
거대 언어 모델(LLM)은 지난 한 해 동안 급격한 성장을 거듭했습니다. 뛰어난 사용자 경험을 제공하기 위해서는 높은 컴퓨팅 처리량과 대량의 고대역폭 메모리가 모두 필요한데요. NVIDIA TensorRT-LLM은 최대 처리량과 메모리 최적화 모두를 위한 최적화를 제공하여 LLM 추론 성능을 크게 향상시킵니다.
NVIDIA H200 GPU의 최신 TensorRT-LLM 개선 사항은 Llama 2 70B LLM에서 6.7배의 속도 향상을 제공하며, Falcon-180B와 같은 대규모 모델을 단일 GPU에서 실행할 수 있도록 지원합니다. Llama 2 70B의 가속화는 멀티 헤드 어텐션 기술의 확장인 그룹화된 쿼리 어텐션(GQA)이라는 기술을 최적화하는 데서 비롯되며, 이는 Llama 2 70B의 핵심 레이어입니다.
Falcon-180B는 현존하는 가장 크고 정확한 오픈 소스 대규모 언어 모델 중 하나로, 이전에는 이를 실행하기 위해 최소 8개의 NVIDIA A100 Tensor 코어 GPU가 필요합니다.
커스텀 INT4 AWQ에서 TensorRT-LLM이 발전함에 따라 거의 5TB/s의 메모리 대역폭과 141GB의 최신 HBM3e 메모리를 갖춘 단일 H200 텐서 코어 GPU로 실행할 수 있게 되었습니다.
이 포스팅에서는 두 가지 인기 LLM인 Llama 2 70B와 Falcon-180B에 적용된 최신 TensorRT-LLM 혁신과 그 성능을 공유합니다.
6.7배의 성능 향상을 제공하는 H200의 Llama 2 70B
최신 버전의 TensorRT-LLM은 생성 단계에서 향상된 그룹 쿼리 주의(GQA) 커널을 특징으로 하며, H200을 사용하면 NVIDIA A100 GPU에서 실행되는 동일한 네트워크와 비교하여 최대 6.7배의 성능 향상을 제공합니다.
