
Natural language processing (NLP) is one of the most challenging tasks for AI because it needs to understand context, phonics, and accent to convert human speech into text. Building this AI workflow starts with training a model that can understand and process spoken language to text.
BERT is one of the best models for this task. Instead of starting from scratch to build state-of-the-art models like BERT, you can fine-tune the pretrained BERT model for your specific use case and put it to work with NVIDIA Triton Inference Server. There are two BERT-based models available:
- BERT-Base with 12 layers, 12 attention heads, and 110 million parameters
- BERT-Large with 24 layers, 16 attention heads, and 340 million parameters
A lot of parameters in these models are sparse. The large number of parameters thus reduces the throughput for inference. In this post, you use BERT inference as an example to show how to leverage the TensorRT container from NVIDIA NGC and get a performance boost on inference with your AI models.
Prerequisites
This post uses the following resources:
- The TensorFlow container for GPU-accelerated training
- A system with up to eight NVIDIA GPUs, such as DGX-1
- Other NVIDIA GPUs can be used but the training time varies with the number and type of GPU.
- GPU-based instances are available on all major cloud service providers.
- NVIDIA Docker
- The latest CUDA driver
Get the assets from NGC
Before you can start the BERT optimization process, you must obtain a few assets from NGC:
- A fine-tuned BERT-large model
- Model scripts for running inference with the fine-tuned model, in TensorFlow
Fine-tuned BERT-Large model
If you followed our previous post, Jump-start AI Training with NGC Pretrained Models On-Premises and in the Cloud, you’ll see that we are using the same fine-tuned model for optimization.
If you didn’t get a chance to fine-tune your own model, make a directory and download the pretrained model files. You have several download options.
Option 1: Download from the command line using the following commands. In the terminal, use wget to download the fine-tuned model:
mkdir bert_model && cd bert_model wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/bert_config.json wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/model.ckpt.data-00000-of-00001 wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/model.ckpt.index wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/model.ckpt.meta wget https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad11_amp_384/versions/19.03.1/files/vocab.txt
Option 2: Download from the NGC website.
- In your browser, navigate to the model repo page.
- In the top right corner, choose Download.
- After the zip file finishes downloading, unzip the files.
Refer to the directory where the fine-tuned model is saved as $MODEL_DIR. It can be the model that you saved from our previous post, or the model that you just downloaded.
When you are in this directory, export it:
export MODEL_DIR=$PWD cd ..
Model scripts for running inference with the fine-tuned model
Use the following scripts to see the performance of BERT inference in TensorFlow format. To download the model scripts:
- In your browser, navigate to the model scripts page.
- At the top right, choose Download.
Alternatively, the model script can be downloaded using git from the NVIDIA Deep Learning Examples on GitHub:
mkdir bert_tf && cd bert_tf git clone https://github.com/NVIDIA/DeepLearningExamples.git
You are doing TensorFlow inference from the BERT directory. Whether you downloaded using the NGC webpage or GitHub, refer to this directory moving forward as $BERT_DIR.
Export this directory as follows:
export BERT_DIR=$PWD'/DeepLearningExamples/TensorFlow/LanguageModeling/BERT/' cd ..
Before cloning the TensorRT GitHub repo, run the following command:
mkdir bert_trt && cd bert_trt
To get the script required for converting and running BERT TensorFlow model into TensorRT, follow the steps in Downloading the TensorRT Components. Make sure that the directory locations are correct:
$MODEL_DIR—Location of the BERT model checkpoint files.$BERT_DIR—Location of the BERT TF scripts.
TensorFlow performance evaluation
In this section, you build, run, and evaluate the performance of BERT in TensorFlow.
