
Data is one of the most valuable assets that a business can possess. It sits at the core of data science and data analysis: without data, they’re both obsolete. Businesses that actively collect data may have a competitive advantage over those that do not. With sufficient data, organizations can better determine the cause of problems and make informed decisions.
There are scenarios where an organization may lack sufficient data to draw necessary insights. For example, a start-up almost always begins with no data. Instead of moping about their deficiencies, a better solution is to employ data acquisition techniques to help build a custom database.
This post covers a popular data acquisition technique called web scraping. You can follow along using the code in the kurtispykes/web-scraping-real-estate-data GitHub repository.
What is data acquisition?
Data acquisition (also referred to as DAQ) may be as simple as a technician logging the temperature of your oven. You can define DAQ as the process of sampling signals that measure real-world physical phenomena and converting the resulting samples into digital numerical values that a computer can interpret.
In an ideal world, we would have all data handed to us, ready for use, whenever we wanted. However, the world is far from ideal. Data acquisition techniques exist because some problems require specific data that you may not have access to at a particular time. Before any data analysis can be conducted, the data team must have sufficient data available. One technique to acquire data is web scraping.
What is web scraping?
Web scraping is a popular data acquisition technique that has become a hot topic of discussion among those with rising demands for big data. Essentially, it’s the process of extracting information from the Internet and formatting it to be easily usable in data analytics and data science pipelines.
In the past, web scraping was a manual process. The process was tedious and time-consuming, and humans are prone to error. The most common solution is to automate. Automation of web scraping enables you to speed up the process while saving money and reducing the likelihood of human error.
However, web scraping has its challenges.
Challenges of web scraping
Building your own web scraper has challenges outside of knowing how to program and understanding HTML. It is beneficial to know in advance the various obstacles that you may encounter while data scraping. Here are a few of the most common challenges that you’ll face when scraping data from the web.
robots.txt
Permissions for scraping data are usually held in a robots.txt file. This file is used to inform crawlers about the URLs that can be accessed on a website. It prevents the site from being overloaded with requests.
The first thing to check before you begin a web scraping project is whether the target website permits web scraping. Websites can decide whether to allow web scrapers on their website for web scraping purposes.
Some websites do not permit automated web scraping, typically to prevent competitors from gaining a competitive advantage and draining the server resources from the target site. It does affect the website’s performance.
You can check the robots.txt file of a website by appending /robots.txt to the domain name. For example, check Twitter’s robots.txt as follows: www.twitter.com/robots.txt.
Structural changes
UI and UX developers periodically add, remove, and undergo regular structural changes to a website to keep it up to date with the latest advancements. Web scrapers depend on the code elements of the web page at the time that the scraper is built. Thus, frequent changes to a website may result in data being lost. It’s always a good idea to keep tabs on the changes to a web page.
Also, consider that different web page designers may have different criteria for designing their pages. This means that if you plan on scraping multiple websites, you might have to build multiple scrapers, one for each website.
IP blockers, or getting banned
It is possible to be banned from a website. If your web scraper is sending an unnaturally high number of requests to a website, it’s possible for your IP address to get banned. Alternatively, the website may restrict its access to break down the scraping process.
There’s a thin line between what is considered ethical and unethical web scraping: crossing the line quickly leads to IP blocking.
CAPTCHAs
A CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) does exactly what it says in its name: distinguishes humans from bots. The problems posed by CAPTCHAs are typically logical and straightforward for a human to solve but challenging for a bot to accomplish the same feat, which prevents websites from being spammed.
There are ethical workarounds for scraping websites with CAPTCHAs. However, that discussion is beyond the scope of this post.
Honeypot traps
In a similar fashion to how you would set up devices or enclosures to catch pests that invade your home, website owners set up honeypot traps to catch scrapers. These traps are typically links that are not visible by humans but are visible to web scrapers.
The intention is to get information about the scraper, such as its IP address, so they can block the scraper’s access to the website.
Real-time data scraping
There are certain scenarios where you may need data to be scrapped in real time (for example, price comparisons). As changes can occur anytime, the scraper must constantly monitor the website and scrape data. Acquiring large amounts of data in real time is challenging.
Web scraping best practices
Now that you’re aware of the challenges you may face, it’s important to know the best practices to ensure that you are ethically scraping web data.
Respect robots.txt
One of the challenges that you’ll face when scraping web data is abiding by the terms of robots.txt. It is a best practice to follow the guides set by a website around what a web scrape can and cannot crawl.
If a website does not permit web scraping, it is unethical to scrape that website. It’s better to find another data source or contact the website owner directly and discuss a solution.
