
There are many benefits of GPUs in scaling AI, ranging from faster model training to GPU-accelerated fraud detection. While planning AI models and deployed apps, scalability challenges—especially performance and storage—must be accounted for.
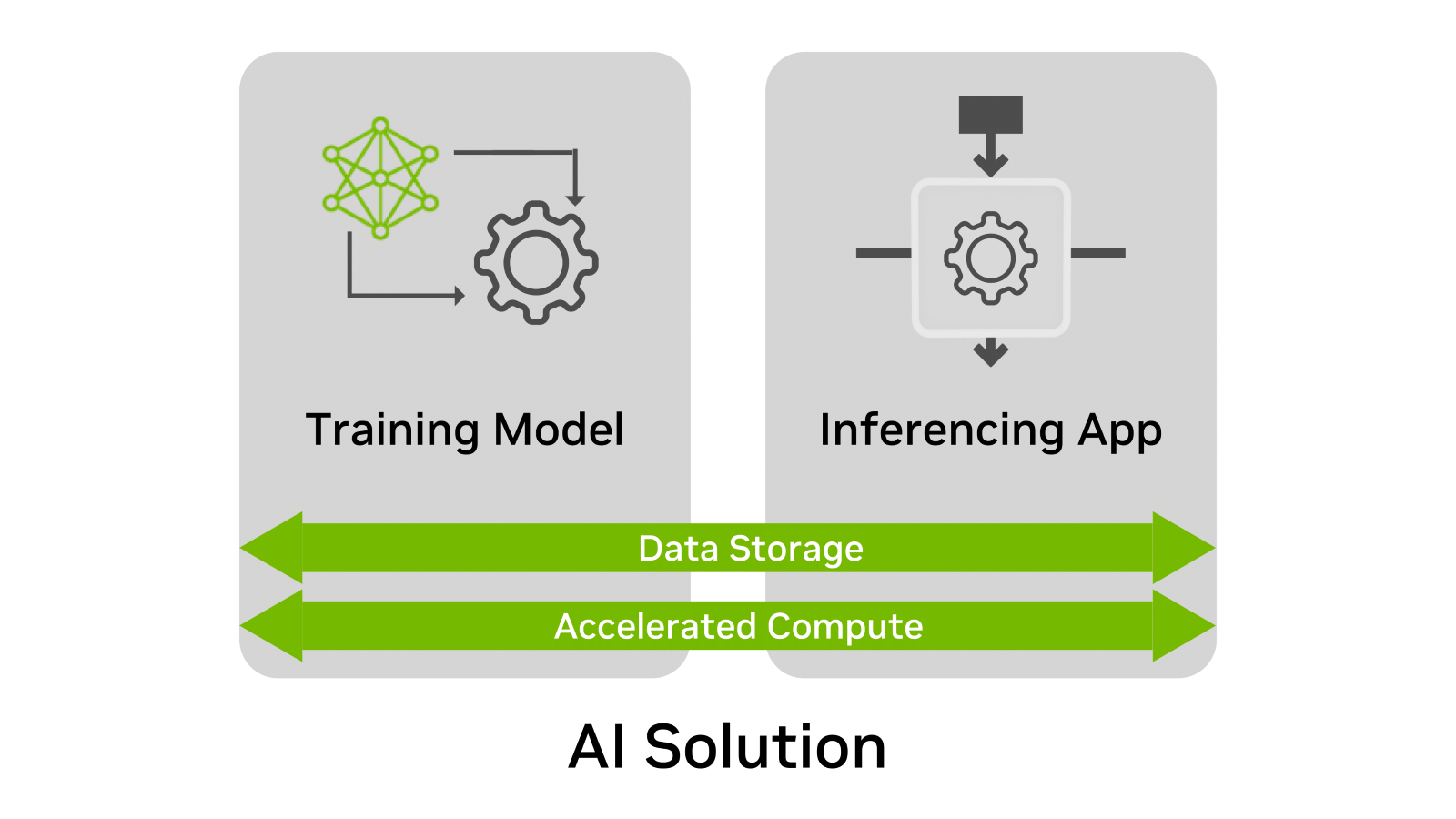
Regardless of the use case, AI solutions have four elements in common:
- Training model
- Inferencing app
- Data storage
- Accelerated compute
Of these elements, data storage is often the most neglected during the planning process. Why? Because data storage needs, over time, are not always considered while creating and deploying an AI solution. Most requirements for an AI deployment are quickly confirmed through a POC or test environment.
The challenge, however, is that POCs tend to address a single point in time. Training or inferencing deployment may exist for months or years. Because many companies expand their scope of AI projects quickly, the infrastructure must also scale to accommodate growing models and datasets.
This blog explains how to plan in advance and scale data storage for training and inferencing.
