Building AI models from scratch requires enormous amounts of data, time, money, and expertise. This is at odds with what it takes to succeed in the AI space: fast time-to-market and the ability to quickly evolve and customize solutions. NVIDIA TAO, an AI-Model-Adaptation framework, enables you to leverage production-quality, pretrained AI models and fine-tune them in a fraction of the time compared to training from scratch.
To fine-tune these models further, or confirm the precision of your model, additional high-quality training data is required. Appen, a data annotation partner for TAO, provides access to high-quality datasets and services to label and annotate your data for your unique needs, if you don’t have the right data available.
In the post, I show you how you can use the NVIDIA TAO Toolkit, a CLI-based solution of the NVIDIA TAO framework, along with Appen’s data labeling platform to simplify the overall training process and create highly customized models for a particular use case.
After your team has identified a business problem to solve using ML, you can select from NVIDIA collection of pretrained AI models in computer vision and conversational AI. Computer vision models can include face detection models, text recognition, segmentation, and more. Then you can apply the TAO Toolkit to build, train, test, and deploy your solution.
To speed up the data collection and augmentation process, you can now use the Appen Data Annotation Platform to create the right training data for your use case. The robust platform enables you to access Appen’s global crowd of over one million skilled annotators from over 170 countries, speaking 235 languages. Appen’s data annotation platform and expertise also provide you with other resources:
- High-quality datasets (for when you need data)
- Human labelers sourced globally to annotate your unlabeled data
- An easy-to-use platform where you can launch annotation jobs and monitor key metrics
- Quality assurance checks and data security controls
With clean, high-quality data, you can adapt pretrained NVIDIA models to suit your requirements, pruning, and retraining to achieve the performance level that you need.
How to prepare your data using Appen’s platform
If you don’t already have data to use for training your model, you can either collect that data yourself or turn to Appen to source datasets that suit your use cases. The Appen Data Annotation Platform (ADAP) works with a diverse set of formats:
- Audio (.wav, .mp3)
- Image (.jpeg, .png)
- Text (.txt)
- Video (URL)
When you’re done with the data collection phase, unless you plan to work with Appen for your data collection needs, you can use Appen’s platform to quickly label the data you’ve collected. You need an Appen platform license and budget for each row of data annotation.
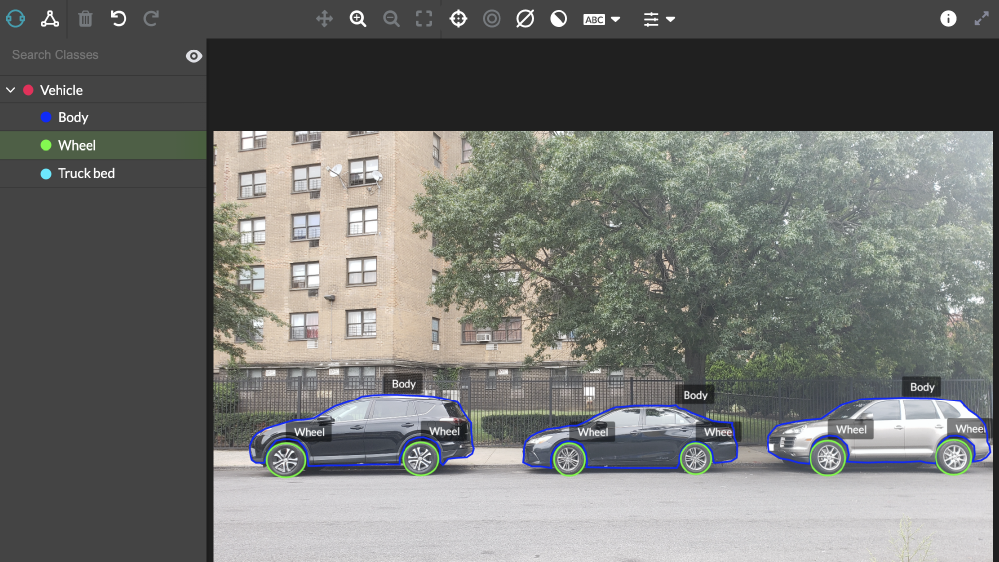
From there, work through the following steps to deploy a model that works specifically for your needs. For the purposes of this post, assume that you’re annotating images for an object detection model.
Prepare your data
First, load your image data into a web-accessible location: the cloud or a location that ADAP can access, such as a private Amazon S3 bucket.
Next, structure your input CSV file with two columns. The first column contains the filenames, and the second includes URLs to the images. You can provide the URLs in one of three ways:
- Use publicly available URLs for your data.
- Use presigned URLs.
- Use Appen’s Secure Data Access tool, which you can use to attach your database securely to the platform; Appen only accesses your data when needed.
The second column contains the local file name on your device. Figure 1 shows what your CSV file may look like.
Create your job and upload data
If you haven’t already, you can create an ADAP account and sign in. You must have an active license for the platform before running new jobs. To learn more about plans and pricing, contact Appen.