Be nice to servers
Web servers can only take so much. Exceeding a web server’s load results in the server crashing. Consider what may be an acceptable frequency of requests to make to a host’s server. Several requests in a short time span may result in server failure, which in turn disrupts the user experience for other visitors to the website.
Maintain a reasonable time lapse between requests and be considerate with the number of parallel requests.
Scrape during off-peak hours
Understand when a website may receive its most traffic and refrain from scraping during these hours. Your goal is not to hamper the user experience of other visitors. It’s your moral responsibility to scrape when a website receives less traffic. (This also works in your favor as it significantly improves the speed of your scraper.)
Scrapy tutorial
Web scraping in Python usually involves coding several menial tasks from scratch. However, Scrapy, an open-source web crawling framework, deals with several of the common start-up requirements by default. This means that you can focus on extracting the data that you need from the target websites.
To demonstrate the power of Scrapy, you develop a spider, which is a Scrapy class where you define the behavior of your web scraper. Use this spider to scrape all the listings from the Boston Realty Advisors website (Figure 1).
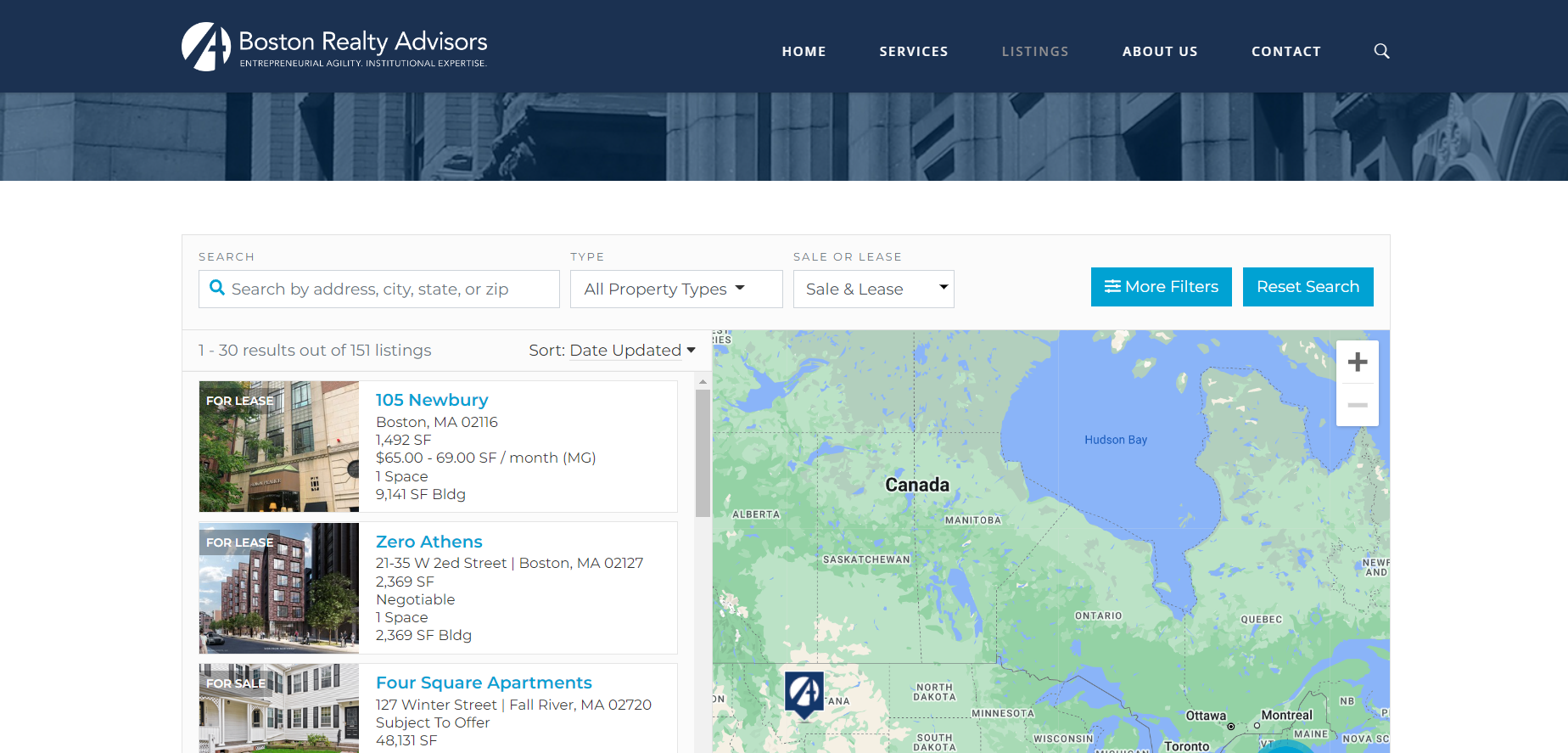
Inspecting the target website
Before starting any web scraping project, it is important to inspect the target website to scrape. The first thing that I like to check when examining a website is whether the pages are static or generated by JavaScript.
