
Data plays a crucial role in creating intelligent applications. To create an efficient AI/ ML app, you must train machine learning models with high-quality, labeled datasets. Generating and labeling such data from scratch has been a critical bottleneck for enterprises. Many companies prefer a one-stop solution to support their AI/ML workflow from data generation, data labeling, model training/fine-tuning, and deployment.
To fast track the end-to-end workflow for developers, NVIDIA has been working with several partners who focus on generating large, diverse, and high-quality labeled data. Their platforms can be seamlessly integrated with NVIDIA Transfer Learning Toolkit (TLT) and NeMo for training and fine-tuning models. These efficiently trained and optimized models can then be deployed with NVIDIA DeepStream or NVIDIA Riva to create reliable computer vision or conversational AI applications.
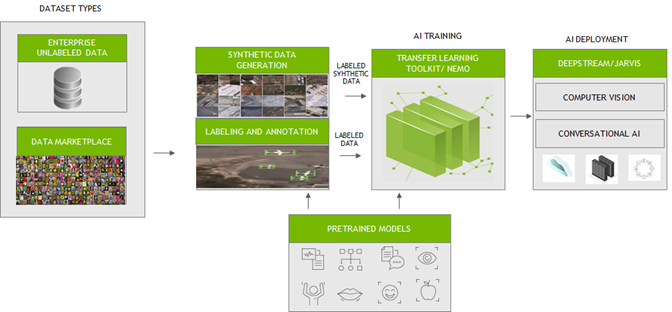
In this post, we outline the key challenges in data preparation and training. We also introduce how to integrate your data to fine-tune AI/ML models easily with our partner services.
Computer vision
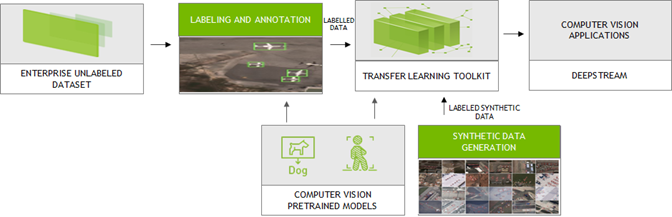
Large amounts of labeled data are needed to train computer vision neural network models. They could be collected from the real world or synthesized through models. High-quality labeled data enables neural network models to contextualize the information and generate accurate results.
NVIDIA integrated with the platforms from the following partners to generate and label synthetic custom data in the formats compatible with TLT for training. TLT is a zero-coding transfer learning toolkit using purpose-built, pretrained models. Trained TLT models can be deployed using the DeepStream SDK and achieve 10x speedup in development time.
AI Reverie and Sky Engine
Synthetic labeled data is becoming popular especially for computer vision tasks like object detection and image segmentation. Using the platforms from AI Reverie and Sky Engine, you can generate synthetic labeled data. AI Reverie offers a suite of synthetic data for model training and validation using 3D environments which exposes the neural network models to diverse scenarios that might be hard to find in data gleaned from the real world. Sky Engine uses ray-tracing image renderer techniques to generate labeled synthetic data in virtual environments that can be used with TLT for training.
Appen
With Appen, you can generate and label custom data. Appen uses APIs and human intelligence to generate labeled training data. Integrated with the NVIDIA Transfer Learning Toolkit, the Appen Data Annotation platform and services allow you to eliminate time-consuming annotations and create the right training data to train with TLT for your use cases.
Hasty, Labelbox, Sama, and Clarifai
Few provide straightforward tools for annotation. By simple clicks and selecting the region around the objects on the image, you can quickly generate the annotations. With Hasty, Labelbox, Sama, and Clarifai, you can label datasets in the formats compatible with TLT.
Hasty provides such tools like DEXTR and GrabCut to create labeled data. With DEXTR, you click on the north, south, east, and west of an object and a neural network looks for the mask. For GrabCut, you select the area where the object is and add or remove regions with markings to improve the results.
With Labelbox, you can upload the data for annotation and can easily export the annotated data using Python SDK to TLT for training purposes.
Sama follows a different labeling mechanism and therefore uses a pretrained object detection model (Figure 2) to perform inference. IT uses those annotations to further enhance the labels in generating accurate results.
Clarifai’s solution transforms unstructured image, video, text, and audio data into actionable insights.
All these tools are tightly coupled with TLT for training to develop production-quality vision models.
Conversational AI
A typical conversational AI application may be built with automatic speech recognition (ASR), natural language understanding (NLU), dialog management (DM) and text-to-speech (TTS) services. Conversational AI models are huge and require large amounts of data for training to recognize speech in noisy environments in different languages or accents, understand every nuance of language and generate human-like speech.
NVIDIA collaborates with DefinedCrowd, LabelStudio, and DataSaur. You can use their platforms to create large and labeled datasets that can then be directly introduced into NVIDIA NeMo for training or fine-tuning. NeMo is an open-source toolkit for developing state-of-the-art conversational AI models. NeMo models can be easily exported to Riva for inference, which can run an end-to-end conversational AI pipeline in less than 300ms.
DefinedCrowd
The popular approach for data generation/labeling is crowdsourcing. DefinedCrowd leverages a global crowd of over 500,000 contributors to collect, annotate, and validate training data by dividing the project into a series of micro-tasks through the online platform Neevo. The data is then used to train conversational AI models in a variety of languages, accents, and domains. You can now quickly download the data using the DefinedCrowd APIs and convert them into NeMo acceptable format for training.
LabelStudio
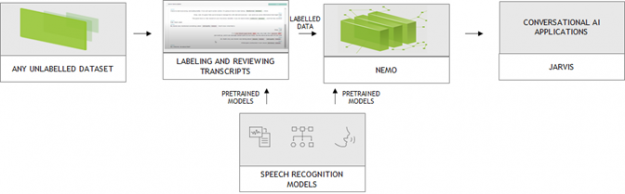
Advancement of machine learning models make AI-assisted data annotation possible, which significantly reduces labeling cost. More and more vendors are integrating AI capability to augment the labeling process. NVIDIA collaborated with Heartex who maintains the open-source LabelStudio and performs AI-assisted data annotation for speech. With this tool, you can now label speech data that is compatible with NeMo (Figure 3). Heartex also integrates NeMo into their workflow so that you can choose the pretrained NeMo models for speech pre-annotation.
Datasaur
For text labeling, there are easy-to-use tools that come with predefined labels which allow you to quickly annotate the data. For more information about how to annotate your text data and run Datasaur with NeMo for training, see Datasaur x NVIDIA NeMo Integration (video).
Conclusion
NVIDIA has partnered with many industry-leading data generation and annotation providers to speed up computer vision and conversational AI application workflows. This collaboration enables you to quickly generate superior quality data that can be readily used with TLT and NeMo for training models, which can then be deployed on NVIDIA GPUs with DeepStream SDK and Riva.
For more information, see the following resources:
