
Recommender systems are ubiquitous in online platforms, helping users navigate through an exponentially growing number of goods and services. These models are key in driving user engagement. With the rapid growth in scale of industry datasets, deep learning (DL) recommender models have started to gain advantages over traditional methods by capitalizing on large amounts of training data.
The current challenges for training large-scale recommenders include:
- Huge datasets: Commercial recommenders are trained on huge datasets, often several terabytes in scale.
- Complex data preprocessing and feature engineering pipelines: Datasets need to be preprocessed and transformed into a form relevant to be used with DL models and frameworks. In addition, feature engineering creates an extensive set of new features from existing ones, requiring multiple iterations to arrive at an optimal solution.
- Input bottleneck: Data loading, if not well optimized, can be the slowest part of the training process, leading to under-utilization of high-throughput computing devices such as GPUs.
- Extensive repeated experimentation: The whole data engineering, training, and evaluation process is generally repeated many times, requiring significant time and computational resources.
The time taken to prepare the dataset often exceeds the time it takes to train a deep recommender model itself. As a concrete example, processing the Criteo Terabyte dataset takes five and a half days to complete using the NumPy CPU script provided by Facebook, while training DLRM (Deep Learning Recommender Model) on the processed dataset takes two days on CPU and less than an hour on a single V100 GPU.
Accelerating this data preparation process is critical to addressing the volume and scale that next-generation recommender systems will require.
This post is intended for developers with intermediate to advanced background in data preprocessing, transformation, and feature engineering. It offers help for tackling extract-transform-load (ETL) operations on terabyte-scale tabular data with just 10-20 lines of high-level API code.
NVTabular: Fast tabular data transformation and loading
To manipulate these terabyte-scale datasets quickly and easily, NVIDIA introduces NVTabular, a feature engineering and preprocessing library for recommender systems. It provides a high-level abstraction to simplify code and accelerates computation on the GPU using the RAPIDS cuDF library.
Using NVTabular, with just 10-20 lines of high-level API code, you can set up a data engineering pipeline and achieve up to 10x speedup compared to optimized CPU-based approaches while experiencing no dataset size limitations, regardless of the GPU/CPU memory capacity.
NVTabular focuses on the data preparation and data-loading phase. Here’s a common recommender system pipeline.
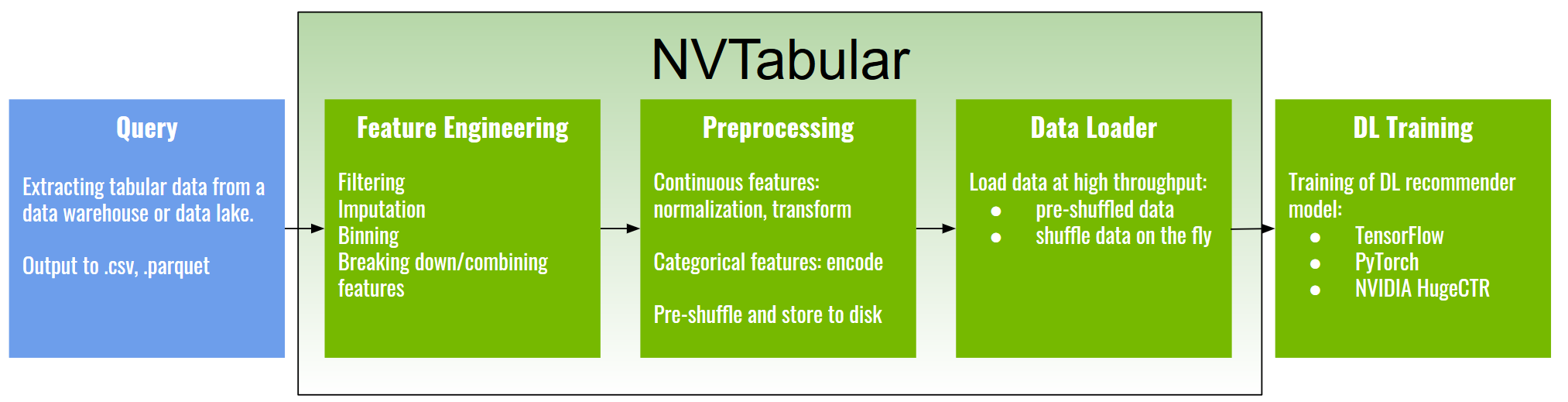
The first step of getting data for training a recommender model is to query from some data source, for example a data warehouse or data lake. The output of this step is normally some form of tabular data in a compressed parquet, ORC, or CSV format. An example dataset of this kind is the Criteo Terabyte click logs dataset, one of the largest known public recommender system datasets.