Set up and run a Docker container
Build the Docker container by running the following command:
docker build $BERT_DIR -t bert
Launch the BERT container, with two mounted volumes:
- One volume for the BERT model scripts code repo, mounted to
/workspace/bert. - One volume for the fine-tuned model that you either fine-tuned yourself or downloaded from NGC, mounted to
/finetuned-model-bert.
docker run --gpus all -it \ -v $BERT_DIR:/workspace/bert \ -v $MODEL_DIR:/finetuned-model-bert \ bert
Prepare the dataset
You are evaluating the BERT model using the SQuAD dataset. For more information, see SQuAD1.1: The Stanford Question Answering Dataset.
export BERT_PREP_WORKING_DIR="/workspace/bert/data" python3 /workspace/bert/data/bertPrep.py --action download --dataset squad
if the line import PubMedTextFormatting gives any errors in the bertPrep.py script, comment this line out, as you don’t need the PubMed dataset in this example.
This script downloads two folders in $BERT_PREP_WORKING_DIR/download/squad/: v2.0/ and v1.1/. For this post, use v1.1/.
Run evaluations with the TensorFlow model
Inside the container, navigate to the BERT workspace that contains the model scripts:
cd /workspace/bert/
You can run inference with a fine-tuned model in TensorFlow using scripts/run_squad.sh. For more information, see Jump-start AI Training with NGC Pretrained Models On-Premises and in the Cloud.
There are two modifications to this script. First, set it to prediction-only mode:
--do_train=False--do_predict=True
When you manually edit --do_train=False in run_squad.sh, the training-related parameters that you pass into run_squad.sh aren’t relevant in this scenario.
Second, comment out the following block starting at line number 27:
#if [ "$bert_model" = "large" ] ; then # export BERT_DIR=data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16 #else # export BERT_DIR=data/download/google_pretrained_weights/uncased_L-12_H-768_A-12 #fi
Because you can get vocab.txt and bert_config.json from the mounted directory /finetuned-model-bert, you do not need this block of code.
Now, export BERT_DIR inside the container:
export BERT_DIR=/finetuned-model-bert
After making the modifications, issue the following command:
bash scripts/run_squad.sh 1 5e-6 fp16 true 1 384 128 large 1.1 /finetuned-model-bert/model.ckpt<-num>
Put the correct checkpoint number <-num> available:
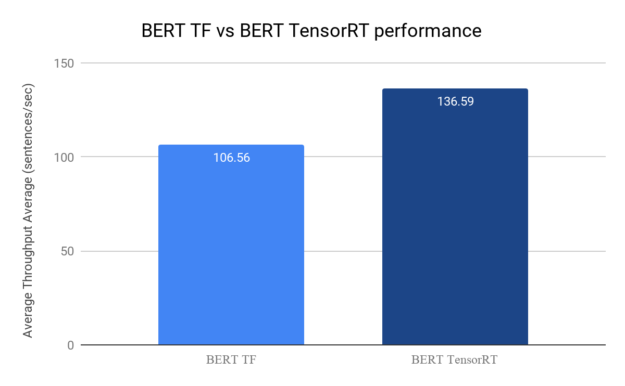
INFO:tensorflow:Throughput Average (sentences/sec) = 106.56
We observed that inference speed is 106.56 sentences per second for running inference directly in TensorFlow on a system powered with a single NVIDIA T4 GPU. Performance may differ depending on the number of GPUs and the architecture of the GPUs.
This is good performance, but could it be better? Investigate by using the scripts in /workspace/bert/trt/ to convert the TF model into TensorRT 7.1, then run inference on the TensorRT BERT model engine. For that process, switch over to the TensorRT repo and build a Docker image to launch.
Issue the following command:
exit
TensorRT performance evaluation
In the following section, you build, run, and evaluate the performance of BERT in TensorFlow. Before proceeding, make sure that you have downloaded and set up the TensorRT GitHub repo.
Set up a Docker container
In this step, you build and launch the Docker image from Dockerfile for TensorRT.
On your host machine, navigate to the TensorRT directory:
cd TensorRT
The script docker/build.sh builds the TensorRT Docker container:
./docker/build.sh --file docker/ubuntu.Dockerfile --tag tensorrt-ubuntu --os 18.04 --cuda 11.0
After the container is built, you must launch it by executing the docker/launch.sh script. However, before launching the container, modify docker/launch.sh to add -v $MODEL_DIR:/finetuned-model-bert and -v $BERT_DIR/data/download/squad/v1.1:/data/squad in docker_args to pass in your fine-tuned model and squad dataset, respectively.
The docker_args at line 49 should look like the following code:
docker_args="$extra_args -v $MODEL_DIR:/finetuned-model-bert -v $BERT_DIR/data/download/squad/v1.1:/data/squad -v $arg_trtrelease:/tensorrt -v $arg_trtsource:/workspace/TensorRT -it $arg_imagename:latest"
Now build and launch the Docker image locally:
./docker/launch.sh --tag tensorrt-ubuntu --gpus all --release $TRT_RELEASE --source $TRT_SOURCE
When you are in the container, you must build the TensorRT plugins:
cd $TRT_SOURCE export LD_LIBRARY_PATH=`pwd`/build/out:$LD_LIBRARY_PATH:/tensorrt/lib mkdir -p build && cd build cmake .. -DTRT_LIB_DIR=$TRT_RELEASE/lib -DTRT_OUT_DIR=`pwd`/out make -j$(nproc) pip3 install /tensorrt/python/tensorrt-7.1*-cp36-none-linux_x86_64.whl
Now you are ready to build the BERT TensorRT engine.
Build the TensorRT engine
Make a directory to store the TensorRT engine:
mkdir -p /workspace/TensorRT/engines
Optionally, explore /workspace/TensorRTdemo/BERT/scripts/download_model.sh to see how you can use the ngc registry model download-version command to download models from NGC.
Run the builder.py script, noting the following values:
- Path to the TensorFlow model
/finetuned-model-bert/model.ckpt-<num>/li> - Output path for the engine to be built
- Batch size 1
- Sequence length 384
- Precision fp16
- Checkpoint path
/finetuned-model-bert
cd /workspace/TensorRT/demo/BERT python3 builder.py -m /finetuned-model-bert/model.ckpt-5474 -o /workspace/TensorRT/engines/bert_large_384.engine -b 1 -s 384 --fp16 -c /finetuned-model-bert/
Make sure that you provide the correct checkpoint model. The script takes ~1-2 mins to build the TensorRT engine.
Run the TensorRT inference
Now run the built TensorRT inference engine on 2K samples from the SQADv1.1 evaluation dataset. To run and get the throughput numbers, replace the code from line number 222 to line number 228 in inference.py, as shown in the following code block.
Be mindful of indentation. If the prompt asks for a password while you are installing vim in the container, use the password nvidia.
if squad_examples:
eval_time_l = []
all_predictions = collections.OrderedDict()
for example_index, example in enumerate(squad_examples):
print("Processing example {} of {}".format(example_index+1, len(squad_examples)), end="\r")
features = question_features(example.doc_tokens, example.question_text)
eval_time_elapsed, prediction, nbest_json = inference(features, example.doc_tokens)
eval_time_l.append(1.0/eval_time_elapsed)
all_predictions[example.id] = prediction
if example_index+1 == 2000:
break
print("Throughput Average (sentences/sec) = ",np.mean(eval_time_l))
Now run the inference:
CUDA_VISIBLE_DEVICES=0 python3 inference.py -e /workspace/TensorRT/engines/bert_large_384.engine -b 1 -s 384 -sq /data/squad/dev-v1.1.json -v /finetuned-model-bert/vocab.txt Throughput Average (sentences/sec) = 136.59
We observed that inference speed is 136.59 sentences per second for running inference with TensorRT 7.1 on a system powered with a single NVIDIA T4 GPU. Performance may differ depending on the number of GPUs and the architecture of the GPUs, where the data is stored and other factors. However, you’ll always observe a performance boost due to model optimization using TensorRT.
Figure shows that the TensorRT BERT engine gives an average throughput of 136.59 sentences/sec compared to 106.56 sentences/sec given by the BERT model in TensorFlow. This is a 28% boost in throughput.
Summary
Pull the TensorRT container from NGC to easily and quickly performance tune your models in all major frameworks, create novel low-latency inference applications, and deliver the best quality of service (QoS) to customers.
