A critical question to ask when designing a machine learning–based solution is, “What’s the resource cost of developing this solution?” There are typically many factors that go into an answer: time, developer skill, and computing resources. It’s rare that a researcher can maximize all these aspects, so optimizing the solution development process is critical. This problem is further aggravated in robotics, as each task typically requires a completely unique solution that involves a nontrivial amount of handcrafting from an expert.
Typical robotics solutions take weeks, if not months, to develop and test. Dexterous, multifinger object manipulation has been one of the long-standing challenges in control and learning for robot manipulation. For more information, see the following papers:
- An overview of dexterous manipulation
- Relaxed-Rigidity Constraints: Kinematic Trajectory Optimization and Collision Avoidance for In-Grasp Manipulation
- Optimal control with learned local models: Application to dexterous manipulation
- Dexterous Manipulation with Deep Reinforcement Learning: Efficient, General, and Low-Cost
While challenges in high-dimensional control for locomotion as well as image-based object manipulation with simplified grippers have made remarkable progress in the last 5 years, multifinger dexterous manipulation remains a high-impact yet hard-to-crack problem. This challenge is due to a combination of issues:
- High-dimensional coordinated control
- Inefficient simulation platforms
- Uncertainty in observations and control in real-robot operation
- Lack of robust and cost-effective hardware platforms
These challenges coupled with lack of availability of large-scale compute and robotic hardware has limited diversity among the teams attempting to address these problems.
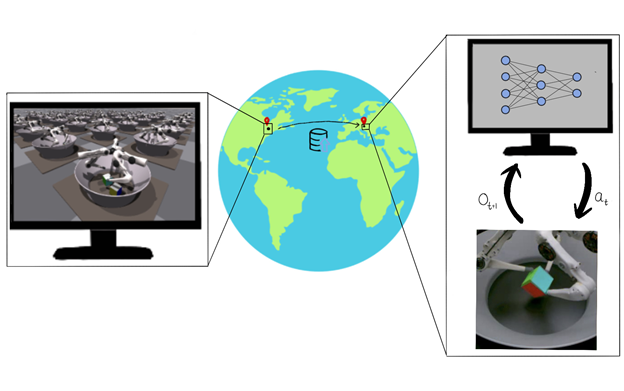
Our goal in this effort is to present a path for democratization of robot learning and a viable solution through large-scale simulation and robotics-as-a-service. We focus on six degrees of freedom (6DoF) object manipulation by using a dexterous multifinger manipulator as a case study. We show how large-scale simulation done on a desktop-grade GPU and with cloud-based robotics can enable roboticists to perform research in robotic learning with modest resources.
While several efforts in in-hand manipulation have attempted to build robust systems, one of the most impressive demonstrations came a few years ago from a team at OpenAI that built a system termed Dactyl. It was an impressive feat of engineering to achieve multiobject in-hand reposing with a shadow hand.
However, it was remarkable not only for the final performance but also in the amount of compute and engineering effort to build this demo. As per public estimates, it used 13,000 years of computing and the hardware itself was costly and yet required repeated interventions. The immense resource requirement effectively prevented others from reproducing this result and as a result building on it.
In this post, we show that our systems effort is a path to address this resource inequality. A similar result can now be achieved in under a day using a single desktop-grade GPU and CPU.
Complexity of standard pose representations in the context of reinforcement learning
During the initial experimentation, we followed previous works in providing our policy with observations based on a 3D Cartesian position plus a four-dimensional quaternion representation of pose to specify the current and target position of the cube. We also fixed the reward based on the L2 norm (position) and angular difference (orientation) between the desired and current pose of the cube. For more information, see the Learning Dexterity OpenAI post and GPU-Accelerated Robotic Simulation for Distributed Reinforcement Learning.
We found this approach to produce unstable reward curves, which were good at optimizing the position portion of the reward, even after adjusting relative weightings.
