Imagine every parent’s worst nightmare: a child lost in a crowded mall. Now imagine a scenario where that child is located and rescued in a matter of minutes using a network of cameras deployed within the building—and all the video is recorded, retrieved and analyzed in real time. This represents just one of many possibilities offered by the field of video analytics.

While traditional video analytics uses computer vision-based approaches, next-generation solutions increasingly rely on deep learning techniques. Running these techniques on GPUs offers unprecedented accuracy, functionality and speed. The key to realizing the potential of video analytics is building applications that scale in a cost-effective manner.
NVIDIA’s new DeepStream SDK helps developers quickly build efficient, high-performance video analytics applications by using the hardware features of NVIDIA Tesla GPUs, including superior decode performance, high-speed inference through reduced precision, and low power consumption. In this blog post I’ll provide an overview of the DeepStream SDK, illustrate its use for meeting performance and scalability requirements, and highlight its ease of deployment based on an object detection sample use case.
Why DeepStream?
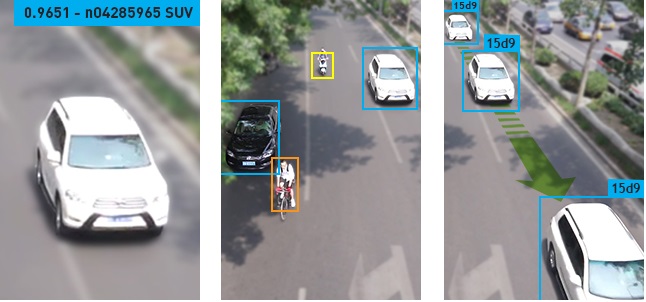
At its core, video analytics draws from standard computer vision tasks including image classification, object detection, recognition and tracking. Figure 1 shows the application of each of these tasks to images.
There has been a proliferation of networks that address these tasks effectively, often using convolutional neural networks. Successive frames of data are typically run through these networks to generate results of interest. High-performance applications are built on pipelines that optimally feed neural networks with decoded video frames in the required resolution and format to maximize throughput. Scalability requires multiple video streams to be processed in parallel to derive superior channel density (the number of channels of video processed in a given (rack) space). Using deep learning for video analytics is computationally expensive, and the requirements are even more stringent for live video since it often involves real-time analysis using custom logic and flexible workflows.
DeepStream’s key value is in making deep learning for video easily accessible, to allow you to concentrate on quickly building and customizing efficient and scalable video analytics applications. DeepStream is part of the NVIDIA Metropolis platform, which provides a uniform architecture for building intelligent edge-to-cloud video analytics systems.
DeepStream Video Analytics Workflow
Figure 2 shows a typical application pipeline using DeepStream. The stages provided by the SDK are shown in green and distinguished from those implemented by the user, which are shown in blue. The user is only responsible for parsing and injecting the video into the pipeline, providing a deep learning network and consuming the inference results coming out of the pipeline.
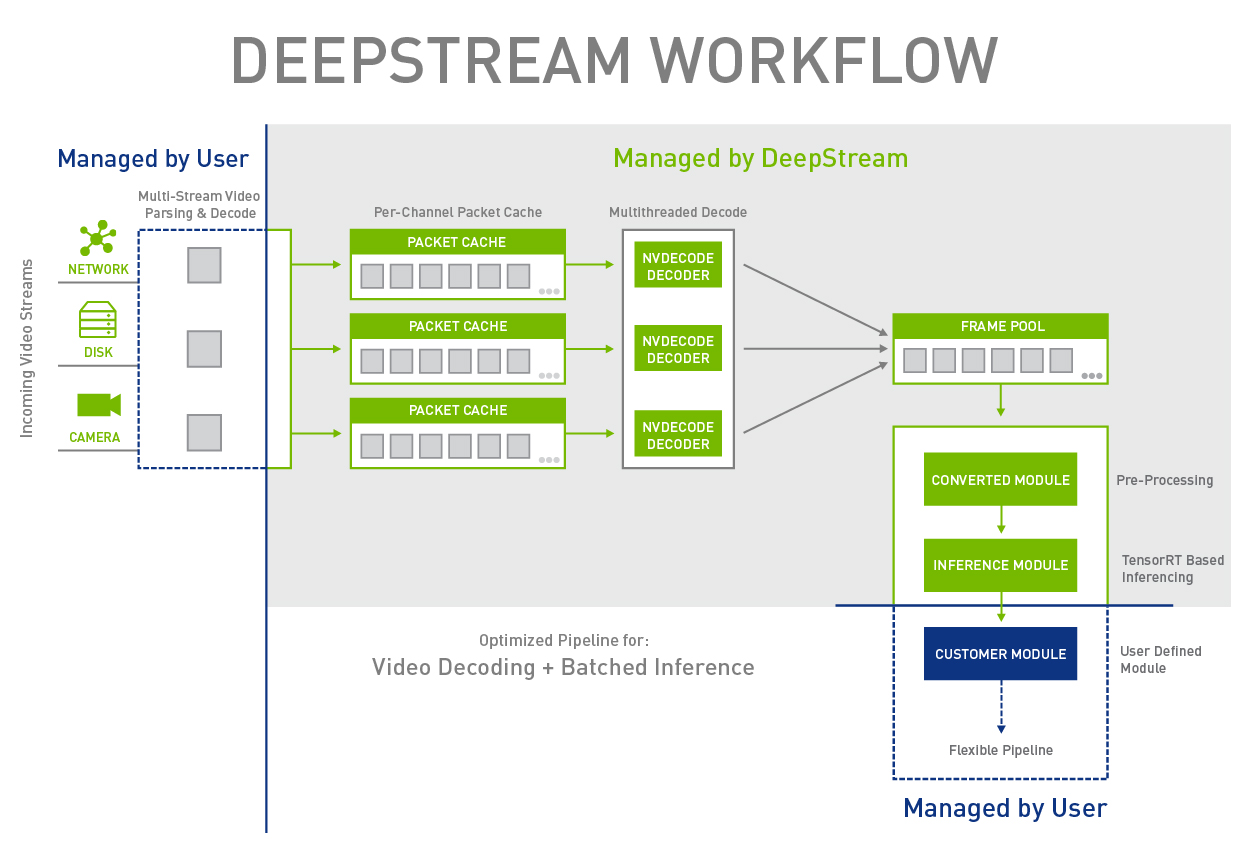