Next are the feature engineering and preprocessing steps, such as the following:
- Filtering outliers or missing values, or creating new features indicating that a value is missing
- Imputing and filling in missing data
- Discretization or bucketing of continuous features
- Creating features by splitting or combining existing features, for example, breaking down a date column into day-of-week, month-of-year, day-of-month features
- Normalizing numerical features to have zero mean and unit variance or applying transformations, for example with log transform
- Encoding discrete features using one-hot vectors or converting them to continuous integer indices
The processed data can be shuffled and saved to disk in a compressed format. It is ready to be loaded into one of the DL frameworks, such as TensorFlow, PyTorch, or the NVIDIA recommender-dedicated training framework, NVIDIA HugeCTR, using NVTabular accelerated data loaders.
The NVTabular fast feature engineering and transformation capabilities allow for creating many dataset variations for quick experimentation, while the data loader makes data available to DL frameworks at a much higher throughput, eliminating the input bottleneck at training time.
Under the hood, NVTabular is an abstraction built on top of NVIDIA RAPIDS, a GPU-accelerated library for data science. RAPIDS comes with its own library for handling GPU DataFrames, called cuDF. However, compared to cuDF and pandas, which is another popular library for handling DataFrames, NVTabular has some prominent advantages, summarized in the following table. Spark is capable of more than handling DataFrames but is often employed for preprocessing large-scale tabular data and so is included for comparison.
| Features | NVTabular | cuDF | pandas | Spark3 |
| GPU-acceleration ~ | 10x | 10x | No | 3x |
| Dataset size limitation | Unlimited | GPU memory | CPU memory | Unlimited |
| Code complexity | Simple | Moderate | Moderate | Complex |
| Flexibility | Mid (but extensible) | High | High | High |
| Lines of code ~ | 10-20 | 100-1000 | 100-1000 | 300-1000 |
| Relative I/O cost | 1 | # of ops | # of ops | 1+ |
| Data-loading transforms | Yes | No | No | No |
| Inference transforms | Yes | No | No | No |
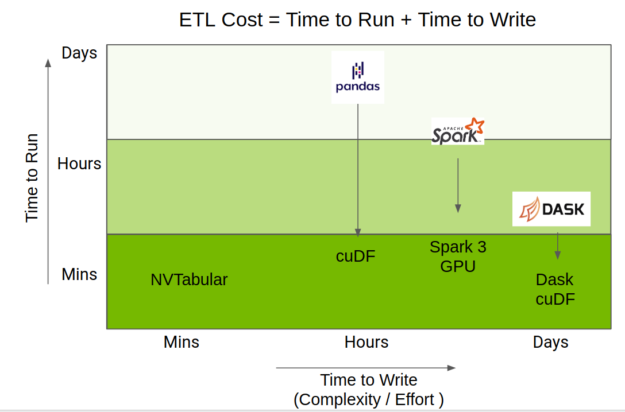
The total time taken to do ETL is a mix of the time to run the code, but also the time taken to write it. The RAPIDS team has done amazing work accelerating the Python data science ecosystem on GPU, providing acceleration of pandas operations through cuDF, Spark through GPU capabilities of Apache Spark 3.0, and Dask-pandas through Dask-cuDF.
NVTabular uses those accelerations but provides a higher-level API focused on recommender systems, which greatly simplifies code complexity while still providing the same level of performance. Figure 2 shows the positioning of NVTabular relative to other DataFrame libraries.
NVTabular: Technical advantages
NVTabular has three main advantages:
- Performance: Lazy execution and GPU-acceleration improve performance up to 10x.
- Scale: Dataset operations scale beyond GPU/CPU memory.
- Usability: Fewer API calls are required to accomplish the same processing pipeline.
Performance
NVTabular is designed to minimize the number of passes through the data. This is achieved with a lazy execution strategy. Data operations are not executed until an explicit apply phase. In the first phase, these operations are only registered into the workflow. This allows NVTabular to optimize the collection of statistics that require iteration over the entire dataset.
Some examples of operators that require global statistics include:
- Normalize numerical features: This relies on two statistics, the mean and standard deviation of the whole data.
- Encoding categorical features with a frequency threshold: This requires collecting statistics of the category occurrences from the whole data.
When processing terabyte-scale datasets, it is critical to plan this statistics-gathering phase as well as transformation phase carefully in advance and avoid unnecessary passes through the data.
NVTabular requires at most N passes through the data, where N is the number of chained operations. This is often less as lazy execution allows for careful planning and optimization of the workflow. Other libraries, such as cuDF and pandas, due to their eager execution nature, do not allow workflow optimization and can iterate through the whole dataset as many times as the number of operations.
NVTabular not only provides a quick means for preprocessing data, but also provides a fast means for data loading into DL frameworks. In NVTabular, NVIDIA provides an option to shuffle the dataset before storing to disk. The uniformly shuffled dataset enables the data loader to read in contiguous chunks of data that are already randomized across the entire dataset.
NVTabular provides the option to control the number of chunks that are combined into a batch, allowing the end user flexibility when trading off between performance and true randomization. This mechanism is critical when dealing with datasets that exceed CPU memory and per-epoch shuffling is desired during training. Full shuffle of such a dataset can exceed training time for the epoch by several orders of magnitude.
Scale
While NVTabular is built upon the RAPIDS cuDF library, it improves cuDF in a major way: Data is not limited to GPU or even CPU memory capacity. CuDF can achieve amazing speedup when the dataset fits into GPU memory. However, it is not designed to handle datasets that scale beyond GPU memory out-of-the-box. NVTabular processes data in chunks that fit in GPU memory, supporting datasets larger than CPU/GPU memory.
Usability
A complex data transform and preprocessing pipeline can be set up with just 10-20 lines of code using the NVTabular high-level API.
Later in this section, we provide a concrete working example on the Criteo Terabyte dataset, which contains ~1.3 TB of uncompressed click logs containing over four billion samples spanning 24 days. Each record contains 40 features: one label indicating a click or no click, 13 numerical figures, and 26 categorical features.
While datasets of this scale are rarely available to the public, this dataset offers a glimpse into the scale of real enterprise data. Yet, real datasets can be much larger, as enterprises try to leverage as much historical data as feasible to achieve higher accuracy.
Common preprocessing steps on this dataset include the following:
- Continuous features: Imputing missing values (with 0) and optionally creating an additional feature indicating missing values in the original feature, log transforming, followed by normalizing the feature to have zero mean and standard deviation of 1.
- Categorical features: Encoding categorical features into continuous integer values if the category occurs more often than the specified threshold. Infrequent categories are mapped to a special ‘unknown’ category.
The actual code required to achieve this preprocessing pipeline is detailed in the following code example with just a dozen lines of code using NVTabular. In comparison, the custom-built, NumPy-based preprocessing code in Facebook’s DLRM framework is more than 300 lines of code for the same pipeline.