To bring up the developer toolbox, press F12. On the Network tab, make sure that Disable cache is checked.
To bring up the command palette, press CTRL + SHIFT + P (Windows \ Linux) or Command + SHIFT + P (Mac). Type Disable JavaScript, then press Enter and reload the target website.
Figure 2 shows how the Boston Realty Advisors website looks without JavaScript.
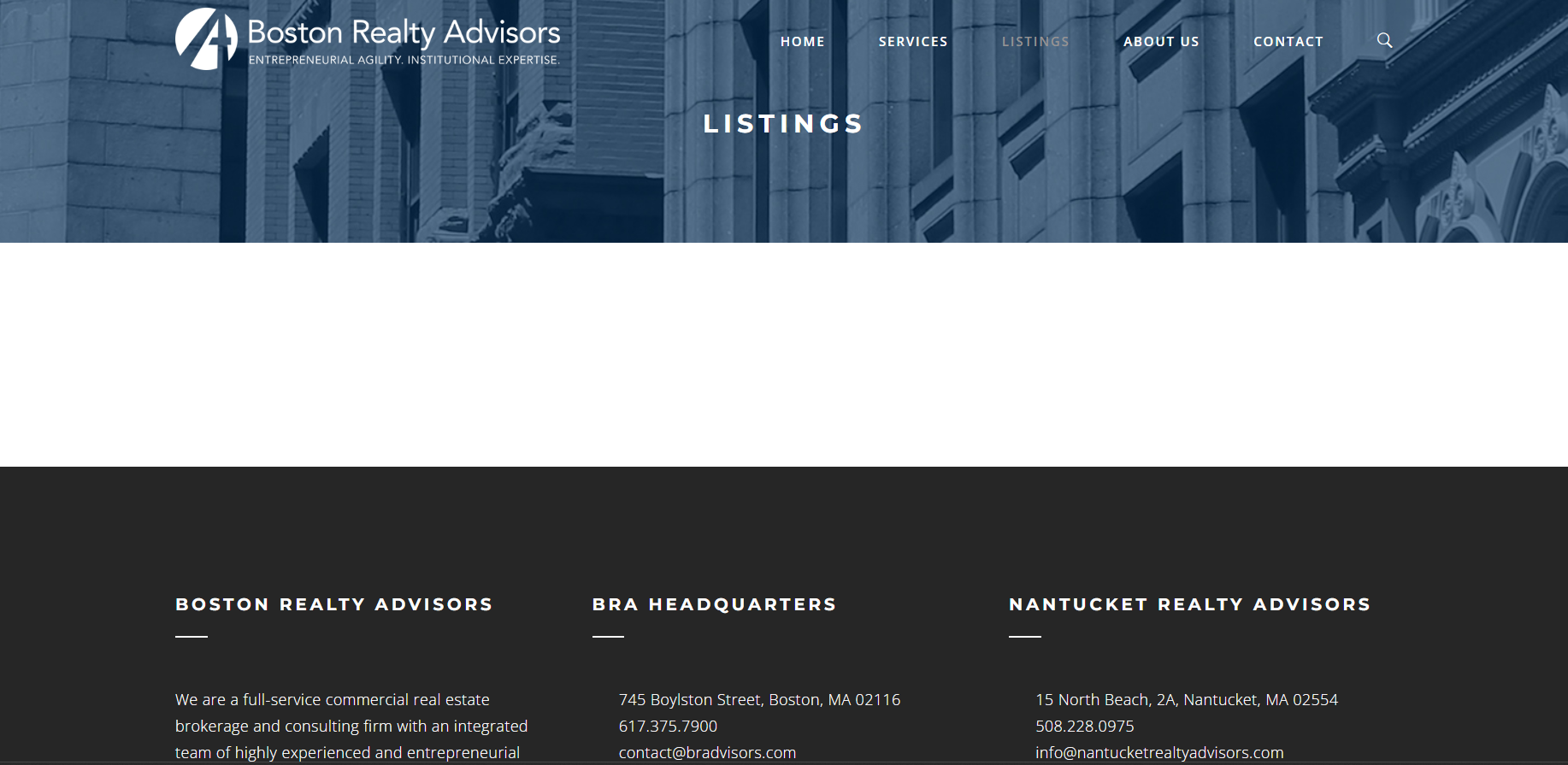
The empty page tells you that the target web page is generated using JavaScript. You can’t scrape the page by trying to parse the HTML elements displayed in the Elements tab of the developer toolbox. Re-enable JavaScript in the developer tools and reload the page.
