
Detecting the presence of humans accurately is critical to a variety of applications, ranging from medical monitoring in nursing homes to large-scale video analytics in various environments. High performance for deep learning training makes it possible to create robust and generalizable models for objects, humans, animals, and machines. Maintaining real-time inference performance in production environments while preserving high accuracy is critical whether in the data center or the edge. Every percent increase in accuracy during inference when dealing with large numbers of objects and across varied environments leads to exponential gains for organizations providing video-based services. This project focused on increasing the accuracy of human detection and maximizing throughput for real-time inference applications. In this article, we describe our approach using NVIDIA’s TensorRT to scale-up object detection inference using INT8 on GPUs.
Previous research in converting convolutional neural networks (CNNs) from 32-bit floating-point arithmetic (FP32) to 8-bit integer (INT8) for classification tasks is well understood. However, no solid work exists regarding accelerating CNN-based object detection task using INT8. We start with YOLO-v2 [Redmon et al. 2017] as the reference model, which is the state-of-the-art CNN-based object detector and accelerate it with TensorRT for INT8 precision. The reference network was updated to increase accuracy for human detection and improve acceleration throughput with TensorRT, and we name our network SIDNet (SKT Intrusion Detection Network) [An et al. 2018]. SIDNet runs 6x faster on an NVIDIA Tesla V100 using INT8 than the original YOLO-v2, confirmed by verifying SIDNet on several benchmark object detection and intrusion detection data sets. This 6x increase in performance came at the expense of reducing accuracy by only 1% compared with FP32 mode, as figure 1 shows. Let’s look at the approach in more detail.

SKT Intrusion Detection Network
Since our objective is to improve accuracy for human detection, 137,000 images with 0.7 million labeled human bounding box were collected manually for training SIDNet.
Let’s look at three modification which improves accuracy and maximize the throughput of inference engine with TensorRT.
- Careful data augmentation is necessary for improving the precision of your human detector since YOLO-v2 is a general object detector there is some false positives happens in the background of the video environment. Add more real video images for the negative dataset of the human detector will reduce the false positives of humans.
- To improve recall of SIDNet specifically for small human detection in long distance views, we redesign the anchor box part: only three anchor boxes are used and we also fine-tuned the anchor box size and aspect ratio. For the most common environment for intrusion detection is slanted-view with human walking through, standing, sitting, and crawling. With three carefully fine-tuned anchor boxes, the recall of SIDNet is increased in our evaluation dataset compare to YOLO-v2.
- We also modified network architecture for better acceleration with TensorRT, such as replacing all activation functions of SIDNet from Leaky-RELU (rectified linear unit) to RELU. To improve the accuracy of human detection

Accelerate SIDNet in FP32 mode with TensorRT
NVIDIA built TensorRT as a high-performance, deep learning inference engine to improve the scalability of deep learning applications. TensorRT achieves maximum inference throughput by generating an optimal runtime engine. We parse model parameters from DarkCaffe into a TensorRT runtime engine using TensorRT’s built-in NvCaffeParser capability.
TensorRT did a few interesting things to optimize the model, let’s look through them one at a time. SIDNet originally included 96 layers but TensorRT compresses it to only 30 layers to maximize throughput. More specifically, TensorRT merges convolutional layer, batch normalization layer, scaling layer, and RELU into just one layer. The other thing that TensorRT did was to use GPU memory more effectively to eliminate unnecessary memory copy. As an example, it removed the concat layer in the resulting runtime engine.

With these changes, SIDNet in FP32 mode is more than 2x times faster using TensorRT as compared to running it in DarkCaffe (a custom version of Caffe developed by SK Telecom and implemented for SIDNet and Darknet). SIDNet includes several layers unsupported by TensorRT. We replaced the activation function in RELU with the one from leaky-RELU. A 1% drop in accuracy usually occurs when using RELU versus leaky-RLU with the same number of epochs for training, shown in figure 4.
