
Earlier this year in March, we showed retinanet-examples, an open source example of how to accelerate the training and deployment of an object detection pipeline for GPUs. We presented the project at NVIDIA’s GPU Technology Conference in San Jose. This post discusses the motivation for this work, a high-level description of the architecture, and a brief look under-the-hood at the optimizations we employed. If you are new to object detection on GPUs, we encourage you to refer to Real-Time Object Detection on GPUs 10 mins to get started.
Rationale
While several excellent open source projects focused on object detection exist, we felt we needed to create and publish this example for several reasons.
Tradeoff between inference performance and accuracy. Deep learning models for object detection can loosely be grouped into two categories: single stage detectors (e.g. Single-Shot Detector, YOLO, YOLOv2) and two stages detectors (e.g. Faster-RCNN). Two stages detectors first extract region proposals (likely objects) before classifying them whereas one stage detectors achieve dense classification on all background and foreground positions.
Due to the large class imbalance between background and likely objects, single stage detectors have been lagging the state-of-the-art in detection accuracy. However, the increased accuracy of two stage networks comes at a cost of longer latency during inference. Today, the constraints of the target application will determine which type of model is most appropriate. In an ideal case, we would be able to design a model with high accuracy and high inference performance.
Desire for end-to-end GPU processing. A few steps occur in a typical object detection pipeline where the GPU is not used, such as image preprocessing and detection post processing. Accelerating these functions by moving them to the GPU is one potential strategy to increase overall performance for training and inference. This would additionally help to reduce costly data transfers between the CPU and GPU memory, such as moving the full preprocessed input tensor to GPU and passing large feature maps from the GPU back to CPU for bounding box post processing. Both can be bottlenecks during inference.
Putting NVIDIA Deep Learning Libraries together. NVIDIA provides a wide variety of software libraries that each address different portions of the deep learning workflow: DALI for image preprocessing, APEX/AMP for easy mixed-precision training, TensorRT for optimizing trained models for deployment, and DeepStream for creating intelligent video analytics applications. We wanted to create an end-to-end example leveraging each of these libraries together to demonstrate the value of the GPU computing platform that developers can start using out-of-the-box and extend for their own use cases.
Architecture Details
Next, we needed to decide which architecture to leverage for our initial design. This section provides a high level overview of the RetinaNet architecture used in this project, discuss how it is used for object detection, and explore the implications of our design choice on detection accuracy and inference performance.
RetinaNet
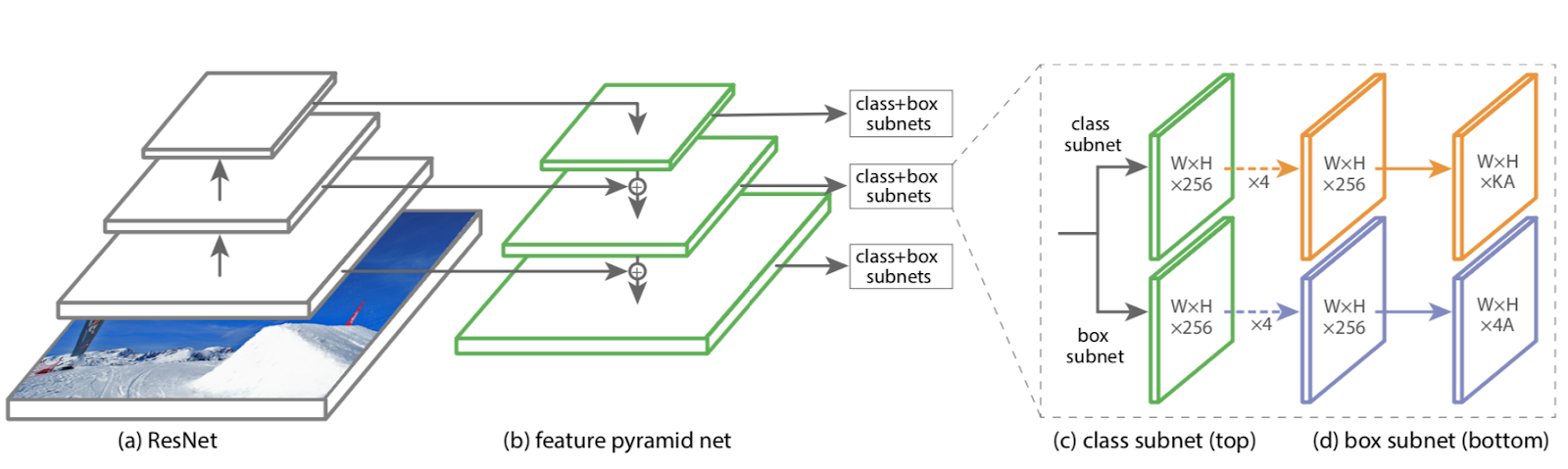
RetinaNet is a single stage object detector proposed by researchers at FAIR in their paper “Focal Loss for Dense Object Detection”. It is based on a relatively simple design, as shown in figure 1, and is composed of:
- Feature extraction backbone. Usually a flavor of ResNet. Used to extract semantic information from the image for subsequent detection.
- Feature pyramid network (FPN). Allows the network to “see” smaller, more detailed objects by up-sampling the top layers — rich in semantic information — and adding details from the previous feature extraction layers. Delivers feature maps of different dimensions in order to detect objects of various sizes.
- Each feature map is fed into two sub-networks. The class subnet classifies each position on the feature map giving a score for each potential object class and background.
- Feature maps also go through the box subnet. Regresses the coordinates of the bounding box around each potential object.
RetinaNet also introduces the concept of Focal Loss, an improved loss function to address the accuracy gap between one stage and two stages detectors. Focal Loss compensates for the background-foreground class imbalance, down weighting the importance of easy examples (like backgrounds) and making hard examples matter more.
Flexibility is an important feature of this type of network. The feature extraction backbone can easily be changed without the need to make any modification to the rest of the network. This allows the user to opt for a specific performance-accuracy tradeoff tailored to the task or application considered. We offer multiple backbones with explicit metrics for easy selection in this implementation.
Post Processing
The bounding boxes we obtain during inference at the output of RetinaNet need to be post processed in order to get the final relevant boxes.
We mentioned earlier that the box subnet regresses the coordinates of the bounding boxes. In practice, each position on the feature maps has a set of predefined anchor boxes of various aspect ratios and scales. The box subnet actually outputs refined coordinates, the delta of the predicted bounding box from each actual anchor box coordinate (dx, dy, dw, dh). Therefore, the first step of the post processing is performing this coordinate conversion from anchor box deltas to refined object bounding box.
After decoding the bounding box coordinates, multiple predicted bounding boxes from different anchors often cluster around the same object. This creates the need for a second post processing step, called non maximal suppression. This computation compares similar predicted bounding boxes and ensures only the most relevant bounding box with the highest score for each object is selected for the final output detections.
Both of these post processing steps can be parallelized and run on the GPU along with the rest of the detection model, significantly improving performance.
Performance Overview
After developing the first implementation, we analyzed the inference performance of our object detection pipeline to see if we achieved our desired goals. We gathered preliminary end-to-end inference latency measurements for batch size 1 (including pre and post processing) for a few of our RetinaNet models, collected on a local system with a NVIDIA T4 GPU.
Each model performs inference on images from the COCO 2017 validation dataset that are resized and padded to a fixed input size of 1280×1280 pixels using DALI. We use TensorRT to optimize our RetinaNet models from PyTorch for deployment in INT8 precision on T4.