After logging in, under Jobs, choose Create a Job.
Select the template that best fits the job (sentiment analysis, search relevance, and so on). For this example, choose Image Annotation.
Under Image Annotation, choose Annotate and Categorize Objects in an Image Using a Bounding Box. Upload your CSV file by dragging and dropping it into the Upload tab.
Design your job
Provide guidelines for Appen’s crowd of over one million data labelers on what they should be looking for and any requirements that they should be aware of. The template provides a simple job design to help you get started.
Next, choose Manage the Image Annotation Ontology, where you’ll define the classes that should be detected. Update the instructions to give more context about your use case and describe how annotators should identify and label objects in images. You can preview your job and see how an annotator will view it.
Finally, create test questions to measure and track labeler performance.
Launch job
Do a test run first before officially launching your annotation job on the platform. After you’ve launched your job, Appen’s global crowd of data labelers annotate your data to your specifications.
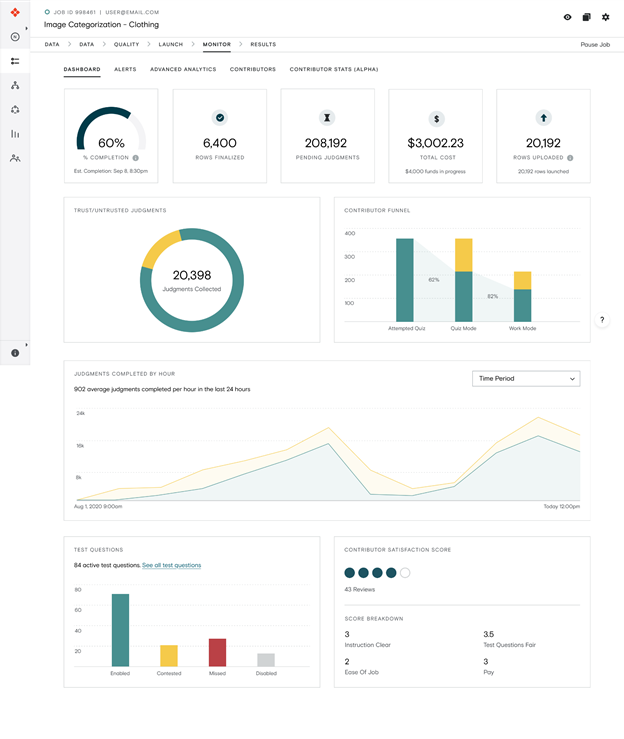
Monitor
Monitor the accuracy rate of annotations in real time. Adjust as needed in areas like job design, test questions, or annotators.
Results
Download a report of your labeled data output by choosing Download, Full.
Convert output to KITTI format
From here, you need a script to convert your labeled data to a format that’s feedable to the TAO Toolkit, such as KITTI format.
Using the output from the previous step, you can use the following section to convert your labeled data to a format like the Pascal Visual Object Classes (VOC) format. For the full code and guide on how to convert your data, see the /Appen/public-demos GitHub repo.
Training your model
Your data annotated with Appen can now be used to train your object detection model. The TAO Toolkit allows you to train, fine-tune, prune, and export highly optimized and accurate AI models for deployment by adapting popular network architectures and backbones to your data. For this example, you can choose a YOLOV3 Object Detection model, as in the following example:
First, download the notebook.
$ wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tlt_cv_samples/versions/v1.0.2/zip -O tlt_cv_samples_v1.0.2.zip $ unzip -u tlt_cv_samples_v1.0.2.zip -d ./tlt_cv_samples_v1.0.2 && rm -rf tlt_cv_samples_v1.0.2.zip && cd ./tlt_cv_samples_v1.0.2
After the notebook samples are downloaded, you may start the notebook using the following commands:
$ jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
Open the internet browser on localhost and open the following URL:
http://0.0.0.0:8888
Because you are creating a YOLOv3 model, open the yolo_v3/yolo_v3.ipynb notebook. Follow the notebook instructions to train the model.
Based on results, fine-tune the model until it achieves your metric goals. If desired, you can create your own active learning loop at this stage. Prioritize data based on confidence or another selection metric using the CSV file method as described in the preceding steps. You can also load data (including inputs and predictions) beforehand so Appen’s annotators can validate the model after it’s been trained, reviewing the predictions using our domain experts and open crowd.
Pro tip: Use Workflows, an Appen Solution, to build and automate multistep data annotation projects with ease.
Iterate
Appen can further assist you with data collection and annotation in subsequent rounds of model training as you iteratively improve on your model performance. To avoid model drift or to accommodate changing business requirements, retrain your model regularly.
Conclusion
NVIDIA TAO Toolkit combined with Appen’s data platform enables you to train, fine-tune, and optimize pretrained models to get your AI solutions off the ground faster. Speed up your development times by tenfold without sacrificing quality. With the help of integrated expertise and tools from NVIDIA and Appen, you’ll be ready to launch AI with confidence.
For more information, see the following resources:
