
More than 40 million people had their health data leaked in 2021, and the trend is not optimistic.
The key goal of federated learning and analytics is to perform data analytics and machine learning without accessing the raw data of the remote sites. That’s the data you don’t own and are not supposed to access directly. But how can you make this happen with a higher degree of confidence?
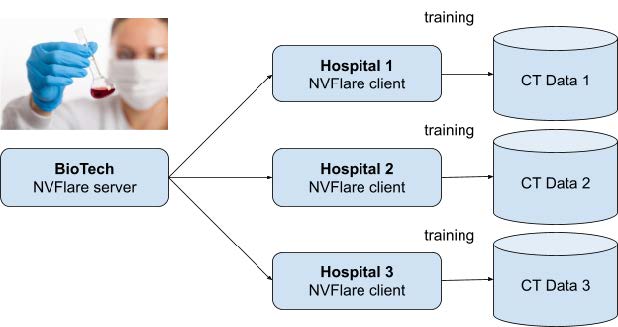
Imagine a siloed federated learning scenario with a biotech company collaborating with a network of hospitals. They’re collaborating on an improved lung cancer detection model based on CT scans of images stored locally in local infrastructure.
Both the aggregator and the biotech data scientists are not permitted to access images directly or download them. They are only permitted to perform federated learning, training, and validation of remote models and to build better-aggregated models, which are then shared with all hospitals for improved generalization and better detection accuracy.
The goal of data protection seems to be obvious at first. It’s a question of permissions, roles, and maybe some encryption here and there. Unfortunately, it’s not as easy as it might seem.
Federated privacy defaults
Federated learning solutions tend to focus on the following:
- Transmission channel security
- Point-to-point trust (using certificates)
- Efficiency of the workflows
- Support for many existing algorithms
All these reduce the risk of inference of the raw data from the model itself.
However, most of the products and publications omit the important threat of a too-curious data scientist. Many products, by design or default, prioritize the near-absolute freedom of data processing by enabling external data scientists to send any queries or operations against remote data.
This is a perfectly acceptable setup for networks with virtually unlimited trust between the participants or whenever no sensitive data is being used. For instance, the network might be used for demonstration purposes or everything could happen within the boundaries of the data-owner organization.
This is how NVIDIA FLARE works by default when you want to use custom training and validation code.
No matter what encryption you use, how strong the transmission channel security guarantees are, or how up-to-date all the systems are on component vulnerabilities, when you permit data scientists to send any queries or code against remote data, you cannot guarantee data leakage protection.
On the contrary, you are fully dependent on trust levels for individuals or contracts. Or, you could worry later by analyzing logs of the operations and queries executed against the data that you don’t own in a federated network.
One or more data scientists may one day abandon honesty. Or, the damage could be accidental instead of malicious. Market data shows that the majority of data attacks are coming from the inside. Unfortunately, inside threats are also on the rise.
Proper employee education, contract clauses, trust, privacy awareness, and work ethics are important but you should provide much stronger guarantees using technical measures.
What to do about it
Data owners should be in full control: who does what when against what data.
Logging all data-related operations is often promised as a solution by multiple product vendors. Well, after the potential damage of the data leak is done, it’s too late. You must be proactive and prevent such things during the design phase.
What about existing permission systems? In the case of NVIDIA FLARE, it is either on or off, enabling remote data scientists to execute any jobs on remote sites (local policies). Also, the biotech administration can’t manage those permissions centrally, as they would be able to override local policies remotely.
Other solutions opt for binary Docker images pushed from a central repository to remote sites (hospitals), based on the trust that whatever is there can be trusted. This practically eliminates the data owners from the acceptance process, as they can only trust the closed box of the image. Technically, they could download the image, mount it, and review files but it’s impractical at scale.
There’s a more practical approach available.
Step up your data protection game using NVIDIA FLARE 2.3.2
Here’s how to lower the risk of data leakage significantly with all its consequences, both financial and reputational. You can deliver on the promise of data protection, which is a key element of federated learning and analytics using the latest features introduced in NVIDIA FLARE 2.3.2, as a result of our fruitful collaboration.
Job acceptance and rejection requirements
You need a solution that enables data owners to review the code to be executed against their data before it happens. Practically, in NVIDIA FLARE, it means Python code implementing the trainer, validation, and federated statistics plus configuration settings.
Data owners should be able to review and accept or reject the code themselves or use trusted third-party reviewers. Nothing should happen against data without the explicit acceptance of the data owner.
No job code should be changed from the previously accepted code to malicious code overnight. It should be rejected because its contents have changed and it must be re-reviewed and re-accepted.
Solution
NVIDIA FLARE 2.3.2 delivers enablement of custom event handlers that perform actions to enable the components to be created at the site and controlled by the site.
But why object creation? Can’t you just focus on the execution?