Llama 2 70B에서 사용되는 GQA는 키-값(KV) 헤드를 함께 그룹화하는 다중 헤드 주의(MHA)의 변형으로, 쿼리(Q) 헤드보다 더 적은 수의 KV 헤드를 생성합니다. TensorRT-LLM에는 GQA, 다중 쿼리 주의(MQA) 및 표준 MHA를 지원하는 맞춤형 MHA 구현이 있습니다.
생성 및 컨텍스트 단계에서 NVIDIA 텐서 코어를 활용하며 NVIDIA GPU에서 뛰어난 성능을 제공합니다.
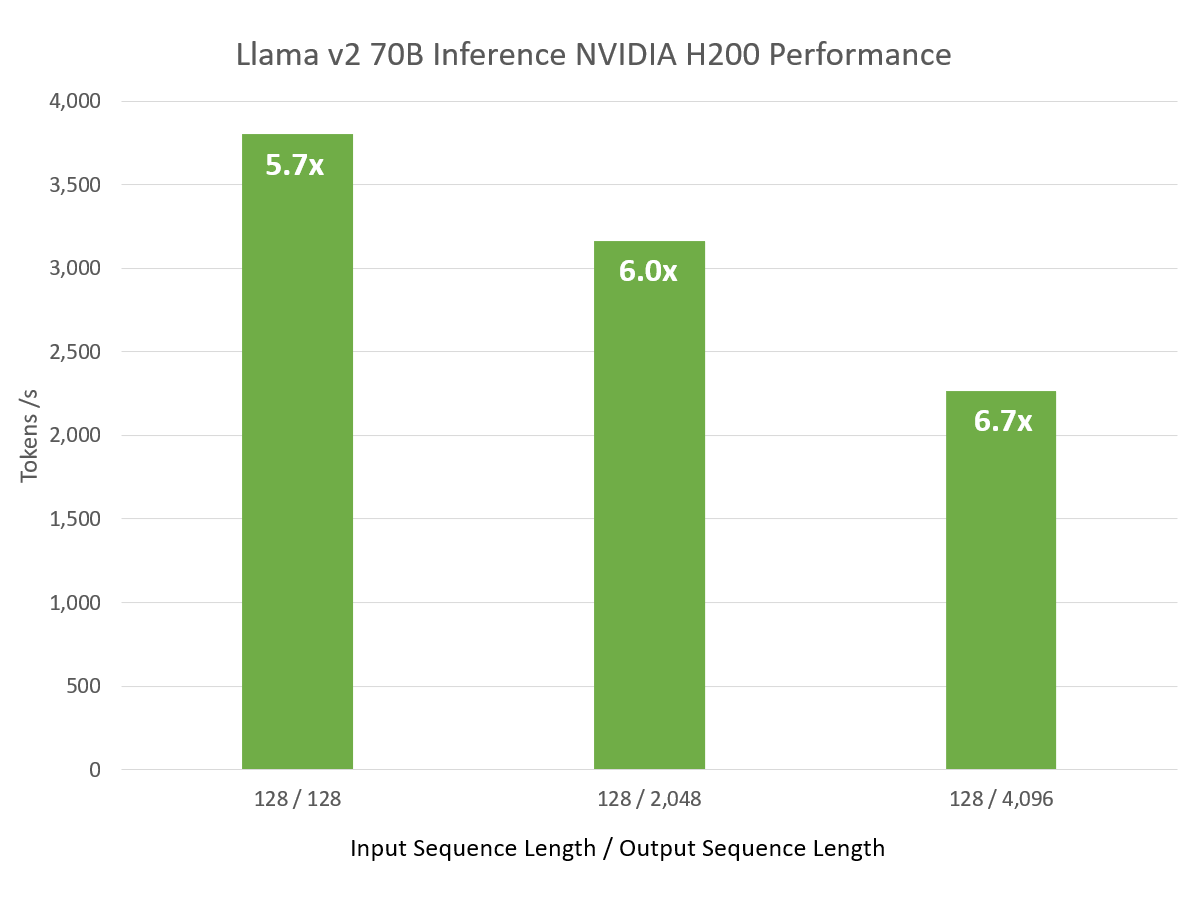
| H200 Llama 2 70B 추론 성능 | ||
| 입력 시퀀스 길이 | 출력 시퀀스 길이 | 처리량(GPU당 토큰/s) |
| 128 | 128 | 3,803 |
| 128 | 2048 | 3,163 |
| 128 | 4096 | 2,263 |
LLM 성능을 평가할 때는 다양한 입력 및 출력 시퀀스 길이를 고려하는 것이 중요한데, 이는 LLM이 배포되는 특정 애플리케이션에 따라 달라집니다. 출력 시퀀스 길이를 늘리면 예상대로 원시 처리량은 감소하지만, A100에 비해 성능 속도는 크게 향상됩니다.
TensorRT-LLM 소프트웨어의 개선만으로도 H200에서 실행되는 이전 버전에 비해 2.4배의 성능 향상을 가져왔습니다.
Falcon-180B 성능 검사
LLM은 데이터센터 시스템에 상당한 컴퓨팅 및 메모리 수요를 발생시키며, 이러한 모델이 지속적으로 성장함에 따라 이 문제는 앞으로도 한동안 지속될 것입니다. 개발자들은 이 문제를 해결하기 위해 많은 기술을 발전시키고 있습니다.
그 중 하나가 INT4 활성화 인식 가중치 양자화(AWQ)입니다(Lin et al., 2023). 이 양자화 기법은 상대적 중요도에 따라 LLM의 가중치를 단 4비트로 압축한 다음 FP16에서 계산을 수행합니다.
이 접근 방식을 통해 AWQ는 다른 4비트 방식보다 높은 정확도를 유지하면서 메모리 사용량을 줄일 수 있습니다. 이를 위해서는 고성능으로 정밀도 변화를 처리할 수 있는 특수 커널이 필요합니다.
