Click-through rate (CTR) estimation is one of the most critical components of modern recommender systems. As the volume of data and its complexity grow rapidly, the use of deep learning (DL) models to improve the quality of estimations has become widespread. They generally have greater expressive power than traditional machine learning (ML) approaches. Frequently evolving data also implies that the lifespan of a trained model tends to be short. Fast and iterative training of a model is important to sustain the competitiveness of a service.
In this post, we introduce HugeCTR, a GPU-accelerated training framework for CTR estimation. It is open-sourced and highly optimized for performance on NVIDIA GPUs while allowing users to customize their models in JSON format.
HugeCTR, on a single NVIDIA V100 GPU, achieves a speedup of up to 114X over TensorFlow on a 40-core CPU node, and up to 8.3X that of TensorFlow on the same V100 GPU. HugeCTR, in its version 2.1, facilitates the training of the three state of the art models: Wide & Deep, DCN, and DeepFM. DLRM support will be available soon.
HugeCTR is also a pillar of NVIDIA Merlin, a framework and ecosystem created to facilitate all phases of recommender system development, accelerated on NVIDIA GPUs.
Background
In this section, we briefly discuss what CTR estimation does in modern recommender systems and the major challenges in their training.
CTR estimation in recommender systems
From online advertising and e-commerce to streaming services, recommender systems have become ubiquitous while having a huge impact on service provider revenue.
Recommender systems find the most clickable items by a given user, so that it can rank them and show top-N items to the user. To achieve this goal, a recommender system first must estimate the likelihood that the items will be clicked on by a specific user. This task is commonly referred to as CTR estimation.
How can you magically estimate the CTR? There’s no sorcery here. Take a rich dataset that includes past user-item interactions and use it to train a ML model.
Each record in the dataset can consist of features from a user (age, job), item (type, price), and user item-click (0 or 1). For example, if user A purchased or clicked several biographies from a range of books, it would make sense for a model to assign high probability values to biographies.
Challenges in CTR estimation training
Large-scale recommender systems experience frequent changes related to users and items. It’s crucial to discern implicit feature interactions behind user clicks, so that the recommender systems can provide more generalized recommendations of higher quality. For example, married people who are younger than 30 years old and whose child is under 2 years old might be inclined to buy high-ABV beers.
Modeling these implicit feature interactions requires non-trivial feature engineering by domain experts. To make matters worse, it is often infeasible even for human experts to discover those interactions, on account of drastic complexity and non-intuitiveness of features. In lieu of depending upon experts, DL-based approaches such as Wide & Deep, DeepFM, and DLRM have emerged to capture these complex interactions.
Another challenge in training CTR estimation models is that users and items change almost daily, so the lifespan of a trained model is likely to be short. In addition, due to the increase in size, dimensionality, and sparsity of datasets, a CTR model often includes a large embedding table, which may not fit in a single GPU or even in a node with multiple GPUs. Thus, data loading, embedding lookups, and inter-GPU communication can represent a significant portion of the training time of the model.
These factors, mixed with the absence of a standardized modeling method for CTR estimation, have often required service providers to maintain their in-house codes. As a result, they frequently suffer from suboptimal performance in terms of throughput and latency. It’s important to facilitate faster iterative training of models on a single or multiple GPUs.
In this post, we focus on how NVIDIA has accelerated the large-scale CTR estimation training in CUDA C++. For more information about accelerating recommender inference on GPU based on TensorRT, see Accelerating Wide & Deep Recommender Inference on GPUs.
HugeCTR
HugeCTR is an open-source framework to accelerate the training of CTR estimation models on NVIDIA GPUs. It is written in CUDA C++ and highly exploits GPU-accelerated libraries such as cuBLAS, cuDNN, and NCCL.