Because too-curious data scientists could easily inject the code into object initialization (constructor), object creation is essential. Act as early as possible to prevent the code that data owners don’t want from running against their data.
The following simplified flow is the default:
- A central server controlled by external data scientists submits jobs to clients.
- Clients schedule and execute those jobs.
- If the code contains uploading data to the cloud, virtually anything that Python permits is executed.
- Even worse, the code may change with each job submission and it won’t be detected or prevented from execution.
Jobs are sent from the orchestration node to local nodes for execution. They contain code and configuration.
After the federated network is built using the default NVIDIA FLARE configuration, there is unconditional trust in external data scientists by data owners. They are then permitted to submit jobs with local policies.
After the change, with a custom implementation:
- A central server controlled by external data scientists submits jobs to clients.
- A data owner reviews the job code and determines if it’s acceptable from the data leakage risk perspective.
- If the code is approved, the hash is added to the list of accepted hashes.
- The job code (hash, signature) is checked locally at the site against the list of accepted hashes of jobs.
- The job is executed on the client and results are returned to the server.
Here’s more detail about how the job workflow changes.
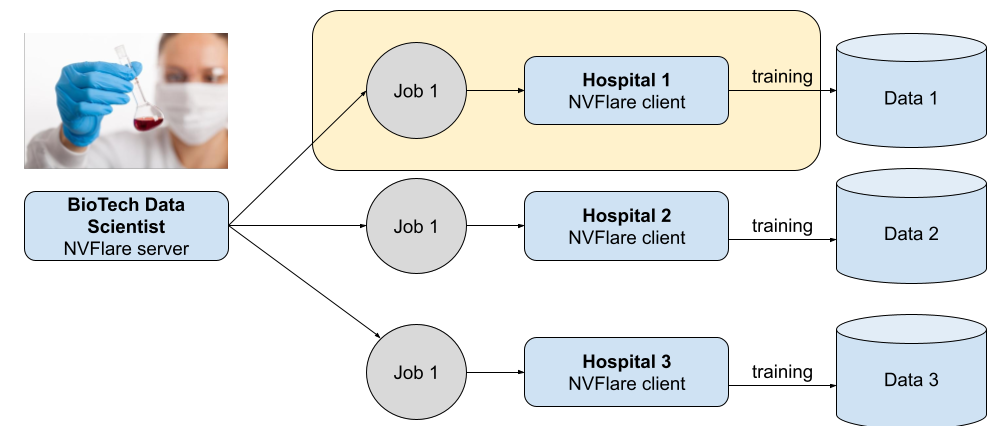
Figure 2 shows a federated learning network consisting of a BioTech orchestration node and three hospital nodes. The same federated training job is sent from the orchestration node for the local nodes. The job is not even created to prevent any malicious code as part of the initialization or constructor of the job object.
Figure 3 shows the flow of job acceptance and execution using a new type of event and event handler.
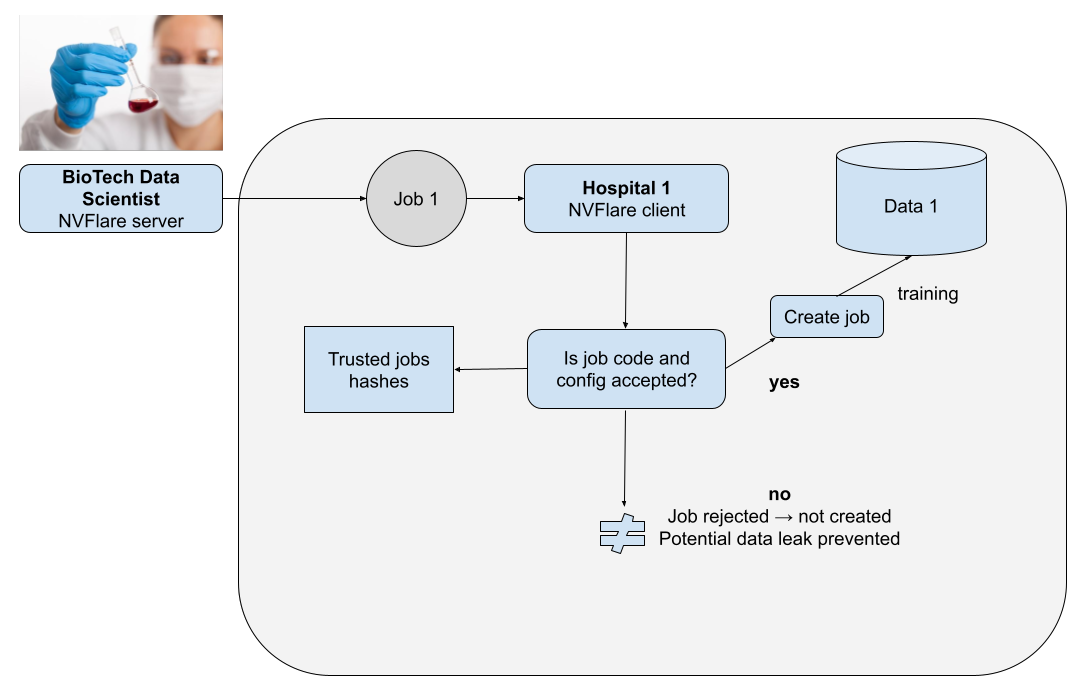
Job code acceptance strategies
Thanks to the open event–based model delivered in NVIDIA FLARE 2.3.2, it is possible to implement any suitable code verification strategy. Such strategies must always be designed, defined, and agreed upon in a federated network and then deployed on each node (a client, such as a hospital).
For demonstration purposes, you can compare the code content hash against the accepted code stored in a different directory.
For more real-world, enterprise-grade scenarios, you can also provide implementations based on digital signatures of the code and even co-signatures provided by the third party trusted by data owners. This is independent of biotech performing the federated training.
Code example
NVIDIA FLARE raises the BEFORE_BUILD_COMPONENT event before a new component (that is, a job) is instantiated. All you must do is write the event handler to analyze the code and determine if it was accepted. There’s no turnkey solution for that, as different federated networks may require different strategies. The following code example demonstrates such a handler. For demonstration purposes, the example only focuses on a subset of jobs.
focuses on a subset of jobs.
def handle_event(self, event_type: str, fl_ctx: FLContext):
if event_type == EventType.BEFORE_BUILD_COMPONENT:
# scanning only too curious data scientist jobs
if self.playground_mode:
meta = fl_ctx.get_prop(FLContextKey.JOB_META)
log.info(f"meta: {meta}")
if not "too-curious-data-scientist" in meta["name"]:
return
workspace: Workspace = fl_ctx.get_prop(key=ReservedKey.WORKSPACE_OBJECT)
job_id = fl_ctx.get_job_id()
log.debug(fl_ctx.get_prop(FLContextKey.COMPONENT_CONFIG))
log.debug(f"Run id in filter: " + job_id)
log.debug(f"rootdir: {workspace.get_root_dir()}, app_config_dir: {workspace.get_app_config_dir(job_id)}, app_custom_dir: {workspace.get_app_custom_dir(job_id)}" )
#making sure that approved_configs hash set is up to date (it's possible to update )
self.populate_approved_hash_set(os.path.join(workspace.get_root_dir(), self.approved_config_directory_name))
log.debug(f"Approved hash list contains: {len(self.approved_hash_set)} items")
# check if client configuration json is approved (job configuration)
current_hash = self.hash_file(os.path.join(workspace.get_app_config_dir(job_id), JobConstants.CLIENT_JOB_CONFIG))
if current_hash in self.approved_hash_set:
log.info(f"Client job configuration in approved list! with hash {current_hash}")
else:
log.error(f"Client job configuration not in approved list! with hash {current_hash}")
log.error("Not approved job configuration! Throwing UnsafeComponentError!")
raise UnsafeComponentError("Not approved job configuration! Killing workflow")
# check if all classes added to custom directory are approved
job_custom_classes = list(Path(os.path.join(workspace.get_app_custom_dir(job_id))).rglob("*.py"))
for current_class_file in job_custom_classes:
current_class_file_hash = self.hash_file(current_class_file)
if current_class_file_hash in self.approved_hash_set:
log.info(f"Custom class {current_class_file} in approved list!")
else:
log.error(f"Class {current_class_file} not in approved list!")
log.error("Not approved job! Throwing UnsafeComponentError!")
raise UnsafeComponentError(f"Class {current_class_file} not in approved list! with hash {current_class_file_hash}. Not approved job! Killing workflow")
As we demonstrated earlier, all the required contextual data is provided by NVIDIA FLARE to be able to perform required actions such as finding the custom code files, calculating their hashes, and so on.
There’s more
This does not solve all the problems related to data protection. However, in all the scenarios with data owners having limited trust for the remote data scientists training models on their data without seeing it, addressing this problem is imperative.
While this feature is not a definitive fail-safe measure against malicious users, it provides an additional layer of protection. It empowers nodes and fosters collaborative research through shared responsibility.
Next, consider focusing on other important areas, such as the following:
- Model inference attacks
- Differential privacy
- Transmission channel security
- Output filters
Summary
The principle of defense in depth in the case of federated learning and analytics makes it necessary to protect the data owner from possibly malicious remote code sent by external data scientists. In the case of truly federated scenarios, when there’s no full trust relationship between data owners and remote scientists, this is not optional.
The promise of remote data inaccessibility doesn’t deliver itself; you must empower data owners. It’s not guaranteed by default.
In this post, we demonstrated how to address this important threat using NVIDIA FLARE 2.3.2 to enable better data protection and build more secure federated learning networks today and in the future.
