
NVIDIA announces the newest release of the CUDA development environment, CUDA 11.5. CUDA 11.5 is focused on enhancing the programming model and performance of your CUDA applications. CUDA continues to push the boundaries of GPU acceleration and lay the foundation for new applications in HPC, visualization, AI, ML and DL, and data sciences.
CUDA 11.5 has several important features. This post offers an overview of the key capabilities:
- CUDA Programming model enhancements
- Scan collectives in Cooperative Groups
- Normalized Integer Formats
- Block compressed formats
- Configurable cache hinting in C++
- MPS Enhancements (Client memory limits)
- CUDA on WSL driver update
- CUDA Python GA
- GPUDirect Storage (GDS) release v1.1
- Deprecation of the NVIDIA Kepler driver
- CUDA C++ (For more information, see Reducing Application Build Times Using CUDA C++ Compilation Aids)
- Nsight Compute/Systems tools
CUDA 11.5 ships with the R495 driver, a new feature branch. CUDA 11.5 is available to download.
CUDA programming model enhancements
This release introduced key enhancements to improve the usability and performance of CUDA Graphs without requiring any modifications to the application or any other user intervention. It also improves the ease of use of Multi-Process Service (MPS). We formalized the asynchronous programming model in the CUDA Programming Guide.
Scan collectives in cooperative groups
Along with reductions and barriers, prefix sums—also known as scans—are a cornerstone of parallel computing. The scan operation takes a binary operator, often addition, and iterates over an input array applying that operator cumulatively. Scans may be inclusive, including all elements x[0] … x[n], or exclusive iterating over the range {0, x[0] … x[n-1]}.
For example, an exclusive scan with the + operator of an input array [3 1 7 0 4 1 6 3] would result in the following:
[0 3 4 11 11 15 16 22]
CUDA 11.5 adds a new header, <cg/scan.h>, which defines four new functions in the cooperative groups namespace to implement these operations.
| Inclusive Scan | Exclusive Scan | Description |
template<typename Group, typename T, typename OpType> | template<typename Group, typename T, typename OpType>T exclusive_scan(const Group& g, T&& val, OpType&& op) ; | Perform scan using user supplied binary operator. |
template<typename Group, typename T> | template<typename Group, typenameT> | Same as above with assumed op == plus<T>; |
The return type must match the input value type in all cases.
Normalized integer data types
Normalized signed and unsigned 8-bit and 16-bit data types are some of the most widely supported texture formats by GPU programming languages. CUDA has had support for the use of these formats with texture objects for some time, but in the 11.5 release, we expand our existing support for these data types to make interoperating with other external APIs more intuitive.
We introduce new CUDA array formats in both the Driver and Runtime APIs. The Driver API exposes 12 new array formats as follows:
CU_AD_FORMAT_UNORM_INT8X{1|2|4}
CU_AD_FORMAT_UNORM_INT16X{1|2|4}
CU_AD_FORMAT_SNORM_INT8X{1|2|4}
CU_AD_FORMAT_SNORM_INT16X{1|2|4}These can be used to create 1-, 2- or 4-channel CUDA arrays. The Runtime API similarly exposes 12 new equivalent channel formats:
cudaChannelFormatKindUnsignedNormalized8X{1|2|4}
cudaChannelFormatKindSignedNormalized8X{1|2|4}
cudaChannelFormatKindUnsignedNormalized16X{1|2|4}
cudaChannelFormatKindSignedNormalized16X{1|2|4}These can also be used to create 1-, 2- or 4-channel, 8-bit or 16-bit channel width CUDA arrays. Also, you can now import matching formatted textures from external APIs such as DirectX12/11 or Vulkan, and map those as CUDA arrays. When creating a texture object with a resource view, the format texel size must match the array texel size.
