
GPUs were initially specialized for rendering 3D graphics in video games, primarily to accelerate linear algebra calculations. Today, GPUs have become one of the critical components of the AI revolution.
We now rely on these workhorses to fulfill deep learning workloads, crunching through massive and complex semi-structured datasets.
However, as demand for AI-based solutions has increased dramatically, getting access to high-end GPUs has gotten more difficult, not to mention the investment associated with setting them up and configuring them for your own use cases.
NVIDIA DGX Cloud
To help address the need for AI training, NVIDIA DGX Cloud offers state-of-the-art accelerated computing resources for users to access without the hassle of sourcing, setting up, and configuring the infrastructure themselves. It’s a game-changer for AI teams looking to push the boundaries of what can be done with the deep learning paradigm.
Beyond access to AI supercomputing in the cloud, you must structure the code and compute around it in a way that enables efficiency and performance for your AI applications. In our experience, the best way to do this is with AI orchestration: the intersection between infrastructure, code, data, and models.
In this post, I’m excited to introduce Union’s NVIDIA DGX Agent, which enables you to integrate your Flyte workflows with NVIDIA DGX Cloud. This collaboration aims to democratize production AI workflows for teams who want to manage the complexity and cost of GPU-hungry workloads.
With Union’s multi-cloud fabric and core open-source orchestrator called Flyte, I show you how you can turn the headache of containerizing, productionizing, and iterating on your AI workflows into a single-line configuration change in your code.
Why workflows matter
Union is all about simplifying and abstracting away the low-level details of production-grade AI orchestration so that ML engineers and data scientists can focus on delivering value from data.
As a case in point, take a look at what Repl.it does to fine-tune a LLM for their coding specialist models (Figure 1).
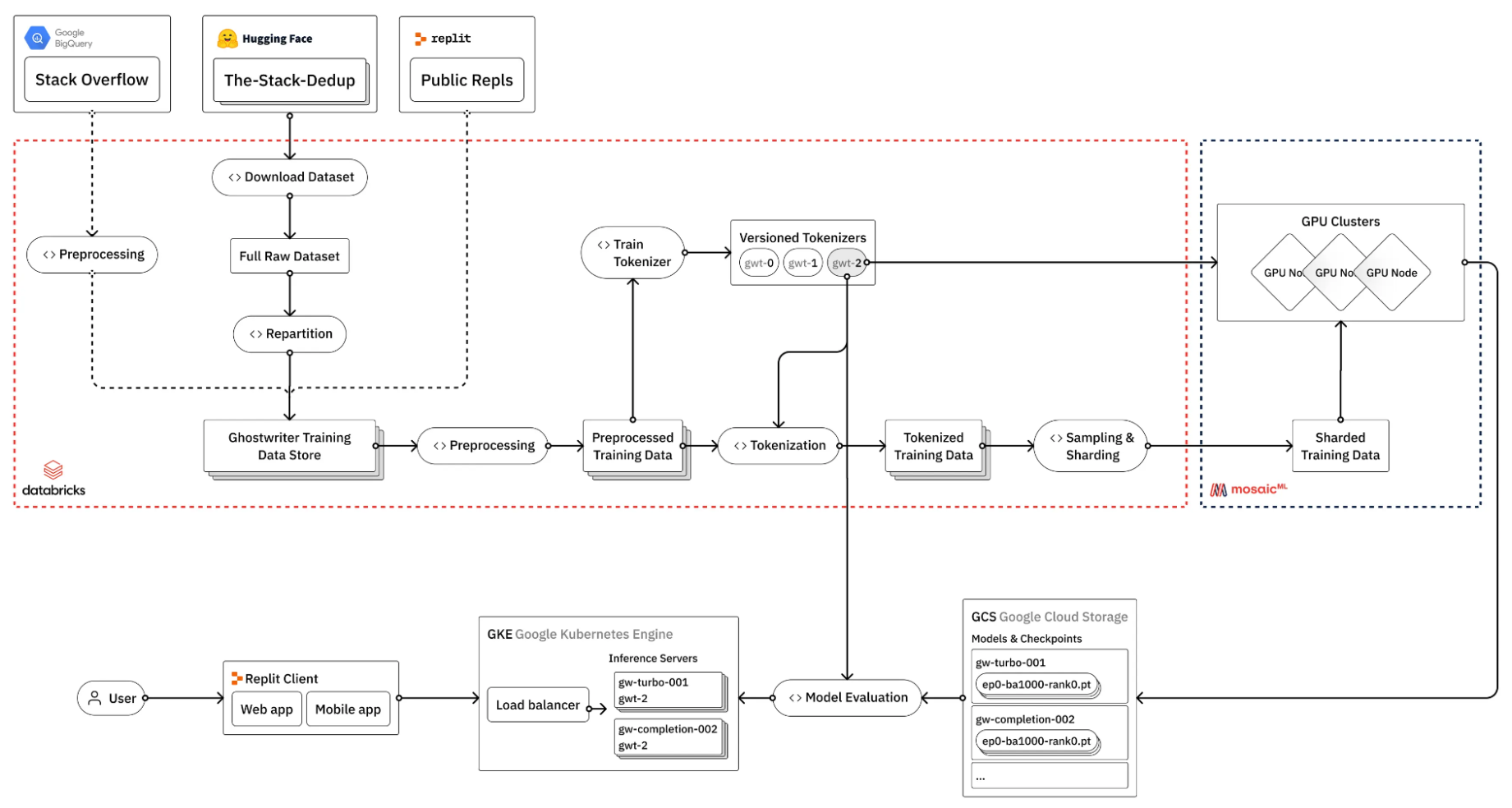
(Source: How to train your own Large Language Models)