최신 버전의 TensorRT-LLM은 AWQ를 위한 커스텀 커널을 구현합니다. 이 기술은 한 단계 더 발전하여 최신 Hopper Tensor 코어 기술을 사용하여 FP16이 아닌 NVIDIA Hopper GPU에서 FP8 정밀도로 계산을 수행합니다.
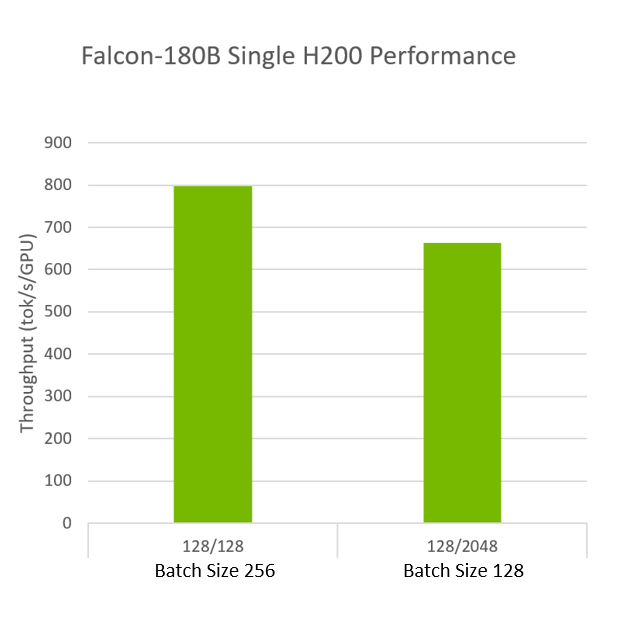
이는 단일 H200에서 FP8로 INT4 AWQ를 실행한 결과입니다. H200은 전체 Falcon-180B 모델에 적합할 뿐만 아니라 초당 최대 800개의 토큰을 처리하는 뛰어난 추론 처리량으로 모델을 실행할 수 있습니다.
목표에 집중
정량화는 종종 모델 정확도를 떨어뜨릴 수 있습니다. 하지만 TensorRT-LLM AWQ는 뛰어난 정확도를 유지하면서 메모리 사용량을 거의 4배 가까이 줄이고 추론 처리량도 뛰어납니다.

TensorRT-LLM v0.7a | Falcon-180B | 1xH200 TP1 | INT4 AWQ
TensorRT-LLM v0.7a | Falcon-180B | 1xH200 TP1 | INT4 AWQ
정확도는 더 높은 정밀도로 실행할 때와 비교하여 95% 이상을 유지하면서 더 높은 성능을 제공하고, 전체 모델을 단일 GPU에 장착하여 GPU 컴퓨팅 리소스를 최대한 활용합니다. 배포된 애플리케이션에서 GPU를 효율적으로 사용하면 컴퓨팅 리소스를 최적으로 활용할 수 있으며 운영 비용도 절감할 수 있습니다.
진행 중인 작업
이러한 개선 사항은 곧 TensorRT-LLM에서 사용할 수 있으며, v0.7 및 v0.8 릴리스에 포함될 예정입니다. TensorRT-LLM에서 라마 2 70B를 실행하는 유사한 예제는 TensorRT-LLM GitHub 페이지에서 확인할 수 있습니다.
자세한 내용은 NVIDIA H200 Tensor 코어 GPU 제품 페이지를 참조하세요.
이 블로그 게시물은 TensorRT-LLM GitHub의 기술 게시물을 각색한 것입니다: INT4 AWQ를 갖춘 단일 H200 GPU의 Falcon-180B 및 A100 대비 6.7배 빠른 Llama-70B
관련 리소스
- GTC 세션: 초대형 변압기 모델의 효율적인 추론
- GTC 세션: 통합 언어 학습자를 위한 높은 처리량, 짧은 지연 시간 추론(Google Cloud 제공)
- GTC 세션: NVIDIA Triton 추론 서버를 사용한 대규모 언어 모델 추론(CoreWeave에서 제공)
- SDK: Torch-TensorRT
- SDK: TensorFlow-TensorRT
- SDK: TensorRT