NVIDIA TAO
NVIDIA TAO is an advanced suite of skills and tools for post-training vision language and vision foundation models. These post-training tools can now be used as agentic workflows with natural language prompts. Coding agents use these tools and skills to autonomously hit model accuracy targets by evaluating performance, determining the precise training data needed, and then mining existing data or synthetically generating needed data.
This dramatically reduces the time and data needed to build high-performing AI solutions that are ready for deployment from the edge to the cloud.
Applicable across a wide variety of industries, TAO excels at delivering custom industrial AI models for visual inspection, quality control, and robotic guidance.
How TAO Works
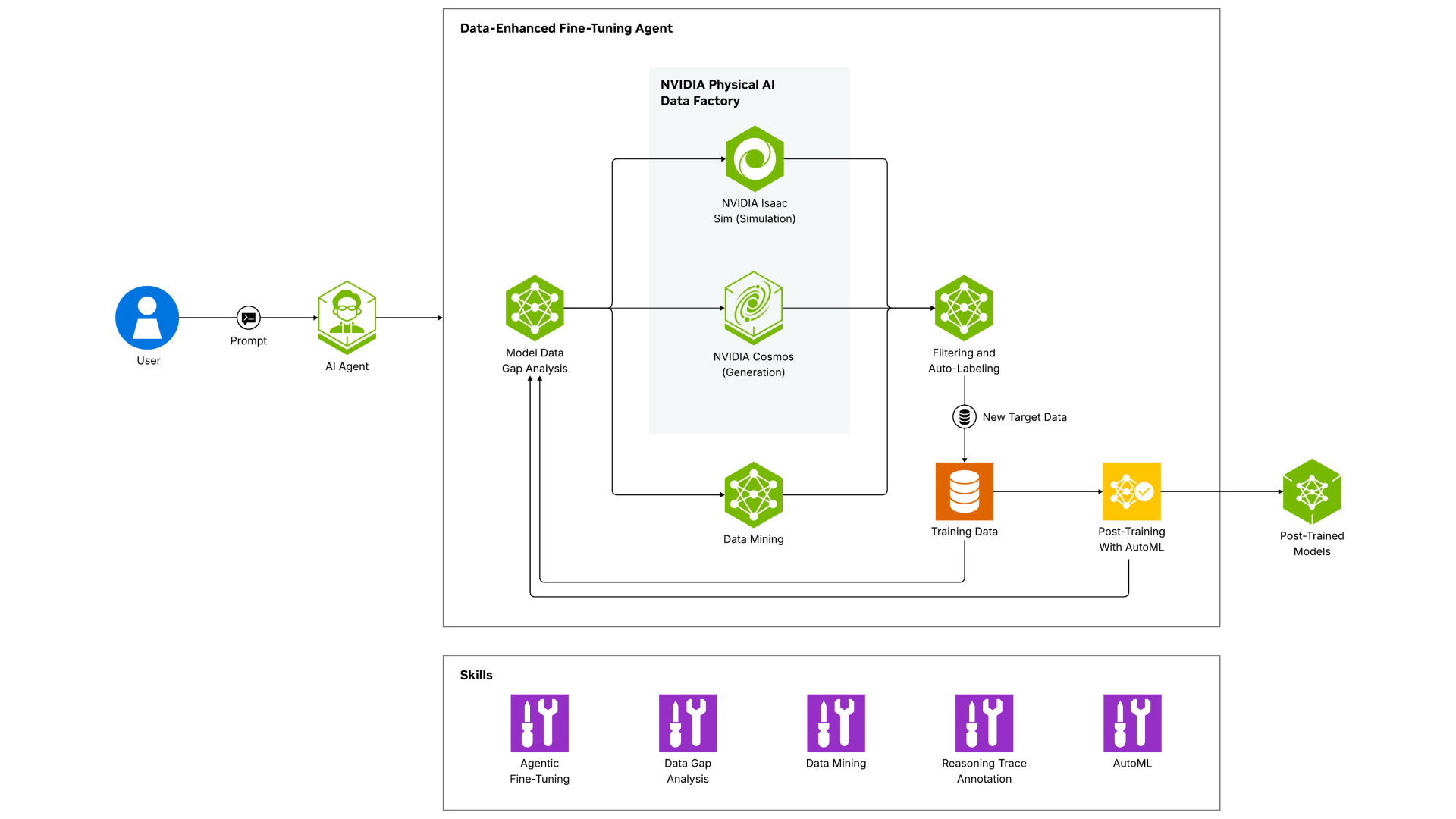
NVIDIA TAO agent skills and tools let you go from model post training to production deployment seamlessly with coding agents. The process begins with selecting a pretrained foundation model from the TAO model zoo or bringing a third-party model with an architecture supported by TAO. Next, you can adapt the model to your domain by fine-tuning and optimizing it to be smaller and faster at runtime. Finally, the trained models can be exported into open formats for deployment across diverse environments—from edge to cloud—with NVIDIA DeepStream agent skills and tools. These fine-tuning agents skills ensure that high-performing vision AI models can be quickly customized, optimized, and deployed at scale faster than ever.