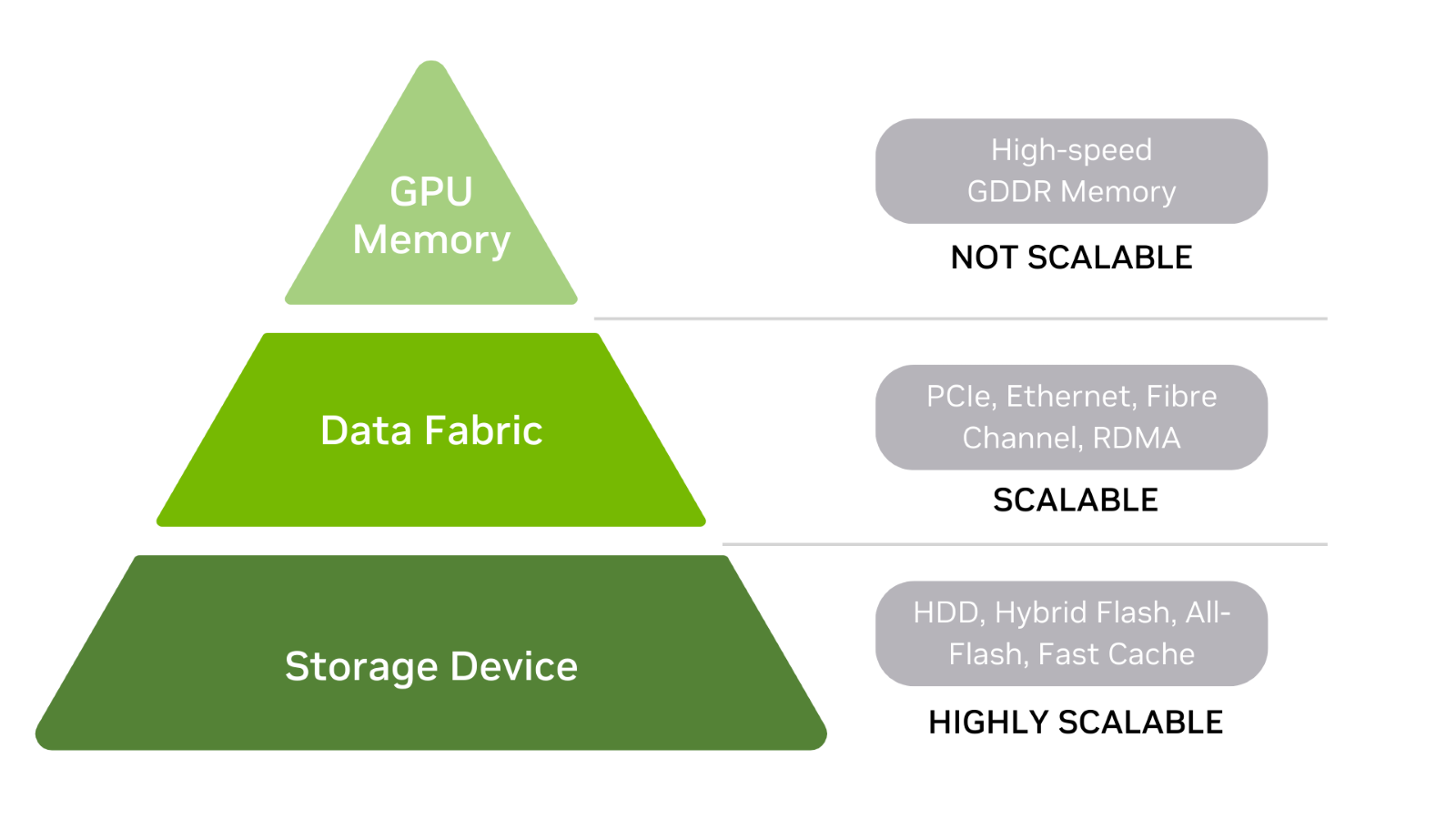
Data storage hierarchy for AI
To get started, understand the data storage hierarchy for AI, which includes GPU memory, a data fabric, and storage devices (Figure 2).
Generally, the higher you go in the storage hierarchy, the faster the storage performance–especially latency. For this discussion, storage is defined as anything that stores data when power is on or off, including memory.
Storage devices
Hard drives and flash drives are at the base of the storage hierarchy. There are also hybrid arrays that are a combination of each. HDDs may be front-ended with a fast cache layer, while all-flash arrays may use storage-class memory (SCM) to improve read performance.
Fast storage is useful when the loading time for large datasets into GPU memory is important. When there is a need to train a model that no longer fits in the storage device, it is easy to scale storage capacity. It may also be that multiple datasets must be stored – an additional reason to have scalable storage.
Data fabric
In the middle of the hierarchy, data fabric is used to connect storage devices with GPU memory.
This layer includes:
- PCIe bus
- Network cards
- DPUs
- Any other card in the datapath between storage and GPU memory.
To keep things simple, the fabric can simply be viewed as a pass-through data layer between storage devices and GPU memory.
