

Seamlessly deploying AI services at scale in production is as critical as creating the most accurate AI model. Conversational AI services, for example, need multiple models handling functions of automatic speech recognition (ASR), natural language understanding (NLU), and text-to-speech (TTS) to complete the application pipeline. To provide real-time conversation to users, such applications should be able to handle the many queries made by millions of smart devices and assistants. NVIDIA Triton Inference Server provides a great solution to such performance challenges and multi-modality requirements.
Triton Server (formerly known as NVIDIA TensorRT Inference Server) is an open source, inference serving software that lets DevOps teams deploy trained AI models. Those models can be built on any frameworks of choice (TensorFlow, TensorRT, PyTorch, ONNX, or a custom framework) and saved on a local or cloud storage, on any CPU or GPU-powered system running on-premises, in the cloud or at the edge.
Triton Server is available as a container from NVIDIA NGC, a hub for GPU-optimized software for deep learning, machine learning, and high-performance computing (HPC). NGC offers containers for popular AI frameworks such as TensorFlow and PyTorch, pretrained models for conversational AI, medical imaging, video analytics, and other popular use cases. NGC also offers industry-specific SDKs that simplify building and deploying AI solutions.
In this post, we focus on deploying a fine-tuned BERT model for NLU on Triton Server. For more information, see Jump-start AI Training with NGC Pretrained Models On-Premises and in the Cloud and Optimizing and Accelerating AI Inference with the TensorRT Container from NVIDIA NGC.
Triton Inference Server
Triton Server runs multiple models from the same or different frameworks concurrently on either a single-GPU or multi-GPU server. It delivers low-latency, real-time inferencing or batch inference to maximize GPU/CPU utilization and streaming inference for audio streaming.
As a Docker container, Triton Server integrates with Kubernetes for orchestration, metrics, and automatic scaling, designed for scalability. It supports the standard HTTP/gRPC interface to connect with other applications like load balancers. It can also easily scale to any number of servers to handle increasing inference loads for any model.
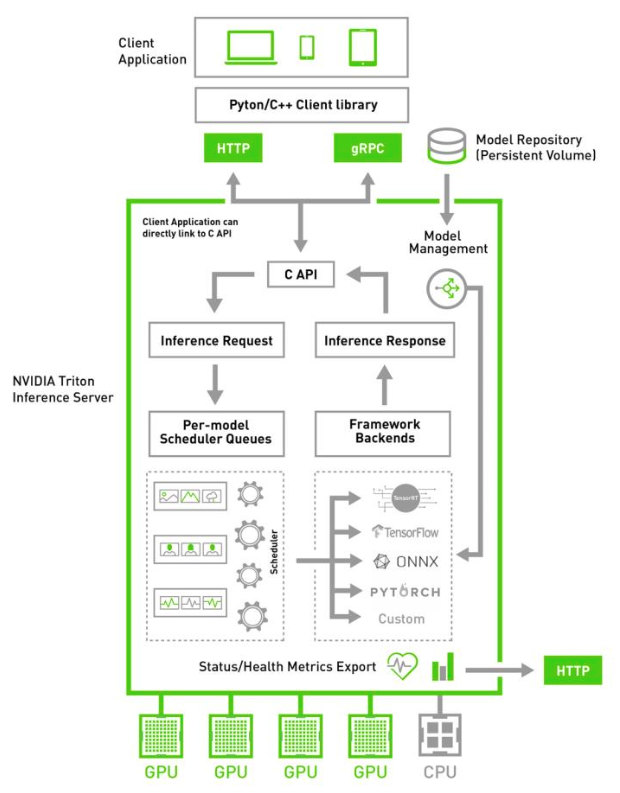
Triton Server workflow
A typical Triton Server pipeline can be broken down into the following steps:
- Client Send—Client serializes the inference request into a message and sends it to Triton Server.
- Network—Message travels over the network from the client to the server.
- Server Receive—The message arrives at the server and gets deserialized.
- Server Queue—The request is placed on the queue.
- Server Compute—The request is removed from the queue and computed.
- Server Send—The completed request is serialized in a message and sent back to the client.
- Network—The message travels over the network from the server to the client.
- Client Receive—The message arrives at the client and is deserialized and processed as a completed inference request.
The model to be run on Triton Server should be exported beforehand. The entire process, including the model export and run-down of the pipeline is captured in the Deploy BERT on Triton Server and run a client with the SQuAD dataset section later in this post.
Launch Triton Server and test example applications
Using examples, we walk you through a step-by-step process of deploying Triton Server on a given system. You can also create your own custom model to deploy with Triton Server. Both Triton Inference Server Docker image and Triton-ClientSDK Docker image that contains example code inside are available from NGC.
Prerequisites
Clone the Triton Server GitHub repository:
$ git clone https://github.com/NVIDIA/triton-inference-server
Select the right release branch:
$ cd triton-inference-server $ git checkout r20.06
Fetch the example models:
$ cd docs/examples $ ./fetch_models.sh
Install Docker and nvidia-docker. For DGX users, see Preparing to use NVIDIA Containers. For users other than DGX, see NVIDIA Container Toolkit.
Pull a prebuilt Triton Server container from NGC:
$ docker login nvcr.io $ docker pull nvcr.io/nvidia/tritonserver:20.06-py3
Launch Triton Server
Run the following command:
$ docker run --gpus=1 --rm --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -p8000:8000 -p8001:8001 -p8002:8002 -v $PWD/model_repository:/models nvcr.io/nvidia/tritonserver:20.06-py3 tritonserver --model-repository=/models
When the inference server is ready to accept the requests, you should see the following results:
I0828 23:42:45.635957 1 main.cc:417] Starting endpoints, 'inference:0' listening on I0828 23:42:45.649580 1 grpc_server.cc:1730] Started GRPCService at 0.0.0.0:8001 I0828 23:42:45.649647 1 http_server.cc:1125] Starting HTTPService at 0.0.0.0:8000 I0828 23:42:45.693758 1 http_server.cc:1139] Starting Metrics Service at 0.0.0.0:8002
Get the client examples
Included in the container are a few example client scripts to which you can refer, written in C++ and Python:
$ docker pull nvcr.io/nvidia/tritonserver:20.06-py3-clientsdk $ docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:20.06-py3-clientsdk
Run the image classification example
The following example inputs a picture of a mug cup to the ResNet50 model:
$ python /workspace/install/python/image_client.py -m resnet50_netdef -s INCEPTION /workspace/images/mug.jpg
When run successfully, you should receive the following response from Triton Server:
Request 0, batch size 1 Image ‘../images/mug.jpg’: 504 (COFFEE MUG) = 0.778078556061
Run BERT on Triton Server
The following steps walk you through the process to deploy a pretrained BERT model to Triton Server. All the assets used in the following example can be found on NGC. Although the following example demonstrates the TensorFlow implementation of BERT, you can find the equivalent in PyTorch from NGC and the NVIDIA GitHub pages as well.
Create a BERT model repository from NVIDIA Deep Learning Examples on GitHub:
$ git clone https://github.com/nvidia/DeepLearningExamples.git $ cd DeepLearningExamples/TensorFlow/LanguageModeling/BERT/
Collect pretrained BERT model assets from NGC. You have a choice of two options.
Option 1: Download from the command line:
$ wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/bert_config.json $ wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/model.ckpt.data-00000-of-00001 $ wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/model.ckpt.index $ wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/model.ckpt.meta $ wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/vocab.txt
Option 2: Download from the NGC website.
When done, place the downloaded files in the BERT repository:
$ <path/to/BERT/repo>/results/models/bert_large_fp16_384_v1
Build the Docker container and download the SQuAD dataset. To download the SQuAD dataset and BERT model files, modify the <path/to/BERT/repo>/data/create_datasets_from_start.sh script, removing everything but the following three lines:
export BERT_PREP_WORKING_DIR="${BERT_PREP_WORKING_DIR}"
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action download --dataset squad
Run the provided scripts to build the container and download the SQuAD dataset:
$ bash scripts/docker/build.sh $ bash scripts/data_download.sh
Deploy BERT on Triton Server and run a client with the SQuAD dataset
If you followed the steps described up to this point, you can now deploy the BERT model on Triton Server and run a client with inference requests with the SQuAD dataset with one line of command and slight modifications to the triton/scripts/run_triton.sh script.