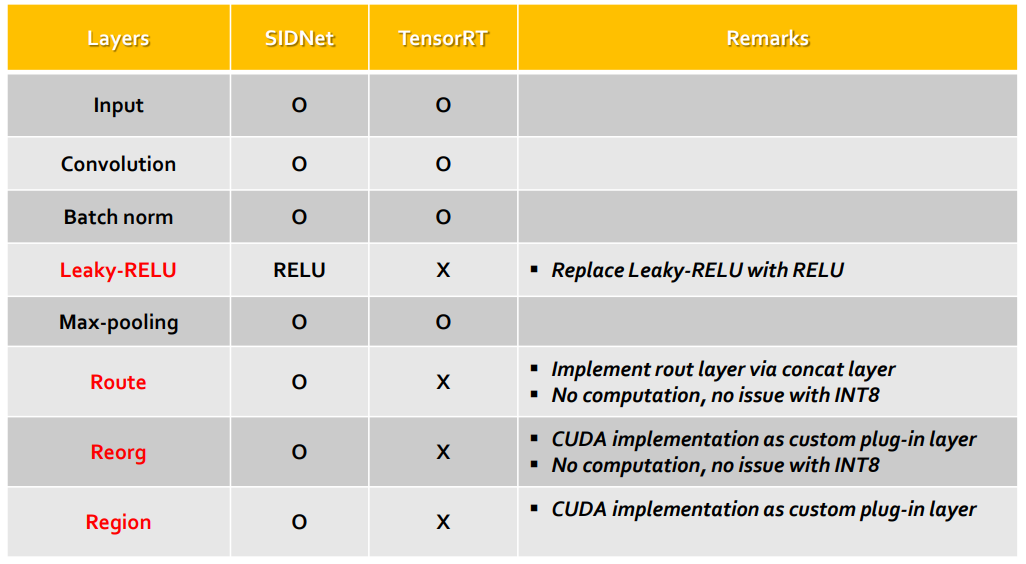
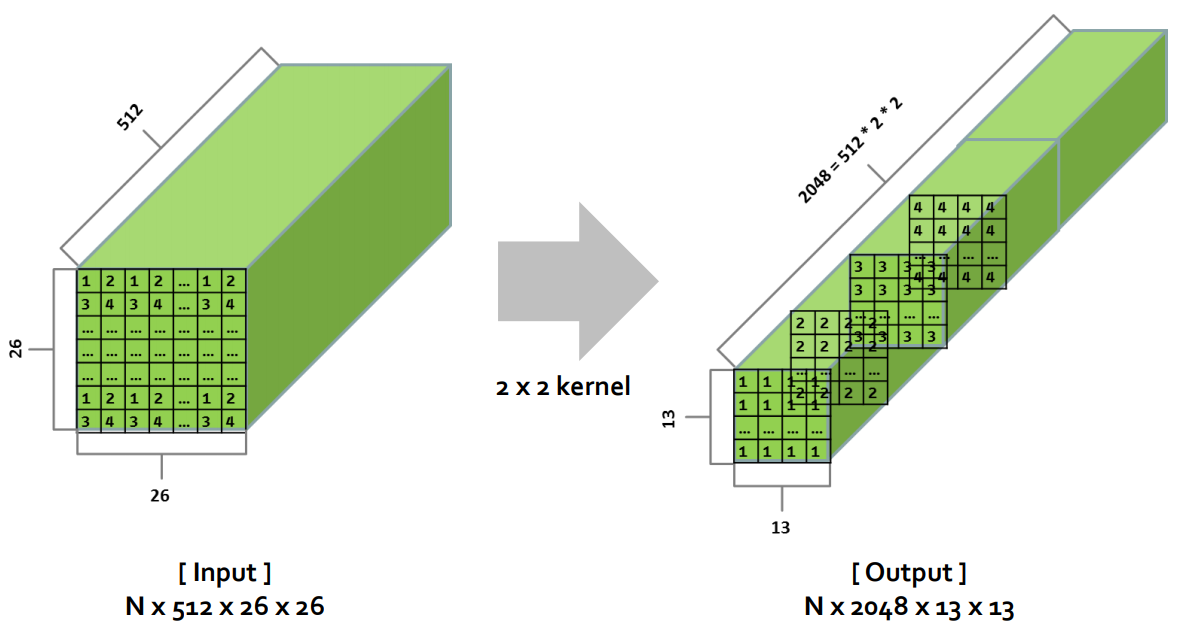
Route layer is equivalent with concat layer, so we implement it as the TensorRT-supported concat layer. Reorg layer encodes more detail information from a higher resolution to generate feature maps. We implement reorg layer as a TensorRT custom plug-in layer, shown in figure 5.
The computationally light region is the last layer, so we implement it with pure CUDA code. We have five anchor boxes with each having x, y, h, w, confidence and two classes, one for human class and the other for background, as diagrammed in figure 6.

Accelerate SIDNet in INT8 mode with TensorRT
Further accelerating this deep neural network inference engine using INT8 via TensorRT requires one more step: calibration. TensorRT provides an offline calibration step to minimize accuracy drop when we move to INT8 from FP32. During calibration, TensorRT finds an optimal dynamic range for each layer possible with 8-bit representation and generates a calibration table for the network. Model parameters need to be trained in FP32 precision along with paired calibration table to convert the network for deployment with INT8 precision. Please refer to Szymon Migacz’s 2017 GTC presentation for more details about using INT8 inference with TensorRT.
We needed to carefully select the calibration dataset to achieve minimal accuracy loss. The ideal calibration dataset should have a very similar distribution with real-world data streaming from deep learning based services, such as intrusion detection. We randomly chose 8,000 images from our dataset and generated 1,000 batches with eight images per batch. The calibration process incorporates 1000 batches offline using the same computational flow as the inference engine to generate the calibration table. TensorRT provides both C++ and Python APIs for calibration.