It was started as an internal prototype to evaluate the potential of GPU on CTR estimation problems. It soon became a reference design for customers to enable and optimize GPU-based recommender systems by iteratively collaborating with us. Because it has naturally become a more general-purpose framework designated for CTR estimation, we open-sourced its initial version in September 2019 to embrace external feedback while keeping engagement with some customers. We are actively developing HugeCTR to extend its functions and enhance performance.
In this post, we are pleased to announce version 2.1 while highlighting key features and performance. HugeCTR is also the training pillar of Merlin, which GPU-accelerates data engineering, training, and production of recommender systems. If you are interested in Merlin and its other pillars, see Announcing NVIDIA Merlin: An Application Framework for Deep Recommender Systems.
Architecture
Figure 1 (a) depicts the steps of a DL model for CTR estimation:
- Read batched data records, each of which consists of high-dimensional, extremely sparse (or categorical) features. Each record can also include dense numerical features, which can be fed directly to the fully connected layers.
- Use an embedding layer to compress the input-sparse features to lower-dimensional, dense-embedding vectors. For example, if there are N sparse features and the embedding dimension is K, the embedding table generates N K-dimensional, dense vectors.
- Use a feed-forward neural network to estimate CTRs.
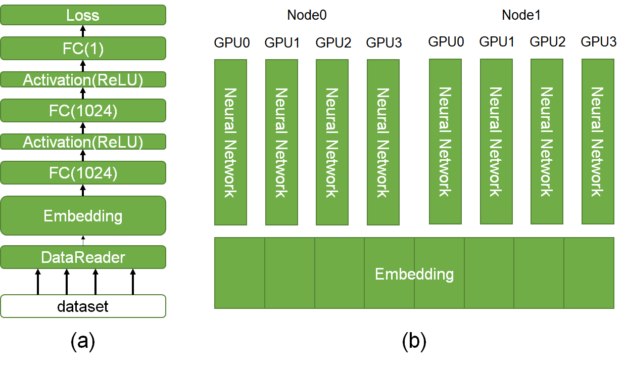
HugeCTR not only supports all the three steps but also enhances the end-to-end performance:
- To prevent data loading from becoming a major bottleneck in training, it implements a dedicated data reader that is inherently asynchronous and multithreaded.
- The embedding stages are GPU-accelerated, including table lookup, weight reduction within each slot, and weight concatenation across the slots.
- All the layers, optimizers, and loss functions in both forward and backward propagations are implemented in CUDA C++, by leveraging effective CUDA optimization techniques and CUDA-enabled libraries.
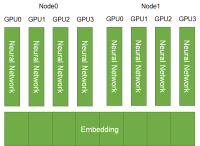
To train a large-scale CTR estimation model, the HugeCTR embedding table can span multiple nodes beyond multiple GPUs (model parallelism). In the meantime, each GPU has its own feed-forward neural network (data parallelism). The resulting architecture is summarized in Figure 1 (b).
Extended architecture in version 2.1
Because hybrid models composed of a linear model and a deep model have become common, the HugeCTR architecture version 2.1 is extended to support models like Wide & Deep, DCN, and DeepFM. The update includes the new data reader, which can read both continuous and categorical input data simultaneously; and new layers including Factorization Machine and Cross Layer. To enable more flexible design space exploration, we also added Dropout, L1/L2 Regularizers, and so on.
Highlighted features
In this section, we introduce the key features of HugeCTR, which contribute to its high performance and usability.
Multi-slot embedding with in-memory GPU hash table
In CTR estimation, embedding is almost essential to achieve a decent model accuracy. It often incurs the high demand of both in-memory capacity and bandwidth with the decent amount of parallelism.
If embedding is distributed across multiple GPUs or multiple nodes, the communication overhead can be also significant. Because of the large and increasing number of users and items, the huge embedding table is inevitable.