Running our models on T4 using TensorRT INT8 precision enables its Tensor Core microarchitecture for increased throughput and lower latency while still maintaining strong detection accuracy. The final end to end inference performance we obtain after applying these optimizations depends on the chosen backbone, with latencies between 18ms per image at 0.31 mAP and 33ms for 0.39 mAP. These results demonstrate that we can design highly accurate object detection models and still be able to deploy them on GPU with low inference latency.
Under the hood
Now let’s take a look under the hood at the tools we employed and how they helped us optimize the object detection pipeline.
Basic overview of using RetinaNet CLI
The code for this project is open source and available on the NVIDIA GitHub page. We provide an installable command line module that allows users to quickly train, test (infer) and export object detection models. This makes it easy for you to experiment with the project yourself.
Training a RetinaNet model is as simple as specifying the backbone architecture (in this case, a ResNet50 based FPN) and datasets to use for training/evaluation:
retinanet train retinanet_rn50fpn.pth --backbone ResNet50FPN \
--images /coco/images/train2017/ --annotations /coco/annotations/instances_train2017.json \
--val-images /coco/images/val2017/ --val-annotations /coco/annotations/instances_val2017.json
The retinanet train command can also be used to finetune an existing model for another dataset. The --fine-tune retinanet_rn50fpn.pth argument will load the pretrained model, strip off the last layers of the existing cls_heads that were used to predict classes from the original dataset, and attach new ones tailored to the new finetuning dataset:
retinanet train model_mydataset.pth \
--fine-tune retinanet_rn50fpn.pth \
--classes 20 --iters 10000 --val-iters 1000 --lr 0.0005 \
--resize 512 --jitter 480 640 --images /voc/JPEGImages/ \
--annotations /voc/pascal_train2012.json --val-annotations /voc/pascal_val2012.json
Once a model is trained, its accuracy can be evaluated with the retinanet infer command:
retinanet infer retinanet_rn50fpn.pth --images /coco/images/val2017/ --annotations /coco/annotations/instances_val2017.json
The retinanet export command abstracts away the complexity of converting a PyTorch RetinaNet model into a TensorRT engine and replaces it with a single invocation:
retinanet export model.pth engine.plan
By default, retinanet export will generate TensorRT engines targeting FP16 precision. However, users can take advantage of TensorRT’s INT8 calibration algorithm to produce a higher performance INT8 engine by specifying a path to calibration images:
retinanet export model.pth engine.plan --int8 --calibration-images /coco/images/val2017/
You can also use retinanet infer to evaluate your TensorRT engine:
retinanet infer engine.plan --images /coco/images/val2017/ --annotations /coco/annotations/instances_val2017.json
DALI
NVIDIA’s open source DALI project focuses on accelerating the preprocessing pipeline for deep learning applications. DALI provides a set of highly optimized building blocks that can run on CPU or GPU for commonly used preprocessing functions. It supports a wide variety of data formats and can easily be integrated with popular deep learning frameworks, allowing the preprocessing pipeline to be portable across workloads.
You first need to identify the set of operators that are needed for your training/inference prepprocessing pipeline to use DALI. You define the graph using these operators to describe how your data is transformed into fully preprocessed tensors that are ready for use by your model.
The defined graph in our use case has a separate path for training and inference preprocessing. The inference graph is fairly straightforward: JPEG images are read from disk along with the corresponding detection bounding boxes and their classes. They are then transferred to the GPU where they get decoded, resized, normalized, and padded to the appropriate size.
The training graph uses a slightly more complicated set of operations. First, we take a random prospective crop of the bounding boxes in an image, discarding any detections not part of the cropped area. We use the GPU to partially decode only the relevant portion of the image that is included in the random crop. The decoded image is then randomly resized according to a training hyperparameter, randomly flipped horizontally, and finally normalized and padded.
def define_graph(self):
images, bboxes, labels, img_ids = self.reader()
if self.training:
crop_begin, crop_size, bboxes, labels = self.bbox_crop(bboxes, labels)
images = self.decode_train(images, crop_begin, crop_size)
resize = self.rand4()
images, attrs = self.resize_train(images, resize_longer=resize)
flip = self.coin_flip()
bboxes = self.bbox_flip(bboxes, horizontal=flip)
images = self.img_flip(images, horizontal=flip)
else:
images = self.decode_infer(images)
images, attrs = self.resize_infer(images)
resized_images = images
images = self.normalize(self.pad(images))
return images, bboxes, labels, img_ids, attrs, resized_images
Now that we have defined a DALI preprocessing pipeline, we wrap it with an iterator used for training and inference. This iterator is responsible for taking the tensor outputs from the DALI pipeline, performing any final transformations (like re-scaling the bounding boxes to match the resized image), and converting them into PyTorch tensors for use in training or inference. This design also allows us to make the DALI dataloader interchangeable with our native PyTorch data loader for easier experimentation.
We compared the overall inference time for a ResNet18FPN backbone RetinaNet model optimized for TensorRT INT8 precision using both data loaders on the Tesla T4. We notice that using DALI with TensorRT inference allows us to achieve better performance by reducing the data loading overhead as compared to the native PyTorch dataloader. This difference is modest for batch 1 but becomes substantial for larger batch sizes where there is more preprocessing work to be done before inference.
Automatic Mixed Precision on Tensor Cores
Using mixed precision for deep learning training is an effective way to maximize performance on Volta and Turing GPUs with Tensor Cores. At GTC SJ 2019, we announced an update to the automatic mixed precision capabilities (AMP) inside of PyTorch from NVIDIA’s APEX library. We have integrated these tools into our project to make mixed precision training of RetinaNet models simple to use. Migrating an existing FP32 precision training script to experiment with AMP’s mixed precision training functionality is straightforward and requires only two small code changes.
The first required change in using AMP is to register your model and optimizer with a given opt_level, ranging from O0 (regular FP32 training) to O3 (pure FP16 training). These opt_levels correspond to a set of predefined parameters that define what behind-the-scenes changes AMP will automatically apply to your model and optimizer. We used an opt_level of O2 for mixed precision training in our implementation. This opt_level casts all inputs to be FP16 by default, casts our model weights to FP16, keeps batch normalization operations in FP32, and maintains a master copy of model weights in FP32 that the optimizer will update during optimizer.step(). We override the loss_scale parameter of this opt_level by specifying a static loss scale value of 128 instead of dynamic loss scaling.
model, optimizer = amp.initialize(model, optimizer,
opt_level = 'O2' if mixed_precision else 'O0',
keep_batchnorm_fp32 = True,
loss_scale = 128.0,
verbosity = is_master)
The second change to the training script involves the backward pass. When training in FP32 using PyTorch, one generally calls my_loss.backward() to calculate the gradients to be used for the optimization step. However, we need to scale the loss value during mixed precision training before calculating gradients to avoid any potential numerical issues. To that end, we use the amp.scale_loss function to automatically perform the loss scaling and then call .backward() on the new scaled_loss. Since we have already registered our optimizer object with AMP, we still use the same optimizer.step() to update our model weights.
with amp.scale_loss(cls_loss + box_loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
TensorRT
TensorRT is NVIDIA’s platform for high-performance deep learning inference. It provides both an optimizer component to tune deep learning models for deployment on GPU as well as a runtime to run inference in production. In order to optimize our RetinaNet models for deployment with TensorRT, we first export the core PyTorch RetinaNet model (excluding the bounding box decode and NMS postprocessing portions of the model) to ONNX, a framework-agnostic intermediate representation of deep learning models. Next, we use the ONNX parser provided with TensorRT to convert the structure and weights from the ONNX model representation into a TensorRT optimizable representation called a INetworkDefinition object.