GPU memory
At the top of the storage hierarchy is GPU memory (often called vRAM.) Because GPU memory is fast and directly connected to the GPU, training datasets are processed quickly when the entire model resides within memory. CPU memory is also at the top of the hierarchy, just below GPU memory.
Alternatively, model data can be sent to GPU memory in multiple batches. Large GPU memory results in fewer batches and faster training time. If a GPU traverses across data fabric to internal or external storage for any part of the model or dataset, swapping activity to disk substantially reduces training performance.
Keep in mind that while storage devices and data fabric can scale, GPU memory is fixed. This means GPU memory is configured to the GPU and memory size cannot be upgraded to support larger training models and datasets.
The original GPU can use the memory of an added GPU if supported by the manufacturer, such as through NVIDIA NVLink. However, not all systems can accommodate a second GPU and the possibility of additional memory.
Ultimately, deployment plans should include a GPU with memory well in excess of current needs. Addressing a memory shortage in the future can be expensive.
Considerations when scaling storage for inference
Inference is where the value of the AI solution is delivered. For this reason, effective storage is required.
To ensure that storage for inferencing is scalable, consider these factors:
- Scaleup and scaleout
- Seamless upgrades
- Real-time requirements
Scaleup and scaleout
Storage scalability isn’t measured only in capacity. It’s also measured in performance. True scaleout ensures that when capacity and performance requirements increase, the storage system delivers more capacity and performance as necessary.

Let‘s examine a real-world example of scaleup compared to scaleout. There are dozens of pedicabs in San Francisco tourist areas. A single bicyclist or driver powers a pedicab with a passenger capacity of two, four, or even six people.
With a single passenger, the driver can pedal quickly, arrive at the destination faster, and seek new passengers sooner. A pedicab loaded with more passengers, results in slower acceleration, lower top speed, and fewer trips for the day. A pedicab is a scale-up machine.
You can easily add capacity, but there is no equivalent increase in performance as you are limited to the power of a single driver. With a scale-out machine, an additional driver powers the pedicab for each added passenger. When power and capacity increase linearly, performance never becomes a bottleneck.
For inference, true scaleout of both capacity and performance is key. The inference server can store large volumes of data over time. Storage read and write performance must scale to prevent delayed inference results.
But, storage capacity must also scale as voice, image, customer profiles, and other data are written to disk as the inference app executes. There’s also the need to store retraining data efficiently for feedback into the model.
Seamless upgrades
Certain inference apps don’t tolerate downtime well. For example, what is the best time to shut down fraud detection for an online store? What will it cost in lost orders when you disable a webstore recommender engine to upgrade storage capacity or storage performance?
The list of inference apps that can suffer from maintenance upgrades is extensive. Examples include:
- Conversational AI apps for customer service.
- 24/7 analysis of video streams for intelligent insights.
- Critical image recognition apps.
Unless inferencing can tolerate maintenance windows, scaling capacity and performance become a challenge. It’s always best to think through storage upgrade and availability scenarios before committing to a specific storage deployment.
Real-time requirements
As a real-time inferencing example, consider fraud detection for online transactions. The inferencing app is looking for anomalous behavior and transaction profiles that reveal unacceptable risk. Hundreds of decisions must be made in fractions of a second as users wait for transaction approval. Low-latency storage and high-performance data fabric connections are key to real-time transactions, especially when risk parameters must quickly be retrieved from storage.
Submillisecond storage performance is the starting point for certain real-time apps that benefit from a high-performance pathway between storage and GPU memory. NVIDIA leverages RDMA protocols to accelerate the transfer from storage to vRAM, with a functionality called NVIDIA GPUDirect Storage. This can shorten GPU retrieval time for stored data (such as risk profile data) needed in real time. The retrieved profile and risk data points may later be re-analyzed to improve accuracy.
NVIDIA GPUDirect technology supports DMA direct datapath transactions between GPU memory and local NVMe storage, or remote storage through NVMe-oF.
Addressing oversights
There is often room for improvement during the planning process. Some common storage-related oversights for training and inferencing include scalability, performance, availability, and cost.
There are ways to avoid this during training and inference.
Training:
- Always deploy with GPU memory that far exceeds current requirements.
- Always consider the size of future models and datasets as GPU memory is not expandable.
Inference:
- Choose scale-out storage when growth in both performance and capacity is expected over time.
- Choose storage that supports seamless upgrades, especially for apps that provide little or no maintenance window.
- Future storage upgrades to support real-time inferencing apps may not be possible or practical. Make these decisions before initial GPU, storage, and fabric deployment.
Key takeaways
Scaling storage should be addressed early and in a holistic manner. This includes capacity, performance, network hardware, and data transfer protocols. Above all, ensure ample GPU resources as failure to do so can negate all other training and inferencing efforts.
Gain a better understanding of how workload complexity impacts storage performance in the post, Storage Performance Basics for Deep Learning.
Also, consider using NVIDIA-Certified GPU-accelerated workstations and servers as they are certified across a wide variety of enterprise storage and network products.