Experimental Results
We used two challenging dataset for evaluation. The Korean Internet and Security Agency provides its KISA dataset only by request for certification of “Intelligent CCTV Solution”. We built the T view dataset in-house for various CCTV environments, mainly targeting intrusion detection. Both datasets include 10,000 images each. Figure 7 shows sample images from both KISA and T view dataset.

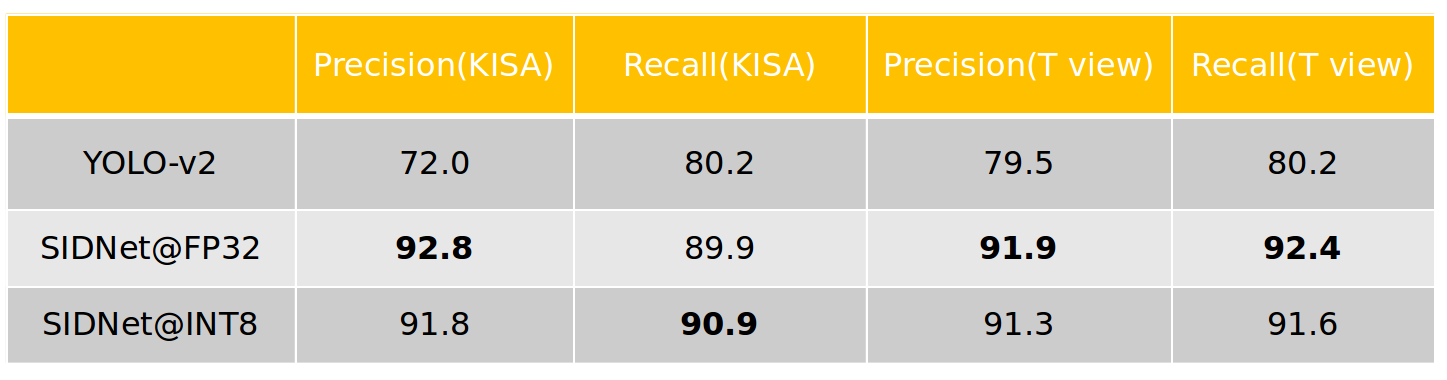
We evaluated the useful behavior of SIDNet compared to YOLO-v2 in terms of both accuracy and performance. Figure 8 shows SIDNet running in either FP32 and INT8 mode generate more accurate human detection results for KISA and T view dataset than the baseline model YOLO-v2. Accuracy drops only about 1% in INT8 mode compared to FP32. We set the detection threshold to 0.3 for all experiments.
We also measured the inference time but excluded two modules in the interest of fairness: image buffer transfer time from CPU to GPU, which depends on system hardware and non-maximum suppression (NMS), which is unnecessary in our intrusion detection system. While YOLO-v2 runs at 100 frames per seconds (fps), SIDNet with INT8 pushes 625 fps, 6x times faster, as shown in Figure 9.
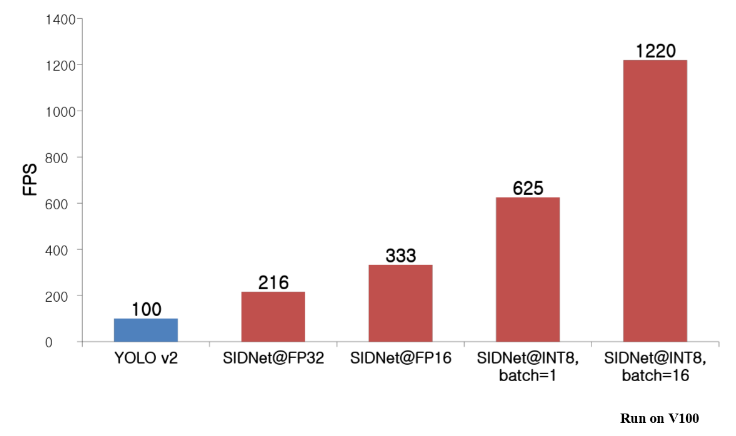
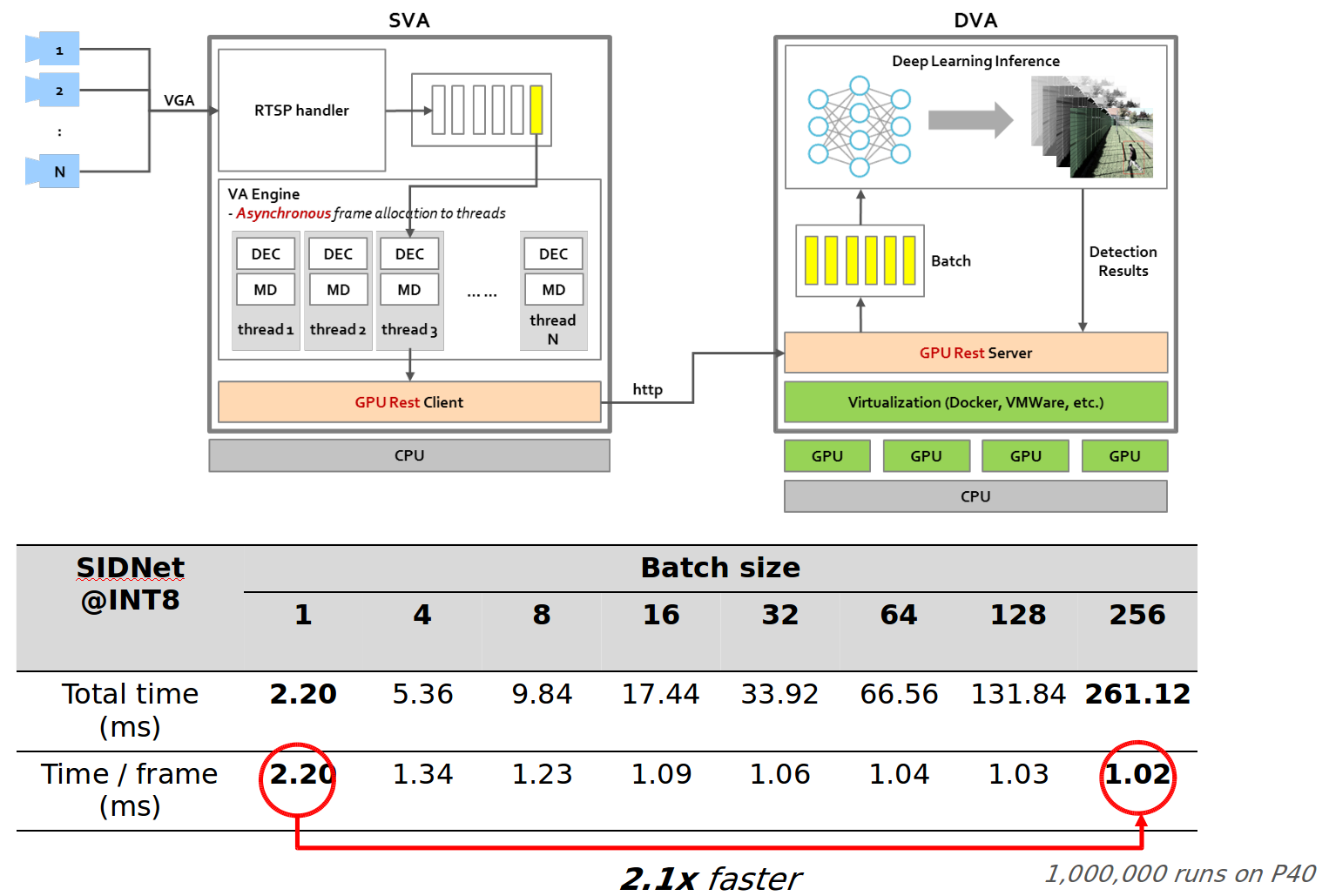