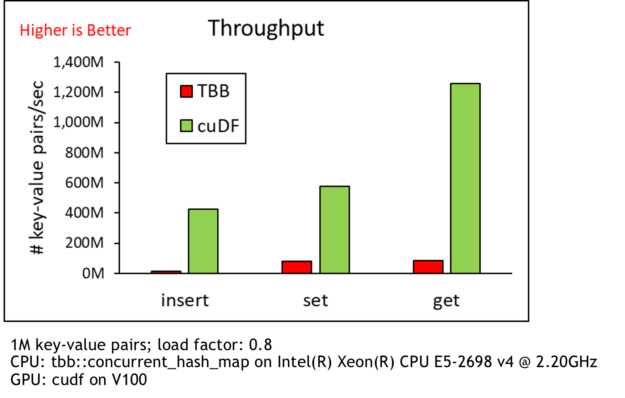
To overcome these challenges and enable faster training, we implemented our own embedding layer, which includes a GPU-accelerated hash table, and harnesses NCCL as its inter-GPU communication primitives. The hash table implementation is based on that of RAPIDS cuDF, which is a GPU DataFrame library from NVIDIA. The cuDF GPU hash table can achieve up to 35x speedup over concurrent_hash_map from Threading Building Blocks (TBB) as shown in Figure 2.
In summary, HugeCTR supports a model-parallel embedding table that spans multiple GPUs and multiple nodes in a homogeneous compute cluster.
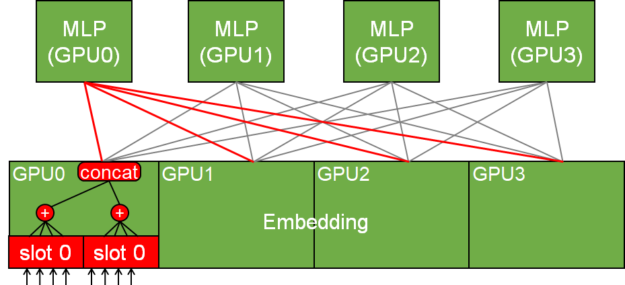
The embedding table can be segmented into multiple slots (or feature fields). During an embedding lookup, the input sparse features which belong to the same slot, after being converted to the corresponding dense embedding vectors independently, are reduced to a single embedding vector. Then, the embedding vectors from the different slots are concatenated together.
The multi-slot embedding improves inter-GPU bandwidth utilization in the following ways:
- It helps reduce the number of effective features within each slot to a manageable degree when there are a lot of features in the dataset.
- By concatenating the different slot outputs, the number of transactions across GPUs is reduced, which facilitates more efficient communication.
Figure 3 shows how the series of operations and inter-GPU communication (all2all) occur.
The multi-slot embedding is also useful in expressing a linear model, which is basically a weighted sum of the features, by just setting both the number of slots and the embedding dimension to one. For more information, see the Wide & Deep sample.
Asynchronous, multithreaded data pipeline
Without an efficient data pipeline, forward and backward propagation at the speed of light is like the situation in which travel time to the airport is way longer than the flight duration. In addition, when a dataset is large and frequently changes, it is quite legitimate to split it into multiple files.
To hide the long data fetch latency efficiently, HugeCTR has a multithreaded data reader that can overlap data fetching with the actual model training. As shown in Figure 4, DataReader is a façade that consists of multiple parallel workers, each of which reads a batch at a time from its assigned dataset files, and a collector that distributes the collected data records to the multiple GPUs. All the workers, the collector, and model training run concurrently on CPU as different threads.
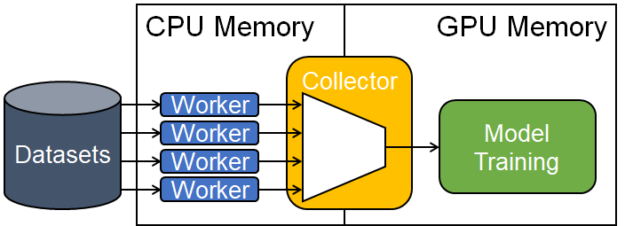
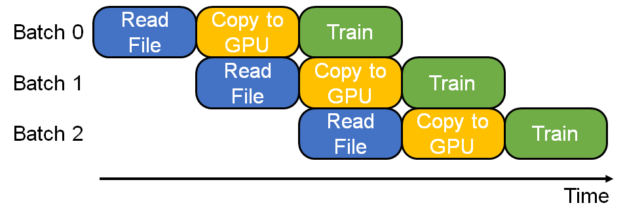
Figure 5 shows how the HugeCTR pipeline can overlap the data read from disk to CPU memory, data transfer from CPU to GPU, and the actual training on GPU across different batches.
