
Researchers at NVIDIA’s Seattle Robotics Lab developed a new algorithm, called 6-DoF GraspNet, that allows robots to grasp arbitrary objects.
Grasping is an essential building block in current and future robotic systems, ranging from warehouse logistics to service robotics.
Imagine a robot is asked to pick up an object and put it in a container. The robot observes the object and needs to decide where to move its gripper in 6D space (3D position and 3D rotation) to pick it up. The problem is complex as the success of grasps depends on object and gripper geometry, object mass distribution, and surface friction.

Grasping a mug using 6-DoF GraspNet
For the case of known objects, one can solve the problem by transferring the pre-defined set of grasps in the object canonical pose using the estimated pose of the object. Pose estimation methods are not scalable to large number of object categories which limits the number of objects that the robot can interact with. For unknown objects, the problem becomes more challenging as the space of 6-DoF grasps is significantly larger. To simplify the problem, previous methods have formulated the problem by representing the grasp with an oriented rectangle in the image plane. Such representations constrain the grasps to be perpendicular to the support surface of the target object which leads to a severely restricted workspace for the robot. 6-DoF GraspNet relaxes these constraints by generating a diverse set of 6-DoF grasps directly from partially observed point clouds.

Grasping a salt container using 6-DoF GraspNet
GraspNet consists of three parts: grasp sampling, grasp evaluation, and grasp refinement. The grasp sampler is a conditional variational auto-encoder that maps the pair of grasp and point cloud to a latent value assuming the latent space is normally distributed. Then each of the generated grasps is assigned a score by the grasp evaluator. Finally, the grasp refinement module improves the probability of success by applying local transformation to the generated grasps.
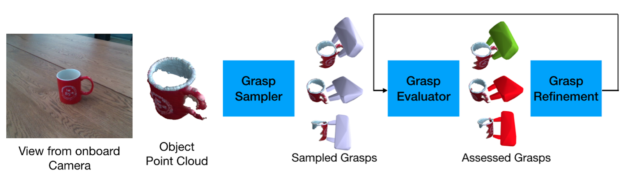
Overview of the 6-DoF GraspNet
Deep learning based methods are typically data intensive and collecting training data for robotic tasks is resource-intensive and tedious. It usually requires multiple robots collecting data for days and months to have enough data to train the model. Instead, 6-DoF GraspNet uses synthetic training data. It consists of 3D object models and simulated grasp experiences. For each object, grasp hypotheses are generated using geometric heuristics and evaluated with the NVIDIA FleX physics engine.
During training, objects are rendered at random viewpoints to generate the point cloud and the simulated grasps are used to learn the parameters of the model. The model is trained on random boxes, cylinders, mugs, bowls, and bottles. The model is trained with 8 NVIDIA V100 GPUs.

Evaluation of Grasps using NVIDIA FleX
The advantage of 6-DoF GraspNet is that it’s modular and can be used with other computer vision and motion planning algorithms instead of solving all the problems end-to-end. Consider the task of collecting all objects from a table and putting them into a container. The problem can be solved by using 6-DoF GraspNet and a model that segments generic objects. The point cloud of each object is extracted from segmented objects and grasps are generated using 6-DoF GraspNet. Other objects in the scene are approximately represented by cubes as obstacles for motion planning module so that the robot arm does not collide with other objects in the scene.
This work was presented at ICCV 2019. Details of the work can be found here.