Figure 1 shows that the process of fine-tuning a LLM involves many steps, many of which do not necessarily require GPUs. So how do you manage the complexity of these kinds of pipelines?
In the context of AI model development, workflows have become the de facto abstraction for managing the complexity of data and model management.
Flyte, a Linux Foundation open-source project that the Union co-founders originated at Lyft, aims to make your data and machine learning pipelines reproducible and extensible. Here are some of the core features that enable this:
- Tasks: Think of tasks as the individual steps in your data or machine learning pipeline, each with its own input and output. Examples include training, data transformations, predictions, and so on.
- Workflows: When you link these steps together, you’ve got yourself a workflow. It’s like a recipe where each task is an ingredient that needs to be added at just the right time.
- Declarative resource management: Here’s where things get a bit more technical. Each task comes with its own resource requirements, which is basically telling Flyte, “Hey, I need this much compute power to do my job.”
- Agents: Agents are mediators, connecting Flyte to external services like DGX Cloud, making it easy for you to call out to services outside of Flyte’s core capabilities.
The following code example shows how these elements all interact together at a high level:
from collections import NamedTuple
import pandas as pd
import torch.nn as nn
from flytekit import task, workflow, Resources
from flytekit.extras.accelerators import T4
from flytekitplugins.spark import Databricks
@task(task_config=Databricks(...))
def create_data() -> pd.DataFrame:
...
@task(requests=Resources(gpu="4"), accelerator=T4)
def train_model(data: pd.DataFrame) -> nn.Module:
...
@workflow
def model_training_pipeline() -> nn.Module:
train_data, test_data = get_data()
model = train_model(data=train_data)
return model
The example uses the Databricks task configuration to execute the create_data task on a Databricks cluster to create training data while using four NVIDIA T4 Tensor Core GPUs using Flyte’s native accelerator declaration syntax.