- We specify continuous and categorical columns.
- We define a NVTabular workflow and supply a set of train and validation files.
- We add preprocessing operations to the workflow.
- We execute by saving the processed data to disk.
import nvtabular as nvt
import glob
cont_names = ["I"+str(x) for x in range(1, 14)] # specify continuous feature names
cat_names = ["C"+str(x) for x in range(1, 27)] # specify categorical feature names
label_names = ["label"] # specify target feature
columns = label_names + cat_names + cont_names # all feature names
# initialize workflow
proc = nvt.Worfklow(cat_names=cat_names, cont_names=cont_names, label_name=label_names)
# create datsets from input files
train_files = glob.glob("./dataset/train/*.parquet")
valid_files = glob.glob("./dataset/valid/*.parquet")
train_dataset = nvt.dataset(train_files, gpu_memory_frac=0.1)
valid_dataset = nvt.dataset(valid_files, gpu_memory_frac=0.1)
# add feature engineering and preprocessing ops to workflow
proc.add_cont_feature([nvt.ops.ZeroFill(), nvt.ops.LogOp()])
proc.add_cont_preprocess(nvt.ops.Normalize())
proc.add_cat_preprocess(nvt.ops.Categorify(use_frequency=True, freq_threshold=15))
# compute statistics, transform data, export to disk
proc.apply(train_dataset, shuffle=True, output_path="./processed_data/train", num_out_files=len(train_files))
proc.apply(valid_dataset, shuffle=False, output_path="./processed_data/valid", num_out_files=len(valid_files)
Benchmarking results
Figure 3 shows the relative performance of NVTabular to the original DLRM preprocessing script, and a Spark-optimized ETL process running on a single node cluster. Of note is the percentage of time taken up by training compared to the time taken in ETL. In the baseline cases, the ratio of ETL to training almost exactly matches the common adage that data scientists spend 75% of their time processing the data. With NVTabular, that relationship is flipped.
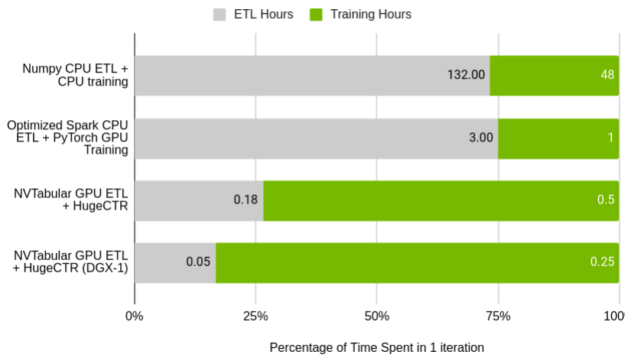
GPU (Tesla V100 32 GB) vs. CPU (AWS r5d.24xl, 96 cores, 768 GB RAM)
The total time taken to process the dataset and train the model on a CPU is over a week using the original script. With significant effort, that can be reduced to four hours using Spark for ETL and training on a GPU.
With NVTabular and NVIDIA HugeCTR, you can accelerate iteration time to 40 minutes for a single GPU and 18 minutes on a DGX-1 server with 8X V100 32 GB GPUs. In the latter case, the four-billion interaction dataset is processed in only three minutes.
Call to action
NVTabular is provided as an open source toolkit in the NVIDIA/NVTabular GitHub repo. We provide a Docker image on NVIDIA NGC and example scripts and Jupyter notebooks on popular public datasets such as Criteo Terabyte, which allows you to get NVTabular up and running in minutes.
NVTabular forms part of NVIDIA NVIDIA Merlin, a framework for building high-performance, deep learning-based recommender systems. For more information, see Announcing NVIDIA Merlin: An Application Framework for Deep Recommender Systems.
This is just the beginning of an exciting journey. We cordially invite you to try out and benefit from these newly developed tools for your recommender system applications. Your issues and feature requests will help guide future development.