For texture objects, they can be created and accessed as shown in the following code example:
cudaArray_t array;
cudaChannelFormatDesc formatDesc = {8, 8, 0, 0, cudaChannelFormatKindUnsignedNormalized8X2};
cudaMallocArray(&array, formatDesc, width, height);
cudaTextureDesc texDesc = {0};
texDesc.addressMode[0] = texDesc.addressMode[1] = cudaAddressModeClamp ;
// (3) Create CUDA texture object
cudaResourceDesc resDesc = {0};
resDesc.resType = cudaResourceTypeArray;
resDesc.res.array = array;
cudaCreateTextureObject(&texObj, &resDesc, &texDesc, NULL);
// Read from texture object in a kernel as follows:
// float4 texel = tex2D<float4>(texture, x, y);
// (6) Release all resources
cudaDestroyTextureObject(texObj);
cudaFreeArray(array);And, similarly, for surface objects:
cudaArray_t array;
cudaChannelFormatDesc formatDesc = {16, 16, 16, 16, cudaChannelFormatKindSignedNormalized16X4};
cudaMallocArray(&array, formatDesc, width, height);
// (3) Create CUDA surface object
cudaResourceDesc resDesc = {0};
resDesc.resType = cudaResourceTypeArray;
resDesc.res.array = array;
cudaCreateSurfaceObject(&surfObj, &resDesc);
// Read/Write to/from surface object in a kernel as follows
// Read:
// short4 texel = surf2DRead(surface, xInBytes, y);
// Unformatted stores:
// surf2DWrite<short4>(texel, surface, xInBytes, y);
// Formatted stores: (Formatted surface stores are currently not exposed in CUDA runtime device functions)
// sust.p.2d.v4.b32
// (6) Release all resources
cudaDestroySurfaceObject(surfObj);
cudaFreeMipmappedArray(array);Support for block compressed data types
In all graphics programming languages and frameworks, one of the most common lossy compression techniques used for reducing texture sizes is the use of block-compressed (BC) texture formats. Using these formats can have significant savings on a texture’s memory footprint. There are several BC formats, each with unique benefits and drawbacks, which are commonly referred to as BCn formats.
NVIDIA GPU architecture supports BCn formats natively and already had limited support in CUDA through texture resource views. We now introduce new BC CUDA array formats in the driver and runtime APIs.
| Driver API Format | Runtime API Format | Channel Count | Channel Width in Bits |
CU_AD_FORMAT_BC1_UNORM | cudaChannelFormatKindUnsignedBlockCompressed1 | 4 | [8,8,8,8] |
CU_AD_FORMAT_BC2_UNORM | cudaChannelFormatKindUnsignedBlockCompressed2 | 4 | [8,8,8,8] |
CU_AD_FORMAT_BC3_UNORM | cudaChannelFormatKindUnsignedBlockCompressed3 | 4 | [8,8,8,8] |
CU_AD_FORMAT_BC4_UNORM | cudaChannelFormatKindUnsignedBlockCompressed4 | 1 | [8,0,0,0] |
CU_AD_FORMAT_BC5_UNORM | cudaChannelFormatKindUnsignedBlockCompressed5 | 2 | [8,8,0,0] |
CU_AD_FORMAT_BC6H_UF16 | cudaChannelFormatKindUnsignedBlockCompressed6H | 3 | [16,16,16,0] |
CU_AD_FORMAT_BC7_UNORM | cudaChannelFormatKindUnsignedBlockCompressed7 | 4 | [8,8,8,8] |
These formats can be used to create BCn formatted CUDA arrays using the cudaMalloc[3D]Array runtime API or cuArray[3D]Create driver API. Similarly, CUDA mipmapped arrays can be created using the cudaMallocMipmappedArray runtime API or cuMipmappedArrayCreate driver API. When creating CUDA arrays with these formats, the array extents must be multiples of the compression block size (4 x 4 for 2D and 4 x 4 x 1 for 3D). These arrays can also be used to create texture objects.
Configurable cache hinting in C++
In Discovering New Features in CUDA 11.4, we introduced a PTX ISA extension to provide caching hints to the compiler and runtime for data resident on the GPU. In CUDA 11.5, we extend this capability into C++ with annotated pointers. These act as normal pointers with additional attributes applied.
Annotated pointers are created using functions defined in <cuda/annotated_ptr>, with the cache residency hint defined as one of the following:
cuda::access_property::normal (evict_normal_demote)
cuda::access_property::streaming (evict_first)
cuda::access_property::persisting (evict_last)
cuda::access_property::shared (shared memory)
cuda::access_property::global (evict_normal)For example, in your kernel code declaring and using an annotated pointer can look like the following code:
static __device__
void my_kernel(int * in, int * out) {
cuda::access_property ap(cuda::access_property::persisting{});
// Retrieve global id
int i = blockIdx.x * blockDim.x + threadIdx.x;
cuda::annotated_ptr<int, cuda::access_property> in_ann{in, ap};
cuda::annotated_ptr<int, cuda::access_property> out_ann{out, ap};
...
}MPS enhancements (client memory limits)
When your GPU’s compute capacity outstrips any single application, running multiple application processes that share the same GPU hardware can be attractive. The Multi-Process Service (MPS) runtime architecture controls the simultaneous use of a single GPU by multiple independent processes.