The DeepStream SDK provides modules that encompass decode, pre-processing and inference of input video streams, all finely tuned to provide maximum frame throughput. The decode module accepts video encoded in H.264, H.265, and MPEG-4 among other formats and decodes them to render raw frames in NV12 color format. Video decoding uses the hardware-accelerated NVIDIA Video Codec SDK.
The pre-processing stage converts the color format from NV12 to BGR, and also resizes the frames to the resolution required by the neural network being used. Color space conversion and scaling uses a combination of custom CUDA kernels and NVIDIA Performance Primitives (NPP) library functions.
The inference module processes the frames in batches using a neural network imported and executed using TensorRT, which optimizes them for high throughput and low latency with best-in-class power efficiency. DeepStream currently supports Caffe-based networks; TensorFlow support will be added in the near future.
The modules are tightly integrated to ensure judicious use of data transfers and software synchronization, while extracting maximum hardware concurrency.
DeepStream User API
DeepStream provides a C++ API, at the core of which are three entities: modules that serve as individual building blocks of the pipeline, the device worker that encapsulates the whole pipeline itself, and tensors to communicate between modules. Modules represent stages in the pipeline, and can be categorized as either pre-defined (decoder, pre-processing, and inference) or user-defined modules that add custom logic.
To build a pipeline, you create an instance of the device worker by calling createDeviceWorker():
// Create a deviceWorker on a GPU device, the user needs to set the channel number. IDeviceWorker *pDeviceWorker = createDeviceWorker(g_nChannels, g_devID);
Then you enable and configure the pre-defined stages of the pipeline by defining the input codec type for decoding, the color format to be output by the pre-processing stages, and the network details for the inference model.
// Add decode task, the parameter is the format of codec. pDeviceWorker->addDecodeTask(cudaVideoCodec_H264);
// Add post processing task and define color format for inference
pDeviceWorker->addColorSpaceConvertorTask(BGR_PLANAR);
// Enable inference module and define model details
pDeviceWorker->addInferenceTask(preModule_infer, deployFile, modelFile, meanFile,
inputLayerName, outputLayerNames);
The application is now ready to run.
//finally, start the pipeline! pDeviceWorker->start();
Custom Pipelines
You can extend this model by adding user-defined modules to the pipeline. Creating a module involves defining its inputs, execution routine and output tensor(s). You can extend and configure pipelines by connecting output tensors to appropriate inputs in subsequent modules. Tensors have shape and data type attributes, as well as a “memory type” of either CPU or GPU that allows data associated with them to be handled and copied appropriately. The data type of an input tensor must match the type expected by a module.