Replace the following from line 33:
export BERT_DIR=data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16
The new value should be:
export BERT_DIR=results/models/bert_large_fp16_384_v1
Remove the lines from 38 to 41, starting with the following:
if [ ! -d "$BERT_DIR" ] ; then
The block ends with the following:
fi
Now you can run the script:
$ bash triton/scripts/run_triton.sh
It is worthwhile to understand what is happening at each step so that you can create your own application. You don’t need to execute any commands in subsequent sections, and detailed information can also be found in the BERT/triton GitHub repo as well.
- Export BERT in SavedModel format (triton/scripts/export_model.sh)
The script exports the BERT model to the SavedModel format that TensorFlow supports. You need the vocab file, fine-tuned checkpoints, and BERT model files (bert_large_fp16_384_v1 retrieved from NGC), along with the other configurations that can be specified, such as sequence length(384) and doc stride(128). - Launch Triton Server (triton/scripts/launch_server.sh)
The script launches Triton Server with the container available at nvcr.io/nvidia/tritonserver:20.06-py3. You can change the port for HTTP and gRPC endpoints, if necessary. They are set to the default values of 8000 and 8001. - Start the client for inference on the SQuAD dataset (triton/scripts/run_client.sh)
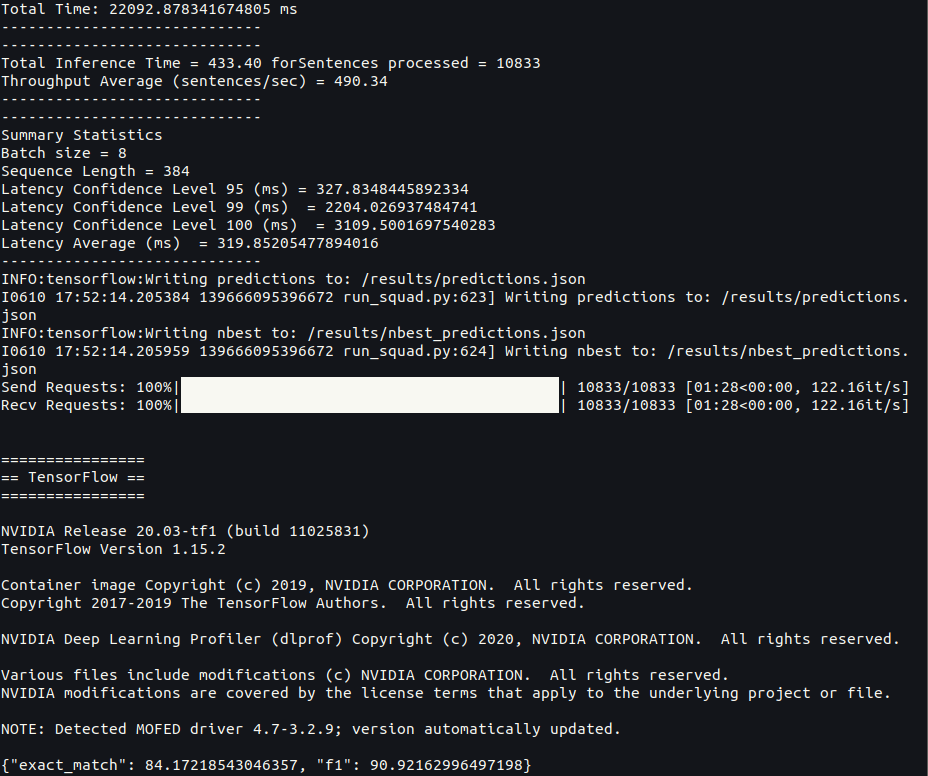
The script includes the preprocessing of dataset to BERT features, sending and receiving the requests, and post-processing the completed requests to get predictions. - Evaluate the SQuAD results.
The script takes the predictions created by the client in the previous step to produce evaluation metrics such as the F1 score.
When you are done, expect a screen similar to Figure 2.
Next steps
In this post, we shared how to simplify AI inference with the Triton Server container from NGC. Pull a Triton Server container today and see how you can easily deploy your model for GPU-optimized inference.