Last but not least, batch inference becomes very important for scaling out the intrusion detection service to larger-scale video analytics. As Figure 9 shows, a batch size of 16 increases image detection performance for each image to 1220 fps, nearly 2x times faster compared to single batch inference. We performed more inference time tests with different batch sizes on NVIDIA Tesla P40 in Figure 9, which also shows that batch sizes greater than 16 improves the processing time for each image by 2x.
Conclusion
Accelerating deep learning-based object detection inference offers exciting potential for high-performance in a number of use cases in Telecomm AI. TensorRT enables strong inference acceleration while minimizing accuracy loss to just 1% when using INT8. The added performance over the already excellent YOLO-v2 suggests further improvement will be possible as NVIDIA improves TensorRT. We look forward to incorporating online learning techniques for large-scale intrusion detection service to improve the accuracy of each camera further. Find more details about this topic in our presentation at the 2018 NVIDIA GPU Technology Conference.
References
[An et al. 2018] Accelerating Large-Scale Video Surveillance for Smart Cities with TensorRT. Shounan An, Seungji Yang, Hyungjoon Cho (NVIDIA GTC 2018)
[Migacz 2017] 8-bit Inference with TensorRT. Szymon Migacz (NVIDIA GTC 2017)
[Redmon et al. 2017] YOLO9000: Better, Faster, Stronger. Joseph Redmon, Ali Farhadi (CVPR 2017)
Session presented in GTC 2018 Silicon Valley http://on-demand-gtc.gputechconf.com/gtc-quicklink/3wKle