When multiple independent processes are sharing the GPU, however, it can often be useful to set overall memory allocation limits to avoid any single process consuming too much of the available GPU memory.
In CUDA 11.5, we introduce a new set of control mechanisms to enable you to limit the allocation of pinned memory for MPS client processes. You have control over memory allocation through the default global limit hierarchy.
Default global limit
A default global memory limit can be enabled explicitly by using the set_default_device_pinned_mem_limit control command for the device. Setting this command enforces a device pinned memory limit on all MPS clients of all future MPS servers spawned.
$nvidia-cuda-mps-control set_default_device_pinned_mem_limit 0 2GPer-server limit: For a finer grained control on the memory resource limit, you can set the limit selectively on specific MPS servers using the set_device_pinned_mem_limit control command. Setting this command enforces a device pinned memory limit on all MPS clients of the specific MPS server.
$nvidia-cuda-mps-control set_device_pinned_mem_limit <pid> 1 1GPer-client limit: The preceding two control mechanisms set a blanket limit of all MPS clients for the specific MPS servers. Users wanting finer control over resource limits; that is, on a per-MPS-client basis, can do so by setting the CUDA_MPS_PINNED_DEVICE_MEM_LIMIT environment variable separately for each client process.
This environment variable has the same semantics as CUDA_VISIBLE_DEVICES. The value string can contain comma-separated device ordinals and device UUIDs with per-device memory limits separated by an equals symbol (=).
$export CUDA_MPS_PINNED_DEVICE_MEM_LIMIT="0=1G,1=2G,GPU-7ce23cd8-5c91-34a1-9e1b-28bd1419ce90=1024M"CUDA on WSL driver
NVIDIA Windows GPU Driver for Intel x86 architectures will support WSL2 and will be accessible outside the Windows Insider Preview (WIP) program for Windows 11. For CUDA on WSL support details, see the support matrix and the limitations section of the CUDA on WSL User’s Guide.
CUDA Python
CUDA Python provides Cython bindings and Python wrappers for the driver and runtime API for existing toolkits and libraries to simplify GPU-based accelerated processing. Python is one of the most popular programming languages for science, engineering, data analytics, and deep learning applications. The goal of CUDA Python is to unify the Python ecosystem with a single set of interfaces that provide full coverage of, and access to, the CUDA host APIs from Python.
Library developers can use CUDA Python’s low-level interface to CUDA directly from Python. We are excited to announce that, as of the 11.5 release, CUDA Python is generally available and can be installed using PIP or Conda. The library is supported on all platforms supported by CUDA.
GPUDirect Storage (GDS)
GDS enables a direct data path for direct memory access (DMA) transfers between GPU memory and storage. This direct path increases system bandwidth and decreases the latency and utilization load on the CPU.
GDS release 1.1, supports these new features:
- Beta support for a local XFS file system
- Performance improvements
- User-configurable priority for internal
cuFileCUDA streams
To learn more about GDS, how it works, how to use it, and performance benefits of reducing dependency on the CPU to process storage data transfers, see this GPUDirect Storage: A Direct Path Between Storage and GPU Memory blog post.
Deprecation of the NVIDIA Kepler driver
The NVIDIA Kepler microarchitecture was first introduced in 2012 and has since been phased out. For all NVIDIA Kepler-based SKUs, R470 is the last driver branch supported; and, we have removed driver support starting with the R495 release.
However, CUDA Toolkit development tools and support for select NVIDIA Kepler datacenter SKUs will continue throughout future CUDA 11.x releases.
C++ language support for CUDA
As part of this release, there are some key C++ language enhancements supported by CUDA 11.5.
- The CUDA C++ compiler added support for concurrent compilation in NVRTC and PTX to improve compilation time. The compiler can now also detect unused CUDA kernels and eliminate them, reducing compilation time, binary size, and overall performance from better code optimizations.
- Limited support for 128-bit integer values is released as a preview feature for user feedback, along with introducing a static library version of NVRTC and extending host compiler support to include Clang 12.0.
- CUDA C++ compiler has features that we are covering in-depth in the Reducing Application Build Times Using CUDA C++ Compilation Aids post.
- NVIDIA C++ Standard Library (libcu++) 1.5.0 was released with CUDA 11.4.
- Thrust 1.12.0 has the new thrust::universal_vector API that enables you to use the CUDA unified memory with Thrust.