Flexible model configuration in JSON format
Though there are some commonalities among CTR models, their details, including hyperparameters, can be different. To enable the flexible customization of models, HugeCTR allows you to configure their models intuitively in JSON format.
For instance, to describe a hybrid model like Figure 6 (a), you can write the “layers” clause as shown abstractly in Figure 6 (b). You can have multiple embeddings. You can also specify the batch size, optimizer, data paths, and so on. In the same config file, you can specify how many and which GPUs are used for training. For more information, see the HugeCTR User Guide and sample config files.


Mixed-precision training
Mixed-precision training has become a common technique to achieve further speedup while maintaining the model accuracy. In HugeCTR, fully connected layers can be configured to exploit tensor cores on NVIDIA Volta architecture and its successors. They internally use FP16 for the accelerated matrix multiplication, but its input and output remain FP32.
Performance Evaluation
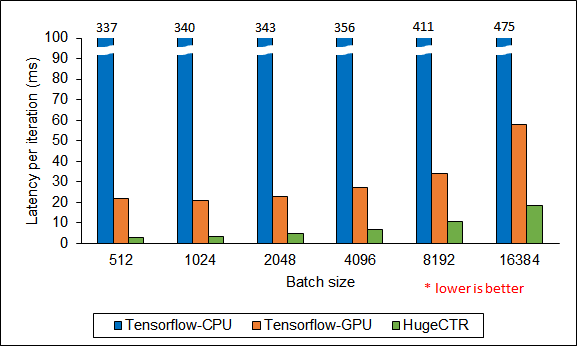
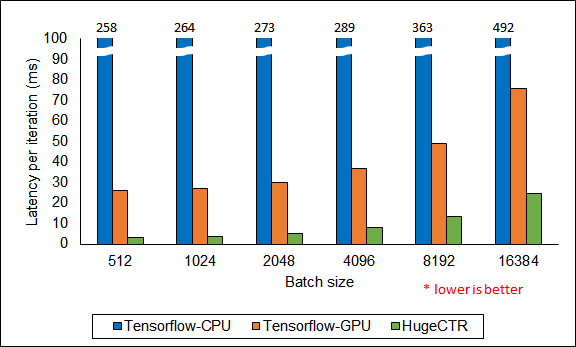
To evaluate the performance, we modeled a Wide & Deep (WDL) and DCN with Criteo dataset on both HugeCTR and TensorFlow. We ran our baseline TensorFlow models on a dual 20-core Intel Xeon CPU E5-2698 v4 (TensorFlow-CPU) and a V100 16GB GPU (TensorFlow-GPU). For both WDL and DCN, we used 2×1024 FC layers. The same models were configured in JSON format and ran with HugeCTR on the same GPU. Figure 7 shows the training performance of WDL across the various batch sizes. HugeCTR achieves a speedup of up to 114X over TensorFlow-CPU, and 7.4X that of TensorFlow-GPU.