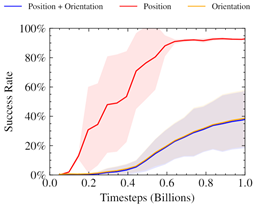
Prior work has shown the benefits of alternate representations of spatial rotation when using neural networks. Furthermore, it has been shown that mixing losses this way can lead to collapsing towards only optimizing a single objective. The chart implies a similar behavior, where only the position reward is being optimized for.
Inspired by this, we searched for a representation of pose in SO(3) for our 6DoF reposing problem. This would also naturally trade off position and rotation rewards in a way suited to optimization through reinforcement learning.
Closing the Sim2Real gap with remote robots
The problem of access to physical robotic resources was exacerbated by the COVID-19 pandemic. Those previously fortunate enough to have access to robots in their research groups found that the number of people with physical access to the robots was greatly decreased. Those that relied on other institutions to provide the hardware were often alienated completely due to physical distancing restrictions.
Our work demonstrated the feasibility of a robotics-as-a-service (RaaS) approach in tandem with robot learning. A small team of people trained to maintain the robot and a separate team of researchers could upload a trained policy and remotely collect data for postprocessing.
While our team of researchers was primarily based in North America, the physical robot was in Europe. For the duration of the project, our development team was never physically in the same room as the robots on which we were working. Remote access meant that we could not vary the task at hand to make it easier. It also limited the kinds of iteration and experiments that we could do. For example, reasoned system identification was not possible, as our policy ran on a randomly chosen robot in the entire farm.
Despite the lack of physical access, we found that we were able to produce a robust and working policy to solve the 6DoF reposing task through a combination of several techniques:
- Realistic GPU-accelerated simulation
- Model-free RL
- Domain randomization
- Task-appropriate representation of pose
Method overview
Our system trains using the IsaacGym simulator on 16,384 environments in parallel on a single NVIDIA V100 or NVIDIA RTX 3090 GPU. Inference is then conducted remotely on a TriFinger robot located across the Atlantic in Germany using the uploaded actor weights. The infrastructure on which we perform Sim2Real transfer is provided courtesy of the organizers of the Real Robot Challenge.
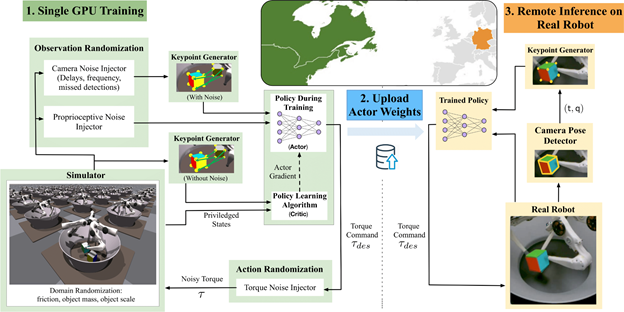
Collect and process training examples
Using the IsaacGym simulator, we gathered high-throughput experience (~100K samples/sec on an NVIDIA RTX 3090). The sample’s object pose and goal pose are to eight keypoints of the object’s shape. Domain randomizations were applied to the observations and environment parameters to simulate variations in the proprioceptive sensors of the real robots and cameras. These observations, along with some privileged state information from the simulator, were then used to train our policy.
Train the policy
Our policy was trained to maximize a custom reward using the proximal policy optimization (PPO) algorithm. Our reward incentivized the policy to balance the distance of the robot’s fingers from the object, speed of movement, and distance from the object to a specified goal position. It solved the task efficiently, despite being a general formulation applicable broadly across in-hand manipulation applications. The policy output the torques for each of the robot’s motors, which were then passed back into the simulation environment.
Transfer the policy to a real robot and run inference
After we trained the policy, we uploaded it to the controller for the real robot. The cube was tracked on the system using three cameras. We combined proprioceptive information available from the system along with the converted keypoints representation to provide input to the policy. We repeated the camera-based cube-pose observations for subsequent rounds of policy evaluation to enable the policy to take advantage of the higher-frequency proprioceptive data available to the robot. The data collected from the system was then used to determine the success rate of the policy.