In Flyte, the Repl.it fine-tuning pipeline would look something like the following:
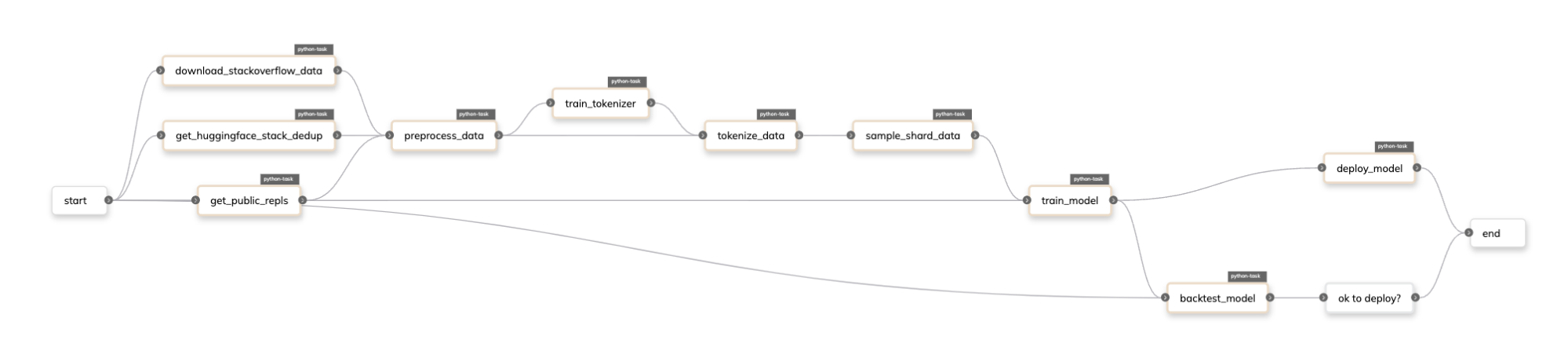
Introducing Union’s NVIDIA DGX Agent
Let’s say you’re working on fine-tuning the Mixtral 8x7b model. Even though Flyte can provision GPUs for your workloads, you may still be constrained by the lack of availability of certain GPU types on the classical cloud providers, such as Amazon Web Service, Google Cloud Platform, and Microsoft Azure.
To leverage DGX Cloud to get around this constraint, you would have to do the following:
- Develop your model training pipeline locally or on a cloud-based IDE.
- Containerize your code and dependencies.
- Push the image to the NVIDIA container registry.
- Debug your code in the likely case that issues occur on the cloud.
- Go back to step 2, rinse, and repeat.
With Union, this daunting task becomes much more seamless. We provide the tools for you to effortlessly leverage DGX Cloud’s capabilities with a single-line configuration in your code, turning what could have been a complex operation into a straightforward process.
Suppose you have a Flyte task called fine_tune that fine-tunes the Mixtral 8x7B model:
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
BitsAndBytesConfig,
TrainingArguments,
)
from trl import SFTTrainer
@task
def fine_tune(dataset_name: str, output_dir: str):
# load model, tokenizer, and dataset
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mixtral-8x7B-v0.1",
quantization_config=BitsAndBytesConfig(load_in_4bit=True),
device_map="auto",
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(
"mistralai/Mixtral-8x7B-v0.1",
use_fast=True
)
dataset = load_dataset(dataset_name, split="train")
# configer training arguments and trainer
training_args = TrainingArguments(...)
trainer = SFTTrainer(...)
# train and save the model
trainer.train()
trainer.save_model(output_dir)
To use Flyte and Union’s NVIDIA DGX Agent, add the DGXConfig task configuration and the dependencies needed for the dgx_image_spec file that ships with the agent plugin:
from flytekitpligins.dgx import DGXConfig, dgx_image_spec
fine_tuning_image_spec = dgx_image_spec.with_packages([
"accelerate", "datasets", "torch", "transformers", "trl",
])
@task(
task_config=DGXConfig(instance="dgxa100.80g.8.norm"),
container_image=fine_tuning_image_spec,
)
def fine_tune(dataset_name: str, output_dir: str):
...
The code example uses the dgxa100.80g.8.norm instance, which is a single node that contains eight NVIDIA A100 Tensor Core GPUs that you can use for training. For multi-node training, the agent plugin also provides a DGXTorchElastic configuration class that enables you to scale your workloads even further.
Union’s NVIDIA DGX Agent also offers utilities for moving your data to your cloud-native blob store (Amazon S3, GCS, Azure Blob Storage) into DGX Cloud’s blob storage system. Coupled with Flyte’s caching capabilities, you can manage data egress costs, which further allows you to control costs. For more information, see the Union documentation on the Union AI platform.
Access state-of-the-art accelerated computing today!
If you’re diving into AI development and find yourself wrestling with GPU scarcity or setup woes, it’s worth giving Union’s multi-cloud fabric a closer look. It’s designed to simplify your acquisition process, letting you focus more on development and less on the logistics of managing and maintaining hardware or cloud services.
Ready to streamline your AI projects? Reach out to the Union team, dive into the code, and see how much easier your life can get. Tackle those AI challenges head-on, with the right tools under your belt.