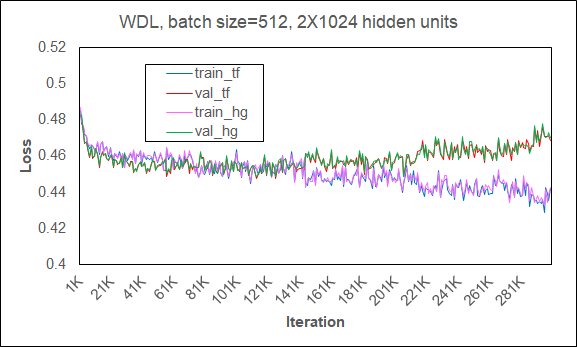
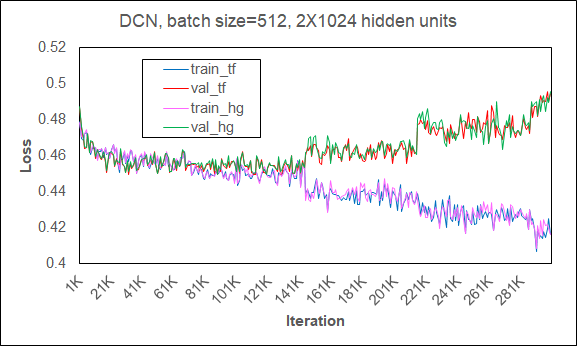
To make sure that HugeCTR runs the same model with TensorFlow, we also verified their training/validation loss curves are consistent for 300K iterations on Figure 8. For more information about the JSON model config and reproduction, see WDL CTR SAMPLE.
In Figures 9 and 10, we do the same comparison with DCN. For this model, HugeCTR achieves a speedup of up to 83X over TensorFlow-CPU, and 8.3X that of TensorFlow-GPU. The DCN config is also available in the HugeCTR repo.
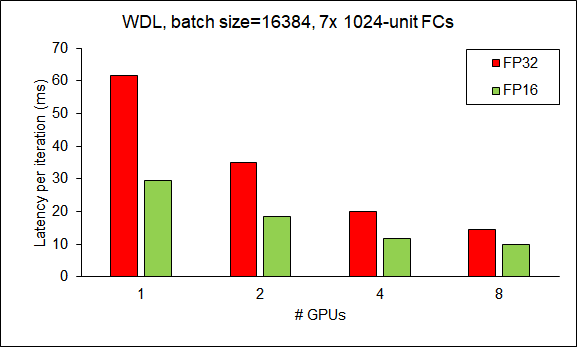
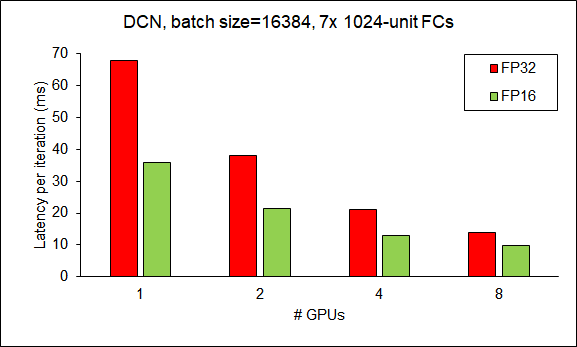
In Figures 11 and 12, we show the scalability of HugeCTR for WDL (a) and DCN (b) with 7xFC layers on a single DGX-1 when the batch size is 16384. In increasing the number of active GPUs from 1 to 8, it shows the good speedup in both the full-precision mode (FP32) and mixed-precision mode (FP16).
Conclusion
In this post, we introduced HugeCTR, which is an industry-oriented training framework for recommender systems, optimized for large-scale CTR models with model-parallel embeddings and data-parallel dense networks.
HugeCTR just embarked on a journey as a pillar of Merlin, a framework facilitating and accelerating all phases of recommender system development. We are actively working on reinforcing the connectivity with the other pillars. If you are interested in data preprocessing and feature engineering, see Accelerating ETL for Recommender Systems on NVIDIA GPUs with NVTabular.
For user convenience, we provide a Docker image, where all the dependent libraries are preinstalled. As mentioned earlier, we ship a few sample models that you can try, including instructions on how to preprocess such data. We also collected frequently asked questions and their answers. Feel free to add a comment if you have any questions about running those samples or using HugeCTR for your own models.