The tracking system on the robot currently only supports cubes. However, this could be extended in future to arbitrary objects.
Results
The keypoints representation of pose greatly improves success rate and convergence.
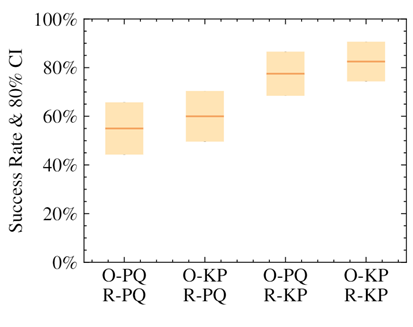
We demonstrated that the policies that used our keypoint representation, in either the observation provided to the policy or in reward calculation, achieved a higher success rate than using a position+quaternion representation. The highest performance came from the policies that used the alternate representation for both elements.
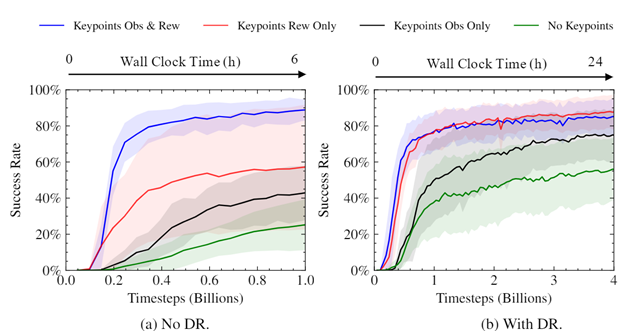
We performed experiments to see how the use of keypoints impacted the speed and convergence level of our trained policies. As can be seen, using keypoints as part of the reward considerably sped up training, improved the eventual success rate, and reduced variance between trained policies. The magnitude of the difference was surprising, given the simplicity and generality of using keypoints as part of the reward.
The trained policies can be deployed straight from the simulator to remote real robots (Figure 5).

Figure 6 displays an emergent behavior that we’ve termed “dropping and regrasping.” In this maneuver, the robot learns to drop the cube when it is close to the correct position, regrasp it, and pick it back up. This enables the robot to get a stable grasp on the cube in the right position, which leads to more successful attempts. It’s worth noting that this video is in real time and not sped up in any way.
The robot also learns to use the motion of the cube to the correct location in the arena as an opportunity to rotate it on the ground simultaneously. This helps achieve the correct grasp in challenging target locations far from the center of the fingers’ workspace.

Our policy is also robust towards dropping. The robot can recover from a cube falling out of the hand and retrieve it from the ground.
Robustness to physics and object variations
We found that our policy was robust to variations in environment parameters in simulation. For example, it gracefully handled scaling up and down of the cube by ranges far exceeding randomization.


Surprisingly, we found that our policies were able to generalize 0-shot to other objects, for example, a cuboid or a ball.
