 8-GPU은 DGX H100 AMD Footnote의 vLLM 결과 대비 AMD가 주장한 속도 향상을 기반으로 도출된 수치입니다.
DGX H100 Actual은 NVIDIA에서 GitHub에서 사용 가능한 공개 버전의 TensorRT-LLM을 사용하고 Llama 2용 TensorRT-LLM 벤치마킹 가이드에 안내된 명령어를 사용하여 측정된 값입니다.
// Build TensorRT optimized Llama-2-70b for H100 fp8 tensorcore
$ python examples/llama/build.py --remove_input_padding --enable_context_fmha --parallel_build --output_dir DTYPE.float16_TP.8_BS.14_ISL.2048_OSL.128 --dtype float16 --use_gpt_attention_plugin float16 --world_size 8 --tp_size 8 --pp_size 1 --max_batch_size 14 --max_input_len 2048 --max_output_len 128 --enable_fp8 --fp8_kv_cache --strongly_typed --n_head 64 --n_kv_head 8 --n_embd 8192 --inter_size 28672 --vocab_size 32000 --n_positions 4096 --hidden_act silu --ffn_dim_multiplier 1.3 --multiple_of 4096 --n_layer 80
// Benchmark Llama-70B
$ mpirun -n 8 --allow-run-as-root --oversubscribe ./cpp/build/benchmarks/gptSessionBenchmark --model llama_70b --engine_dir DTYPE.float16_TP.8_BS.14_ISL.2048_OSL.128 --warm_up 1 --batch_size 14 --duration 0 --num_runs 5 --input_output_len 2048,1;2048,128관련 리소스
- GTC 세션: Hopper Tensor 코어에서 최적의 CUDA 커널 개발
- GTC 세션: NVIDIA Triton 추론 서버를 사용한 대규모 언어 모델 추론(CoreWeave 제공)
- SDK: cuTENSOR
- SDK: cuTENSORMg
- SDK: TensorFlow-TensorRT
- 웨비나: TensorRT와 TRITON에 대해 자세히 알아보기