There’s more to examine.
In the developer toolbox, choose the XHR (XML HTTP Request) tab. After browsing the requests sent to the server, I noticed something interesting. There are two requests called “inventory,” but in one, you have access to all the data on the first page in JSON.
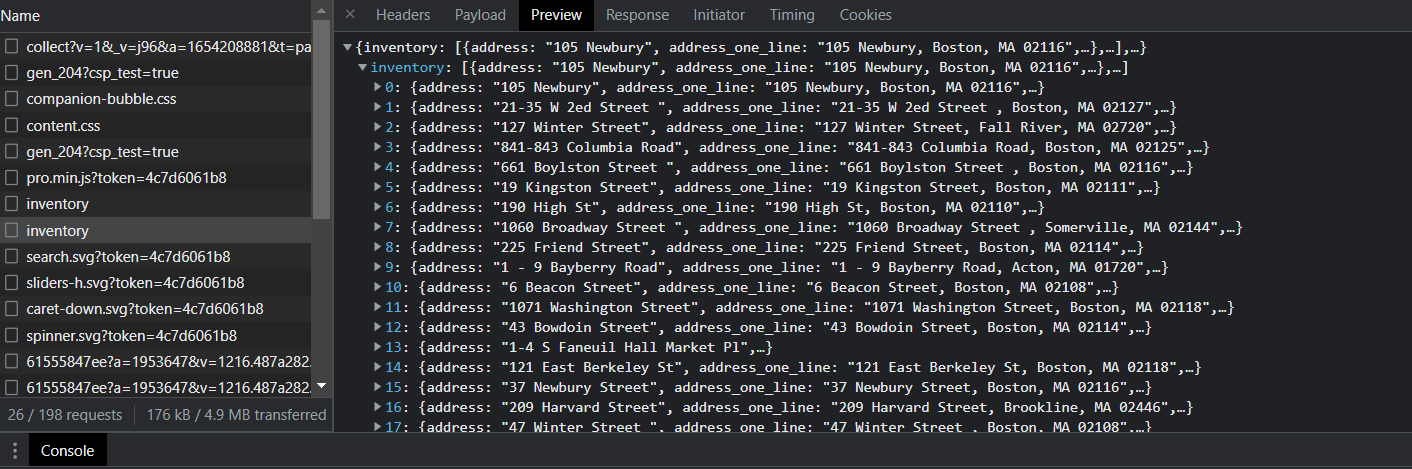
This information is great because it means that you don’t have to visit the main listing page on the Boston Realty Advisors website to get access to the data you want.
Now you are ready to begin scraping. (I did more inspections to better understand how to mimic the requests being made to the server, but that is beyond the scope of this post.)
Creating the Scrapy project
To set up the Scrapy project, first install scrapy. I recommend doing this step in a virtual environment.
pip install scrapy
After the virtual environment is activated, enter the following command:
scrapy startproject bradvisors
This command creates a Scrapy project called bradvisors. Scrapy also automatically adds some files to the directory.
After running the command, the final directory structure looks like the following tree:
. └── bradvisors ├── bradvisors │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ └── __init__.py └── scrapy.cfg
So far, you’ve inspected the elements of the website to scrape and created the Scrapy project.
Building the spider
The spider module must be built in the bradvisors/bradvisors/spiders directory. The name of my spider script is bradvisors_spider.py but you can use a custom name.
The following code extracts the data from this website. The code example only runs successfully when the items.py file is updated. For more information, see the explanation after the example.