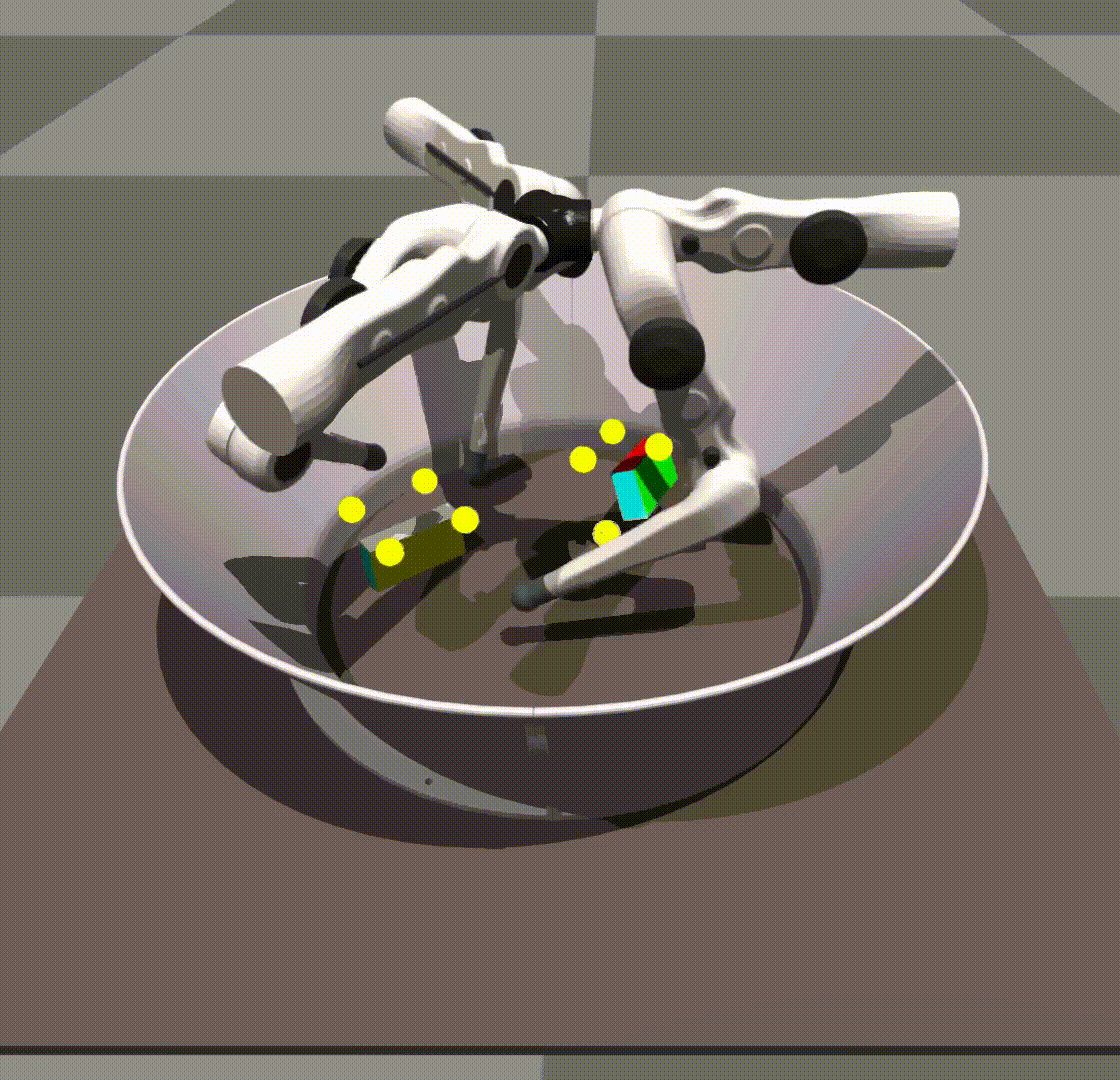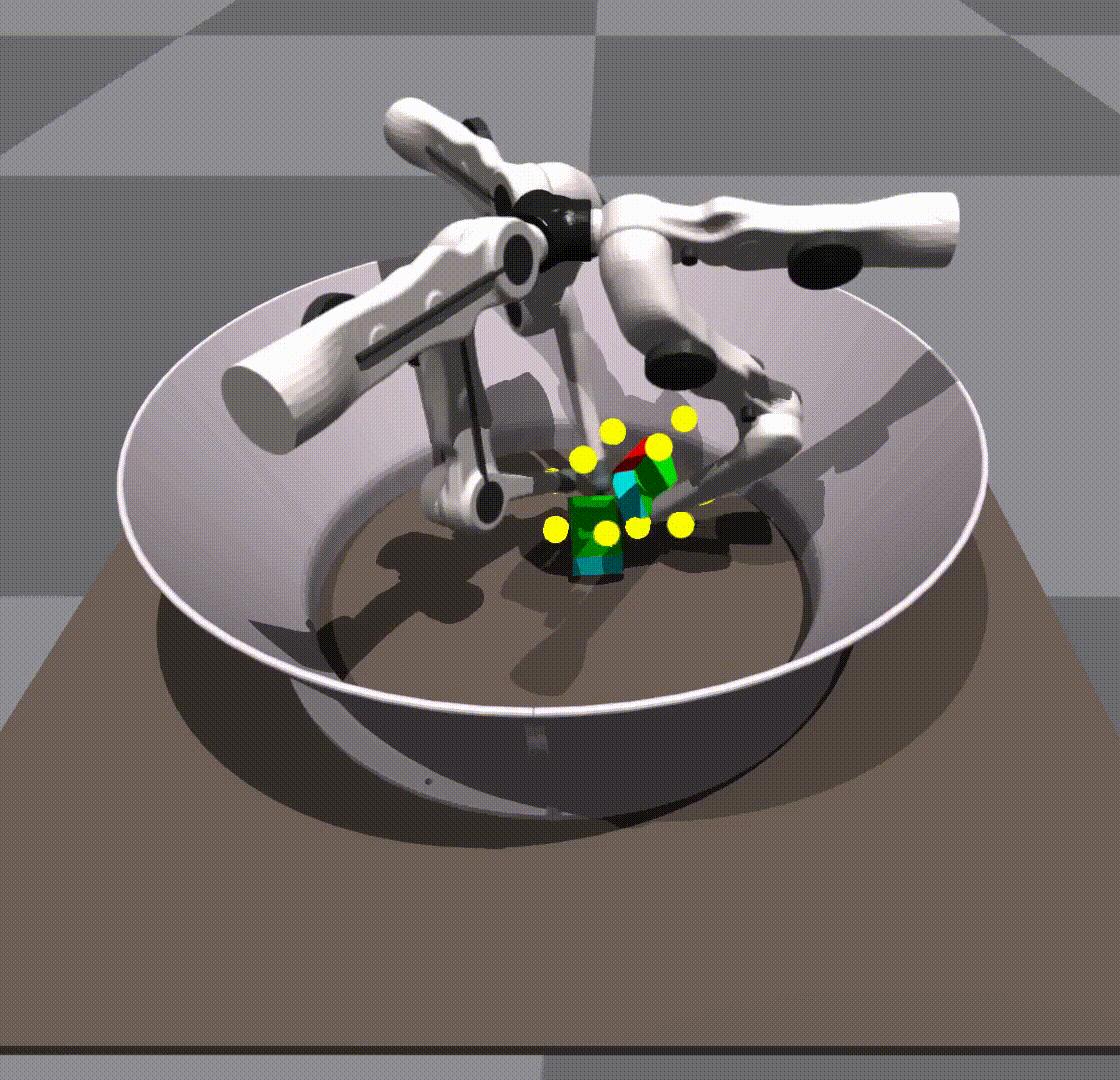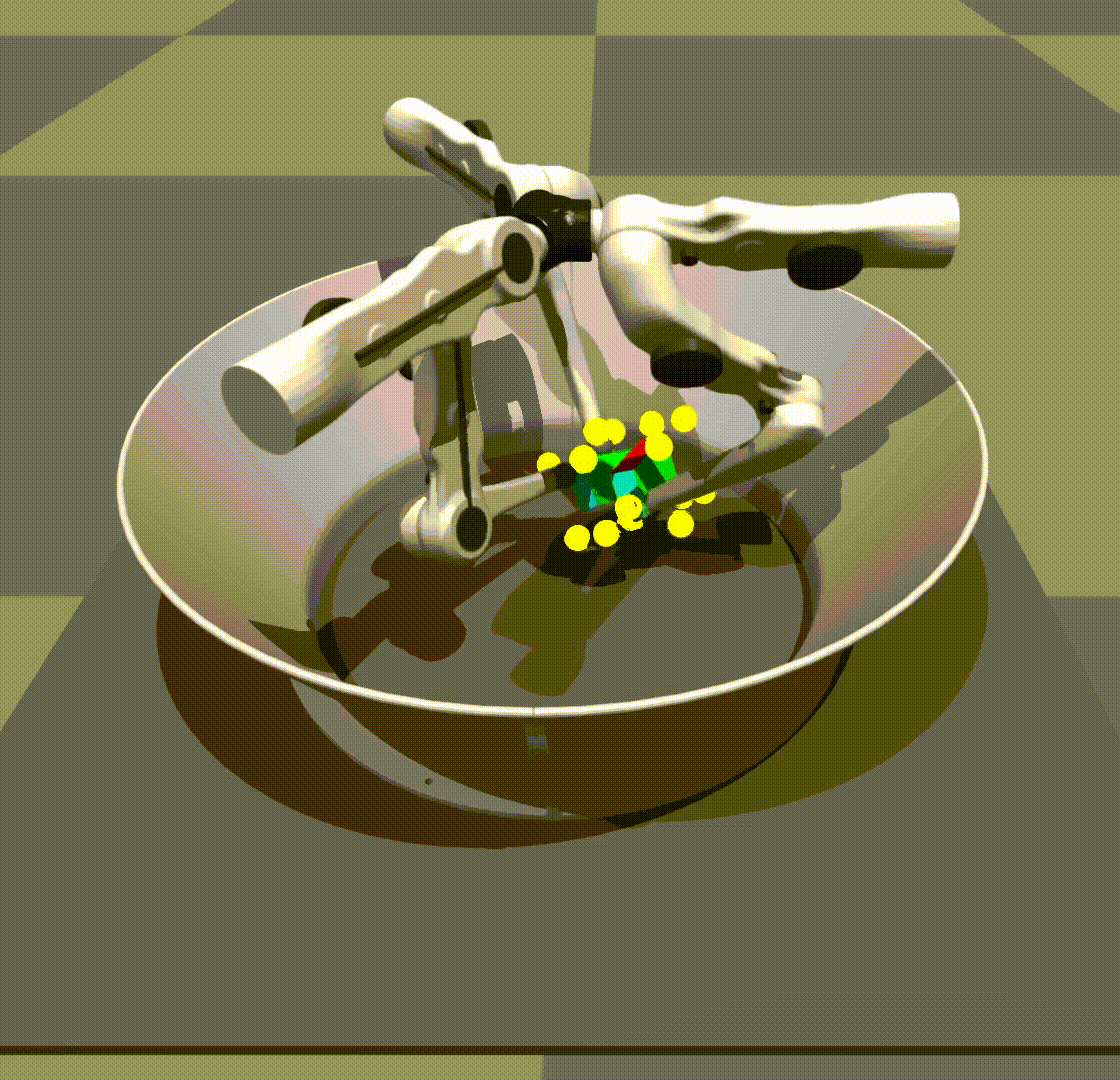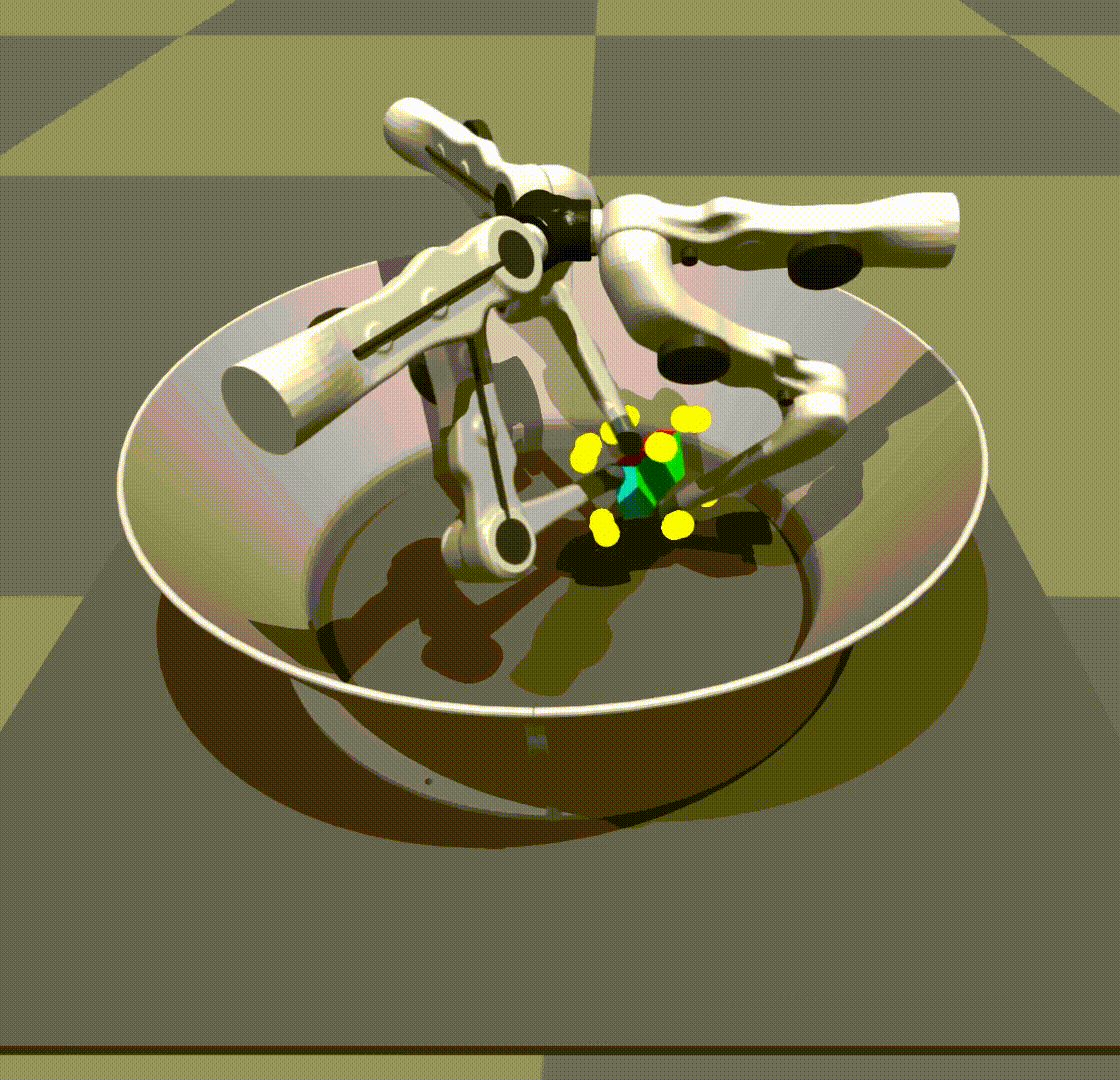

Generalization in scale and object is taking place due to the policy’s own robustness. We do not give it any shape information. The keypoints remain in the same place as they would on a cube.

Conclusion
Our method shows a viable path for robot learning through large-scale, GPU-based simulation. In this post, we showed you how it is possible to train a policy using moderate levels of computational resources (desktop-level compute) and transfer it to a remote robot. We also showed that these policies are robust to a variety of changes in the environment and the object being manipulated. We hope our work can serve as a platform for researchers going forward.
NVIDIA has also announced broad support for the Robotics Operating System (ROS) with Open Robotics. This important Isaac ROS announcement underlines how NVIDIA AI perception technologies accelerate AI utilization in the ROS community to help roboticists, researchers, and robot users looking to develop, test, and manage next-generation, AI-based robots.
For more information about this research, see the Transferring Dexterous Manipulation from GPU Simulation to a Remote Real-World Trifinger GitHub page, which includes a link to the whitepaper. To learn more about robotics research at NVIDIA and the work being done across the NVIDIA developer community, register free for NVIDIA GTC.
Acknowledgments
This work was led by University of Toronto in collaboration with NVIDIA, Vector Institute, MPI, ETH, and Snap. We would like to thank Vector Institute for computing support, as well as the CIFAR AI Chair for research support to Animesh Garg.
