Researchers at SK Telecom developed a new method that uses the NVIDIA TensorRT high-performance deep learning inference engine to accelerate deep learning-based object detection. The method can be used on a variety of projects including monitoring patients in hospitals or nursing homes, performing in-depth player analysis in sports, to helping law enforcement find lost or abducted children.
The method, first presented at the GPU Technology Conference in San Jose this year, focuses on increasing the accuracy of human detection and maximizing throughput for real-time inference applications.
Their TensorRT integration resulted in a whopping 6x increase in performance.
“SIDNet runs 6x faster on an NVIDIA Tesla V100 using INT8 than the original YOLO-v2, confirmed by verifying SIDNet on several benchmark object detection and intrusion detection data sets,” said Shounan An, a machine learning and computer vision engineer at SK Telecom. “This 6x increase in performance came at the expense of reducing accuracy by only 1% compared with FP32 mode.”
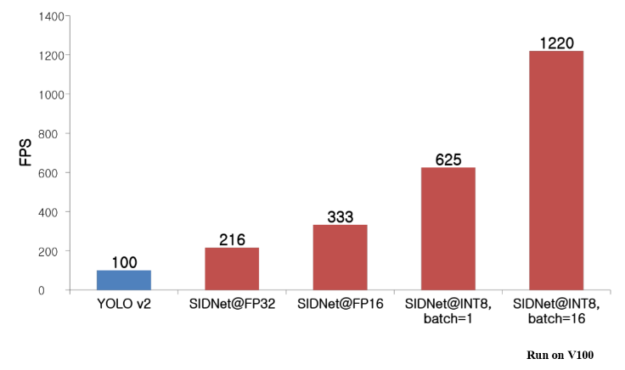
“TensorRT enables strong inference acceleration while minimizing accuracy loss to just 1% when using INT8. The added performance over the already excellent YOLO-v2 suggests further improvement will be possible as NVIDIA improves TensorRT,” An said.
A technical blog was published today on NVIDIA’s Developer Blog. The team also performed inference time tests with various batch sizes and described them in the post.
Read more >
TensorRT Radically Improves Real-Time Object Detection by 6x

Jun 07, 2018
Discuss (0)
AI-Generated Summary
- Researchers at SK Telecom developed a method to accelerate deep learning-based object detection using NVIDIA's TensorRT engine, which can be applied to various projects such as monitoring patients and helping law enforcement.
- The integration of TensorRT resulted in a 6x increase in performance, with Shounan An confirming that SIDNet runs 6x faster on an NVIDIA Tesla V100 using INT8 than the original YOLO-v2.
- The performance improvement came with a minimal loss of accuracy, reducing it by only 1% compared to FP32 mode, demonstrating TensorRT's ability to accelerate inference while maintaining accuracy.
AI-generated content may summarize information incompletely. Verify important information. Learn more