
Federated learning is revolutionizing the development of autonomous vehicles (AVs), particularly in cross-country scenarios where diverse data sources and conditions are crucial. Unlike traditional machine learning methods that require centralized data storage, federated learning enables AVs to collaboratively train algorithms using locally collected data while keeping the data decentralized. This approach enhances privacy and security, as sensitive data never leaves the country, and improves the robustness of the models by incorporating a wide range of driving environments and situations.
Federated learning also helps address regulatory compliance and data movement restrictions, which are significant concerns in the global landscape. Different countries have varying regulations regarding data privacy and cross-border data transfers, making centralized data storage and processing challenging.
By enabling local data usage and minimizing the need for data movement, federated learning ensures that AVs can adhere to these regulations while still benefiting from a collective learning process. As AVs traverse different terrains, climates, and traffic regulations across countries, federated learning enables them to adapt and optimize their performance, ensuring safer and more reliable autonomous driving experiences
In this post, we describe our efforts to enable federated learning in AV cross-border training. We have developed an AV federated learning platform by using NVIDIA FLARE, an open-source federated learning framework. With this platform, we trained a global model with more than a dozen AV models by using data from several different countries. We describe our use cases, integration with existing ML training platforms, and our job UI interfaces, as well as the challenges we went through.
Motivation and use cases
The NVIDIA AV team operates globally, collecting data from diverse regions to advance our AV initiatives. To train our models—particularly for tasks such as object detection, parking, and sign detection—we must consider the complexity of handling data from multiple countries.
To develop separate AV models for each country, the approval processes multiply, increasing both costs and delays. With potentially dozens of distinct models, the burden of navigating regulatory approvals could become significant. Instead, a more efficient approach is to build a unified global model, provided that its performance meets or exceeds the metrics of individual country-specific models.
Another motivation for incorporating data from multiple countries is the opportunity to address rare use cases that may not be represented in every country. While a globally trained model may not always lead to significant improvements in overall performance metrics, it can enhance the model’s ability to handle uncommon scenarios effectively
Training a global model requires using diverse data sources. Traditionally, this would involve centralizing all data in a data lake and conducting training from a single location. However, this approach introduces several challenges. Synchronizing large volumes of multimodal sensor data is not only time-consuming but also expensive.
Strict data protection laws in various regions—such as China’s Personal Information Protection Law (PIPL), the European Union’s General Data Protection Regulation (GDPR) and AI Act, and similar regulations in Korea and elsewhere—strictly limit cross-border data transfers, further complicating centralized training.
To address these challenges, we’ve developed a federated learning platform built on NVIDIA FLARE. This platform enables us to train deep learning models on country-specific data without needing direct access to raw datasets, ensuring compliance with local regulations while maintaining data privacy. By federating the data, we can train global AV models effectively, combining insights from diverse regions while adhering to privacy and regulatory requirements.
AV federated learning deployment setup
The deployment consists of two federated learning clients and a central server. The clients run on different machine learning training systems, while the FL server is hosted on AWS in Japan. In addition, we maintain a development FL server instance in Hong Kong for testing and ongoing development.
Figure 1 shows the overall architecture.

AV federated learning platform
Our AV federated learning platform consists of many subsystems:
- Integration with existing AV machine learning training system (MegLev: NDAS)
- Job orchestration service
- Federated learning engine with NVIDIA FLARE
Integration with existing AV Training platform
One major challenge in the system setup is effectively integrating two distinct training systems: the local machine learning infrastructure (MAGLEV), which is unaware of NVFLARE, with its training infrastructure, called NDAS.
NDAS operates independently from the federated learning (FL) system, and because it is used by numerous teams within the NVIDIA AV division, transitioning the entire system to an FL framework is not feasible. We needed a solution to integrate these two systems.
To address this, we used the NVFLARE third-party integration feature, enabling local training to continue within the MAGLEV framework while transferring model parameters to the NVIDIA FLARE client. We optimized the model transfer process through multiple iterations, using both file-based parameter transfer (FilePipe) and TCP-based parameter transfer (CellPipe) with NVIDIA FLARE.