import json
import scrapy
from bradvisors.items import BradvisorsItem
class BradvisorsSpider(scrapy.Spider):
name = "bradvisors"
start_urls = ["https://bradvisors.com/listings/"]
url = "https://buildout.com/plugins/5339d012fdb9c122b1ab2f0ed59a55ac0327fd5f/inventory"
headers = {
'authority': 'buildout.com',
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
'cache-control': 'no-cache',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'origin': 'https://buildout.com',
'pragma': 'no-cache',
'referer': 'https://buildout.com/plugins/5339d012fdb9c122b1ab2f0ed59a55ac0327fd5f/bradvisors.com/inventory/?pluginId=0&iframe=true&embedded=true&cacheSearch=true&=undefined',
'sec-ch-ua': '"Google Chrome";v="105", "Not)A;Brand";v="8", "Chromium";v="105"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'x-newrelic-id': 'Vg4GU1RRGwIJUVJUAwY=',
'x-requested-with': 'XMLHttpRequest'
}
def parse(self, response):
url = "https://buildout.com/plugins/5339d012fdb9c122b1ab2f0ed59a55ac0327fd5f/inventory"
# There are 5 pages on the website
for i in range(5):
# Change the page number in the payload
payload = f"utf8=%E2%9C%93&polygon_geojson=&lat_min=&lat_max=&lng_min=&lng_max=&mobile_lat_min=\
&mobile_lat_max=&mobile_lng_min=&mobile_lng_max=&page={str(i)}&map_display_limit=500&map_type=roadmap\
&custom_map_marker_url=%2F%2Fs3.amazonaws.com%2Fbuildout-production%2Fbrandings%2F7242%2Fprofile_photo\
%2Fsmall.png%3F1607371909&use_marker_clusterer=true&placesAutoComplete=&q%5Btype_use_offset_eq_any%5D%5B%5D=\
&q%5Bsale_or_lease_eq%5D=&q%5Bbuilding_size_sf_gteq%5D=&q%5Bbuilding_size_sf_lteq%5D=&q%5B\
listings_data_max_space_available_on_market_gteq%5D=&q%5Blistings_data_min_space_available_on_market_lteq\
%5D=&q%5Bproperty_research_property_year_built_gteq%5D=&q%5Bproperty_research_property_year_built_lteq\
%5D=&q%5Bproperty_use_id_eq_any%5D%5B%5D=&q%5Bcompany_office_id_eq_any%5D%5B%5D=&q%5Bs%5D%5B%5D="
# Crawl the data, given the payload
yield scrapy.Request(method="POST", body=payload, url=url, headers=self.headers, callback=self.parse_api)
def parse_api(self, response):
# Response is json, use loads to convert it into Python dictionary
data = json.loads(response.body)
# Our item object defined in items.py
item = BradvisorsItem()
for listing in data["inventory"]:
item["address"] = listing["address_one_line"]
item["city"] = listing["city"]
item["city_state"] = listing["city_state"]
item["zip"] = listing["zip"]
item["description"] = listing["description"]
item["size_summary"] = listing["size_summary"]
item["item_url"] = listing["show_link"]
item["property_sub_type_name"] = listing["property_sub_type_name"]
item["sale"] = listing["sale"]
item["sublease"] = listing["sublease"]
yield item
The code accomplishes the following tasks:
- Defines the name of the scraper as
bradvisors. - Defines the headers to pass with the request.
- Specifies that the
parsemethod is the automatic call back when the scraper is run. - Defines the
parsemethod, where you iterate through the number of pages to scrape, pass the page number to the payload, and yield that request. This calls back theparse_apimethod on each iteration. - Defines the
parse_apimethod and converts the valid JSON response into a Python dictionary. - Defines the
BradvisorsItemclass initems.py(next code example). - Loops through all the listings in the inventory and scrapes specific elements.
# items.py import scrapy class BradvisorsItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() address = scrapy.Field() city = scrapy.Field() city_state = scrapy.Field() zip = scrapy.Field() description = scrapy.Field() size_summary = scrapy.Field() item_url = scrapy.Field() property_sub_type_name = scrapy.Field() sale = scrapy.Field()
Next, you must execute the scrape to parse the data.
Running the scraper
Navigate to the project’s root directory from the command line (in this case, that is bradvisors). Run the following command:
scrapy crawl bradvisors -o data.csv
This command scrapes the Boston Realty Advisors website and saves the extracted data in a data.csv file in the project’s root directory.
Great, you have now acquired real estate data!
What’s next?
As the demand for big data grows, equipping yourself with the ability to acquire data with a web scraping tool is an extremely valuable skill set. Scraping data from the Internet can present several challenges. As well as acquiring the data that you require, your goal should be to treat websites respectfully and scrape them ethically.
Did you find this Scrapy tutorial helpful? Leave your feedback in the comments or connect with me:
Web scraping FAQ
Is web scraping illegal?
No, web scraping is legal, given that the data you are scraping is public. Search engines such as Google scrape web data daily to curate search results for their users.
Is web scraping free?
You can pay for web scraping services to simplify the web scraping process. You could also learn a programming language and do it yourself for free.
What tools can I use for web scraping in Python?
There are several tools for web scraping in Python, such as Beautiful Soup, MechanicalSoup, Requests (Python module), Scrapy, Selenium, and Urllib.