Nsight developer tools
New versions are now available for NVIDIA Nsight Developer Tools: Nsight System 2021.4, Nsight Compute 2021.3, and Nsight Graphics 2021.4.2 for performance improvement with profiling and debugging of CUDA code.
Newly released Nsight Systems 2021.4 improves profiling with Windows, Direct3D12, and Vulkan support. This release adds features to help better understand process execution with OS interrupts, and added data capture to identify packet queuing bottlenecks. Feature highlights include:
- Windows ISR and DPC traces
- GPU hardware-based scheduling trace
- Windows Direct3D12
- Vulkan correlation to WDDM events
- NVTX event categorization support
- Multi-report loading of various system environments
For more information, see the Download Center.
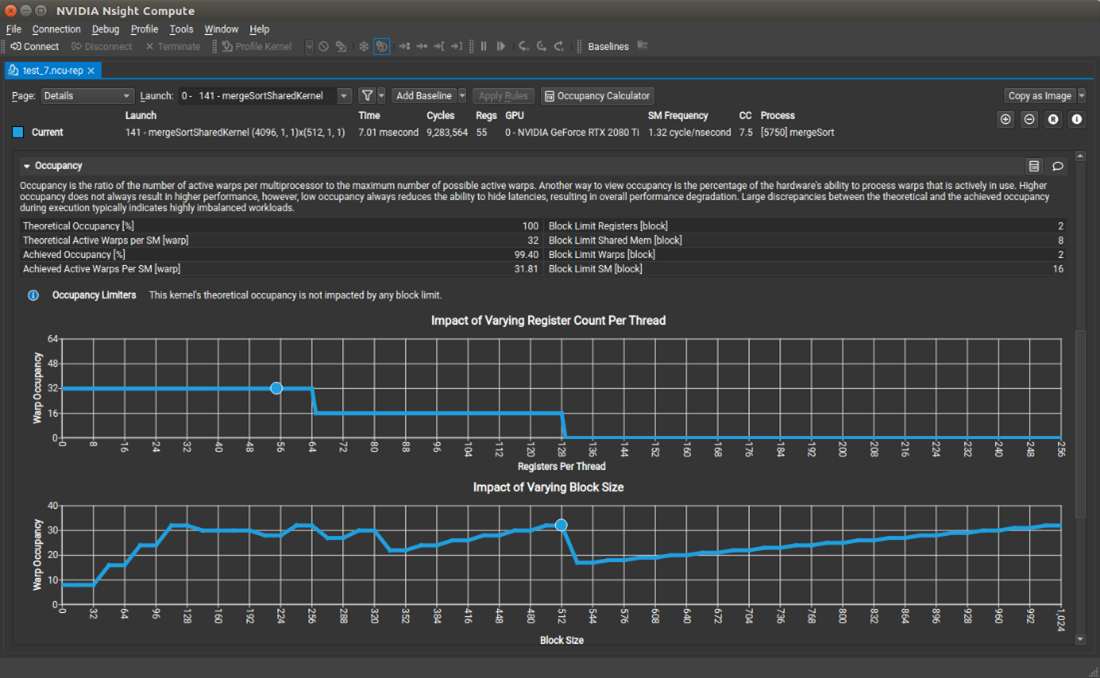
Nsight Compute 2021.3 adds several features to help users understand the performance of their CUDA kernels. The new Occupancy Calculator activity models the resource utilization of CUDA kernels, so that you can interactively adjust model parameters to see how they could affect occupancy. The roofline chart now supports a hierarchical offline, which represents additional levels in the memory hierarchy in addition to device memory. You can see if your kernels have bottlenecks related to cache memory access requests.
There are additional improvements including more configurable Baseline comparisons, visibility into source-level information from the CLI, and additional SSH functionality. For more information about Nsight developer tools new features, see the release notes and download page.
The latest Nsight Graphics 2021.4.2 now includes support for Windows 11. This means you can now download the NVIDIA Graphics Debugger and Profiler for Direct3D and Vulkan to create stunning 3D graphics on the most cutting-edge version of Windows.
For more information, see the following resources:
- Understanding CUDA application behavior, performance, and optimization just got easier with the latest developer tools
- NVIDIA Developer Tools Overview
- Download the tools
At GTC, we present advanced optimization features with Nsight Developer Tools in several sessions. Sign up for free.
For more information about the CUDA 11 Family toolkit capabilities with an overview of existing features, see the CUDA 11 Features Revealed post, and any past CUDA-related posts.
Download CUDA 11.5.