AV federated learning orchestration service
We developed a suite of front-end and back-end services aimed at streamlining the creation and monitoring of federated learning jobs. This system simplifies the user experience, enabling efficient initiation of jobs and seamless tracking of their progress.
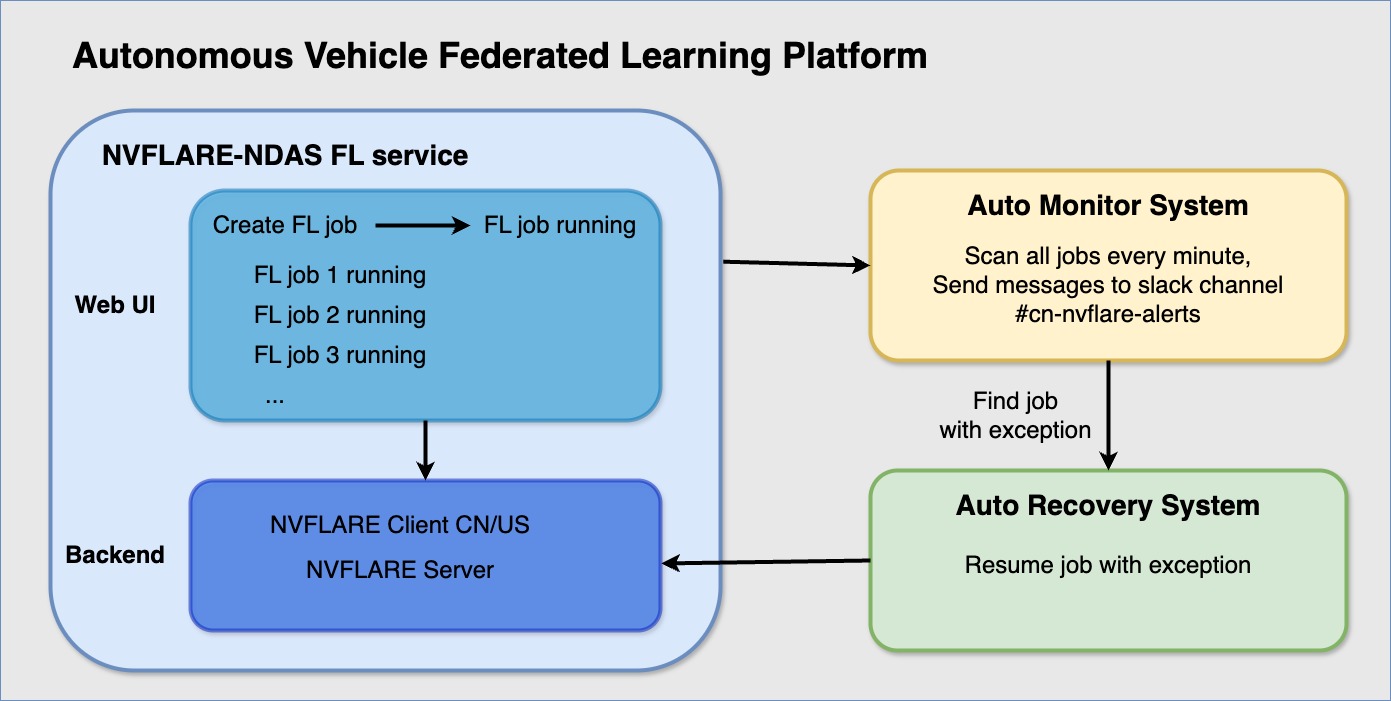
The system has been in stable production for over a year, with monitoring tools in place to track the performance. Figure 4 shows the monthly training model statistics across two instances, showcasing the consistency and scale of model training efforts.

Video 1 shows the job training process. It shows the AV-FL system web dashboard and how you can launch a training workflow with a few clicks.
Federated learning workflows
As we are working with AV sensor data for cross-border training, our workflow patterns differ significantly from those used in healthcare or mobile device federated learning:
- Healthcare and edge devices: Numerous clients, each with a limited amount of data.
- AV cross-border training: Fewer clients, each with a massive volume of data.
Given these differences, we can use various workflow patterns for model training. Based on our past experience, we chose the round-robin workflow, also known as cyclic weight transfer, as the initial approach. To prevent gradient conflicts, the server collects gradient updates from only one client at a time.

Challenges in cross-border training
The development and deployment of global AI models face significant challenges, which can hinder efficient cross-border training:
- IT setup
- Network bandwidth
- Network outages
IT setup
As the training data resides in an externally managed private cloud data center, each configuration change requires multiple approvals, complicating the process of opening ports or making necessary adjustments for NVFLARE.
To address this issue, we opted to host the FL server on the AWS public cloud. The FL client in the private cloud must communicate through a network path that connects to a community cloud before reaching the public AWS cloud. We used HTTPS port 443 along with a reverse proxy to manage the required ports.
Network bandwidth
Training can be slow due to multiple concurrent jobs and the large size of the models being transferred. In addition to expanding bandwidth, we are exploring opportunities to reduce bandwidth usage.
We identified an issue with model size inflation; for instance, a PyTorch model originally sized at 200 MB became significantly larger after server transfer. This was caused by the model being converted to NumPy and then back to a PyTorch model, resulting in the loss of PyTorch’s weight compression. To resolve this, we modified the algorithm to eliminate unnecessary conversions.
Network outages
Given the large data volumes, training sessions can last for days or weeks. We periodically encountered issues where certain client training jobs would terminate without any apparent reason, causing the server to wait indefinitely for their return. These sporadic occurrences made diagnosis challenging.
After analyzing logs with the NVFLARE team, we discovered that these failures were due to prolonged network outages lasting 5 to 10 minutes. The NVFLARE team implemented a mechanism to recover from temporary network outages and resume training. After this fix was applied, we experienced no unexplained job failures.
Project status
We successfully implemented the AV federated learning platform with the deployment of version 2.0, which has been in production for over a year. So far, we have trained and released a dozen AV models, most of which demonstrate equivalent or superior metrics compared to those trained locally.
The number of data scientists using this platform has increased significantly, growing from just 2 individuals a year ago to approximately 30 today.
As an example of how well models are performing, while the local model in the US can only predict the overall sign, the federated learning model is capable of identifying both the overall sign as well as the individual labels: 80 and 12 (Figure 6).

Here are some of the models trained using this platform:
- DoNET: A model that detects the status of vehicles, such as lamp status (whether the light is on or off) and door status (whether the door is open or closed).
- WaitNet: A model designed to detect static objects, including traffic lights, traffic signs, road markings, stop lines, and crosswalks.
- PathNet/RoadNet: A model that identifies the path the AV takes.
- RadarNet: A model that uses radar sensor data to predict obstacles around the vehicle.
- PredictionNet: A model for object tracking and trajectory prediction.
- EGM: A multi-camera input model for detecting barriers in parking lots, such as height limit poles and pillars.
Summary
Federated learning is a decentralized AI technology that enables model training without the need to move data. This approach not only ensures regulatory compliance but also helps minimize costs.
In this post, we discussed an AV-NVIDIA FLARE system that is designed for autonomous vehicles, highlighting its framework and solutions. These strategies can also be effectively applied to other industries.
For more information about federated learning, see the talks from NVIDIA FLARE Day, with speakers from multiple industries, including healthcare and finance.