TAO Documentation
Browse documentation and learn how to get started on TAO.
Key Features
Accelerate Development With Agent Skills and Tools
Seamlessly use TAO 7 fine-tuning agent skills and tools with any coding agent to post-train open models such as NVIDIA Cosmos™ 3 and VisualChangeNet with natural language prompts.
Optimize Model Accuracy With Data Sourcing Skills
Reduce development and training time with TAO agent skills for data efficient fine-tuning. Automatically analyze model accuracy weaknesses with root-cause reasoning to determine the right data strategy, then fill the gap with real or synthetically generated data.
Achieve High Accuracy With Automated Training
Accelerate model fine-tuning and ship faster with automated hyperparameter optimization using the AutoML agent, which achieves the highest accuracy and converges quickly with LLM-generated reasoning.
Reduce Data Preparation Time
With Annotation Skills
Manage, process, and prepare datasets for AI model training with agent skills that streamline the data pipeline process with tools for data ingestion, auto-labeling, and conversion to formats optimized for NVIDIA TAO.
Run Efficiently, Deploy Anywhere
TAO standardizes deployment with NVIDIA DeepStream skills for all supported models on edge or cloud. Use knowledge distillation and quantization to compress large models into efficient, edge-ready versions with minimal accuracy loss.
Models
Explore a collection of vision language and vision foundation models that are compatible with TAO fine-tuning skills.
Reasoning Vision Language Model
Generate reasoning traces and customize reasoning VLMs with SFT and PEFT technique for deeper, domain-specific scene and context understanding.
Multimodal Embedding Models
Use these models as pretrained starting points, making it easy to fine-tune models for domain-specific tasks for search and action embedding.
Grounding and Segmentation Models
Easily combine pretrained vision models with a foundation model for tasks like detection, segmentation, classification, and change detection, streamlining domain-specific customization.
Real-time detection (RT-DETR)
Text-guided object segmentation (MaskGroundingDINO)
Visual change detection (Visual ChangeNet)
Depth Estimation Models
Use mono and stereo depth estimation foundation models to achieve strong zero-shot generalization.
Get Started With TAO
Set Up Your System
Check to see if your machine meets the system requirements and compatibility, then get started by installing TAO.
TAO Github Tutorials and Notebooks
Check out extended resources and Jupyter notebooks for TAO.
Learn MoreStarter Kits
Agentic Fine-Tuning
Seamlessly integrate the agent skills and tools with any AI coding agent to fine-tune open models using natural language prompts.
Fine-Tuning
Take advantage of Supervised Fine-Tuning (SFT) with labeled data and Self-Supervised Learning (SSL) with unlabeled data.
Advanced Fine-Tuning
Take advantage of various fine-tuning methodologies based on your training data strategy, including Supervised Fine-Tuning (SFT) with labeled data and Self-Supervised Learning (SSL) with unlabeled data.
General FAQ
NVIDIA TAO is free to download. Use of this software is governed by the NVIDIA Software License Agreement and Product-Specific Terms for NVIDIA AI Products., which allows training and deploying AI models, including for commercial use.
No. TAO is designed to simplify AI model customization with pre-trained models, automated workflows, and low-code tools. With TAO agentic skills, now your coding agents can use TAO to fine-tune models.
Yes. TAO enables you to fine-tune NVIDIA pre-trained models using your own datasets to create solutions tailored to your specific use case.
TAO can be used across industries including manufacturing, retail, healthcare, transportation, smart cities, and robotics to build customized vision AI applications.
TAO-trained models can be deployed across cloud, data center, edge, and embedded environments using NVIDIA deployment platforms and tools.
More Resources
Ethical AI
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards. Please report security vulnerabilities or NVIDIA AI Concerns here.
Get Started Today.