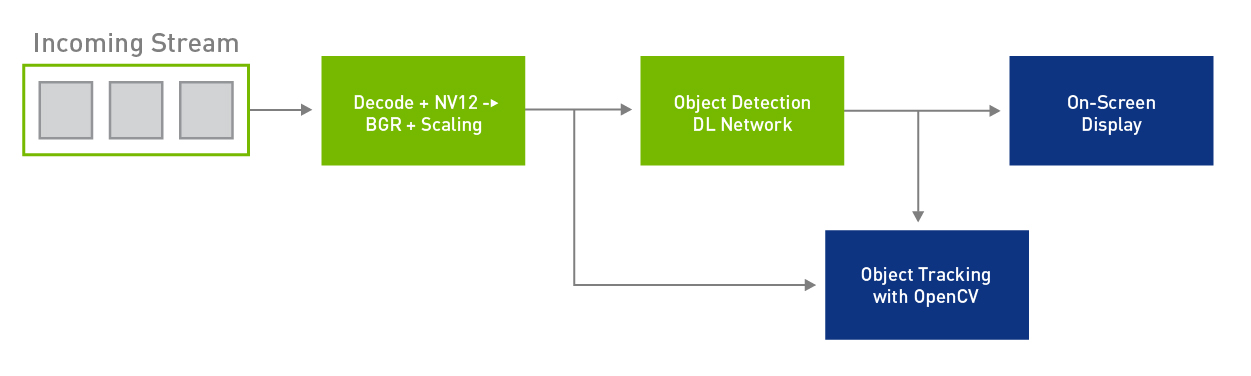
Custom modules enable more sophisticated multi-stage analysis through the insertion of hand-written kernels, OpenCV algorithms, and more into the pipeline to complement the deep neural networks. The example in Figure 3 illustrates integration of OpenCV-based object tracking algorithms into DeepStream pipelines. The inference module outputs tensors containing bounding boxes into the object tracking module that then tracks the detected objects in subsequent frames. The tracking and bounding box information are rendered together on the on-screen display for visualization.
Built for Tesla P4/P40
While DeepStream can be run on any recent GPU with compute capability supporting the associated CUDA and TensorRT versions, it has been designed to leverage the exceptional inference and video capabilities of Tesla P4 and P40 GPUs based on the Pascal family. In combination with high floating point throughput and efficiency, these GPUs support the very latest (H265) encoding formats, and can simultaneously decode 30+ channels of HD video. This enables software to feed deep neural networks executed on these GPUs with frames to run inference at an unprecedented rate. The DeepStream software architecture leverages this hardware decode capability via a multi-threaded implementation of the decode module in combination with a per-channel packet cache to feed the NVDECODE API. This results in maximum hardware decoder (NVDEC) utilization and decode performance.
The increased decode throughput enables larger inference batch sizes, resulting in increased inference throughput. An even bigger opportunity to increase system throughput is provided by GPU support for 8-bit integer (INT8) operations. TensorRT 2.1 introduced the ability to convert single-precision floating-point (FP32) deep learning networks (CNNs) to use INT8 precision without requiring any tuning or retraining. By using calibration techniques, there is no significant accuracy loss during inference in spite of the reduced range and accuracy of INT8. DeepStream provides calibration tables and an API to enable or disable INT8 at run time. This allows TensorRT to convert between FP32 and INT8 precision in an optimal manner while executing the network.
Tesla P4 is a compact-form-factor accelerator board with maximum power usage of 75W, designed for high-density data center deployment with multiple cards per server. Based on this requirement, DeepStream enables the execution of multiple pipelines, each on a different GPU, to enable superior channel density. You can pass the ID of the GPU for the pipeline via the deviceID parameter to createDeviceWorker().
IDeviceWorker *createDeviceWorker(const int nChannels, const int deviceId);
The intent is for higher-layer software to create and manage the various pipelines based on considerations such as use case, utilization, and quality of service, and to schedule video streams on appropriate GPUs.
Object Detection Sample
The DeepStream release contains an object detection sample named nvDecInfer_detection based on an unpruned Resnet-18 network. The sample highlights all aspects of DeepStream usage including pipeline creation and configuration, H264 stream parsing and injection, the addition of custom modules, and consumption of inference results. Much of this code is reusable and can be readily applied to user projects.
Sample Pipeline
Figure 4 shows the end-to-end pipeline of the object detection sample.
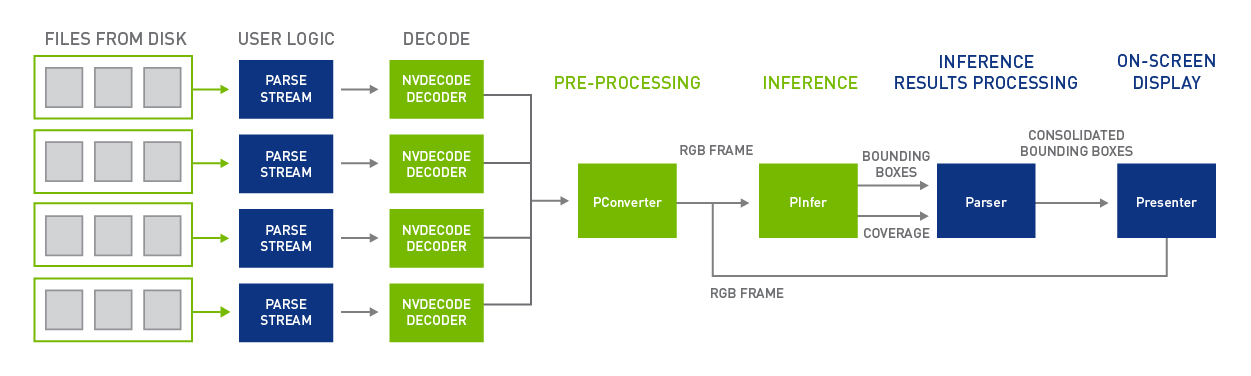
As before, blocks provided by the SDK are in green and user provided logic is in blue. To complement the multi-threaded implementation of the decode module within DeepStream, user logic in the sample uses separate threads to inject packets into corresponding channel inputs in the pipeline, the following code shows.
//per thread injection of packets into pipeline pDeviceWorker->pushPacket(pBuf, nBuf, laneID);
While the sample uses file-based video inputs, the concept can similarly be extended for other cases such as camera feed or network streaming. The Resnet-18 network used by the inference module outputs two tensors containing bounding box and coverage information for various classes of objects detected in each frame. These results are aggregated by a parser module that outputs consolidated bounding box information by filtering based on coverage thresholds and clustering the remaining bounding boxes. These are rendered by the presenter module onto the original frame and shown on a display.
Profiling
DeepStream provides profilers to help you measure frame throughput through the decode and inference modules. The decode throughput is reported per channel, whereas the inference throughput provides the combined throughput since all channels coalesce into a shared buffer from which analysis is run. The listing below shows results from decode profiling:
[DEBUG][11:51:33] Video [0]: Decode Performance: 718.89 frames/second || Decoded Frames: 500 [DEBUG][11:51:33] Video [1]: Decode Performance: 711.68 frames/second || Decoded Frames: 500 [DEBUG][11:51:33] Video [0]: Decode Performance: 762.77 frames/second || Decoded Frames: 1000 [DEBUG][11:51:33] Video [1]: Decode Performance: 748.20 frames/second || Decoded Frames: 1000
You can determine the total decode throughput by adding the throughput for each channel.
The rate at which the profiler reports results is configurable based on definitions in the DecodeProfiler class, which implements the logic for processing profiling results.
On-Screen Display
With video analytics, it’s often desirable to view the results of the analysis overlaid on the video. The object detection sample illustrates implementation of this functionality as a custom module that accepts two input tensors delivering the decoded frame output by the pre-processing module and the coordinates of the detected bounding box from the inference module. The sample uses the OpenGL glut library to render bounding boxes, which requires an underlying window system and display. Because Tesla GPUs cannot directly drive a display, the sample can use a separate graphics card (e.g. a GeForce or Quadro GPU board) for display. The sample therefore illustrates how to extend the DeepStream video pipeline to a second GPU. Figure 5 shows the sample’s object detection results with bounding boxes.

Performance
As with most GPU-based workloads, the performance of video analytics applications is affected by available memory size and bandwidth (device memory bandwidth as well as PCIe bandwidth for host-to-device memory transfers), the number of GPU cores and the GPU clock frequency. These factors determine the block-level throughput for each of the stages in the video pipeline. It’s common for DeepStream-based applications to be either decode-bound or inference- (compute-) bound, depending on the complexity of the deep learning network being used. Using tools such as nvidia-smi to identify which of the hardware decoders (NVDECs) or the GPU cores are close to 100% utilization (if any) can provide a quick hint on which of the stages is the bottleneck.
The object detection example is inference bound when executed on a P4-based system, exhibiting full GPU utilization when the channel count reaches 16 while processing 30 fps HD videos, as the following nvidia-smi output shows. Any further increase in channel count causes the throughput to fall below the video frame rate, making real-time processing infeasible.
$ nvidia-smi -i 0 -q -d UTILIZATION
GPU 0000:05:00.0
Utilization
Gpu : 96 %
Memory : 41 %
Encoder : 0 %
Decoder : 56 %
Changing to an equivalent (but smaller) Resnet-10 network enables processing of up to 30 channels at 30 fps. The following nvidia-smi output shows the decoder utilization reaching 100% at that point, indicating that the application is decode bound.
$ nvidia-smi -i 0 -q -d UTILIZATION
GPU 0000:05:00.0
Utilization
Gpu : 76 %
Memory : 56 %
Encoder : 0 %
Decoder : 100 %
Applications that use larger networks are inference bound at relatively lower channel counts, due to the higher computational cost. The best practice involves making the optimum tradeoff in terms of network functionality and performance, pruning the network sufficiently, and using INT8 inference to achieve maximum channel count and extract all available performance from the GPUs.
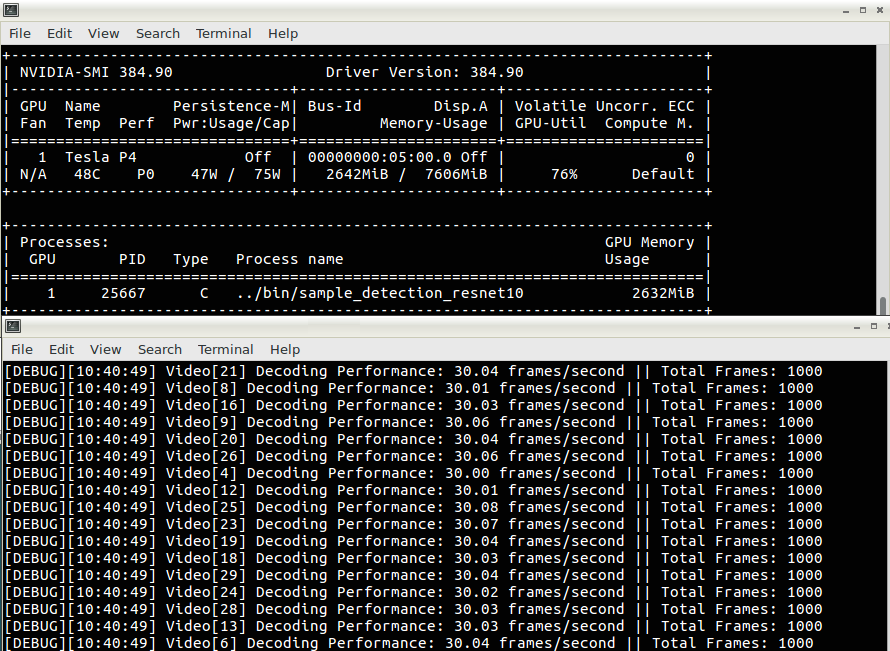
By striking this balance, you can support exciting new use cases at unprecedented scale and power. Figure 7 shows the decode profiler output for the Resnet-10-based detection application, which lists the throughput for all 30 channels matching the input frame rate of 30fps. Figure 7 also shows nvidia-smi output demonstrating that the Tesla P4 GPU consumes only 47 W during execution of the workload, which is only 1.56 W/channel. This provides opportunities to achieve exceptional channel densities within acceptable power budgets when deployed within server farms.
Try DeepStream Today!
Tesla GPUs unleash a world of opportunities for deep-learning-powered video analytics applications, and the NVIDIA DeepStream SDK makes them easier to build. DeepStream enables you to leverage cutting-edge concepts in deep learning. You can build on the ideas described in this blog to implement capabilities such as cascading networks and real-time object trackers. The DeepStream team is excited to see the innovations that will be realized using the SDK. Download the DeepStream SDK today.
We welcome your questions and comments in the DeepStream developer forum. We aim to continue extending and evolving DeepStream based on your feedback, so let us know what’s on your mind. It’s never been easier to unearth everything your videos have to tell you!