For best performance, we would like to include the bounding box decode and NMS steps of the inference pipeline as a part of the single TensorRT INetworkDefinition object. However, these two functions are not easily represented in ONNX and imported into TensorRT like the rest of the network. In order to make this work, we leveraged TensorRT’s plugin layer API to define our own custom layers for bounding box decode and NMS. After writing the optimized CUDA kernels to run these functions on GPU, we use those kernels to define a TensorRT IPluginV2 object. This IPluginV2 object contains all of the information that TensorRT needs to integrate our custom functions into the rest of the INetworkDefinition as if it was a native TensorRT layer type.
class DecodePlugin : public IPluginV2 {
void configureWithFormat(const Dims* inputDims, …) override;
int enqueue(int batchSize, const void *const *inputs, …) override;
void serialize(void *buffer, …) const override;
…
}
class DecodePluginCreator : public IPluginCreator {
IPluginV2 *createPlugin (const char *name, …) override;
IPluginV2 *deserializePlugin (const char *name, …) override;
…
}
REGISTER_TENSORRT_PLUGIN(DecodePluginCreator);
We connect a DecodePlugin to the outputs of each of the class/bbox head pairs from each level of the FPN and combine all of the DecodePlugin outputs together into a final NMSPlugin that selects the top detections from the input image.
// Parse ONNX FCN
auto parser = createParser(*network, gLogger);
parser->parse(onnx_model, onnx_size);
…
// Add decode plugins
for (int i = 0; i < nbBoxOutputs; i++) {
auto decodePlugin = DecodePlugin(score_thresh, top_n, anchors[i], scale);
auto layer = network->addPluginV2(inputs.data(), inputs.size(), decodePlugin);
}
…
// Add NMS plugin
auto nmsPlugin = NMSPlugin(nms_thresh, detections_per_im);
auto layer = network->addPluginV2(concat.data(), concat.size(), nmsPlugin);
// Build CUDA inference engine
auto engine = builder->buildCudaEngine(*network);
At this point, we have successfully imported the entire PyTorch RetinaNet model into TensorRT. The next step in the TensorRT development workflow is to optimize our INetworkDefinition for deployment. Using a single API call, TensorRT applies its suite of inference optimizations onto our network and produces a TensorRT IEngine object. This object contains the fully optimized representation of the model that can be saved to a file and later reloaded to execute inference of our model on GPU.
// Build engine
cout << "Applying optimizations and building TRT CUDA engine..." << endl;
_engine = builder->buildCudaEngine(*network);
…
cout << "Writing to " << path << "..." << endl;
auto serialized = _engine->serialize();
ofstream file(path, ios::out | ios::binary);
file.write(reinterpret_cast(serialized->data()), serialized->size());
We specify that our optimized TensorRT engine should use FP16 precision by default. We do this to take advantage of the Tensor Core microarchitecture in Volta and Turing GPUs for better inference performance. We also provide the workflow to enable INT8 precision for our models for even higher performance.
Unlike FP32 and FP16 precision, using INT8 precision with TensorRT requires an extra step. We need to provide a calibration dataset for use during the optimization process to determine the appropriate scaling factors between FP32 and INT8 precision for each layer in the network to minimize loss in inference accuracy. We determined from our experiments with these RetinaNet models and the COCO17 dataset that we can calibrate our models for INT8 precision with minimal loss in accuracy.
if (int8) {
builder->setInt8Mode(int8);
ImageStream stream(batch, inputDims, calibration_images);
Int8EntropyCalibrator* calib = new Int8EntropyCalibrator(stream, model_name, calibration_table);
builder->setInt8Calibrator(calib);
}
Conclusion
We demonstrated an example of how to create an object detection pipeline for GPUs and introduced the NVIDIA libraries used to optimize the end-to-end workflow. We believe this work can serve as an outline for developers looking to efficiently create and deploy object detection models on GPUs and as a detailed example of how to unify elements of the NVIDIA deep learning software stack into a single workflow. We will continue to develop this project, including integration of our models into NVIDIA DeepStream applications. Be sure to check out our repository for future updates. Check back for follow-up posts on our continued work.