
AI-based computer vision (CV) applications are increasing, and are particularly important for extracting real-time insights from video feeds. This revolutionary technology empowers you to unlock valuable information that was once impossible to obtain without significant operator intervention, and provides new opportunities for innovation and problem-solving.
NVIDIA DeepStream SDK targets Intelligent Video Analytics (IVA) use cases that leverage machine learning (ML) to extract insights from video streams. It uses GPU acceleration for ML and accelerated hardware for maximum preprocessing performance when running on NVIDIA hardware.
This post explores the potential of combining Edge Impulse for model development with the NVIDIA DeepStream SDK for deployment so that you can rapidly create end-to-end applications. Edge Impulse is a member of the NVIDIA Inception program.
Computer vision applications
The ability to build complex, scalable CV applications rapidly is critical in today’s environment. Typical CV applications include diverse use cases such as vehicle identification, traffic measurement, inspection systems, quality control on production lines, safety and security enhancement through surveillance, smart checkout system implementation, and process measurement.
Integrating machine intelligence to analyze multimedia streams in business processes can add immense value. Thanks to unparalleled accuracy and reliability, machine intelligence can help streamline operations, resulting in increased efficiency.
Prebuilt AI models aren’t always the right solution and often require fine-tuning for a specific problem that prebuilt models don’t account for.
Building AI-based CV applications generally requires expertise in three skill sets: MLOps, CV application development, and deployment (DevOps). Without these specialized skills, the project ROI and delivery timeline could be at risk.
In the past, sophisticated CV applications required highly specialized developers. This translated to long learning curves and expensive resources.
The combination of Edge Impulse and the NVIDIA DeepStream SDK offers a user-friendly, complementary solution stack that helps developers quickly create IVA solutions. You can easily customize applications for a specific use case, integrating NVIDIA hardware directly into your solution.
DeepStream is free to use and Edge Impulse offers a free tier that suits many ML model-building use cases.
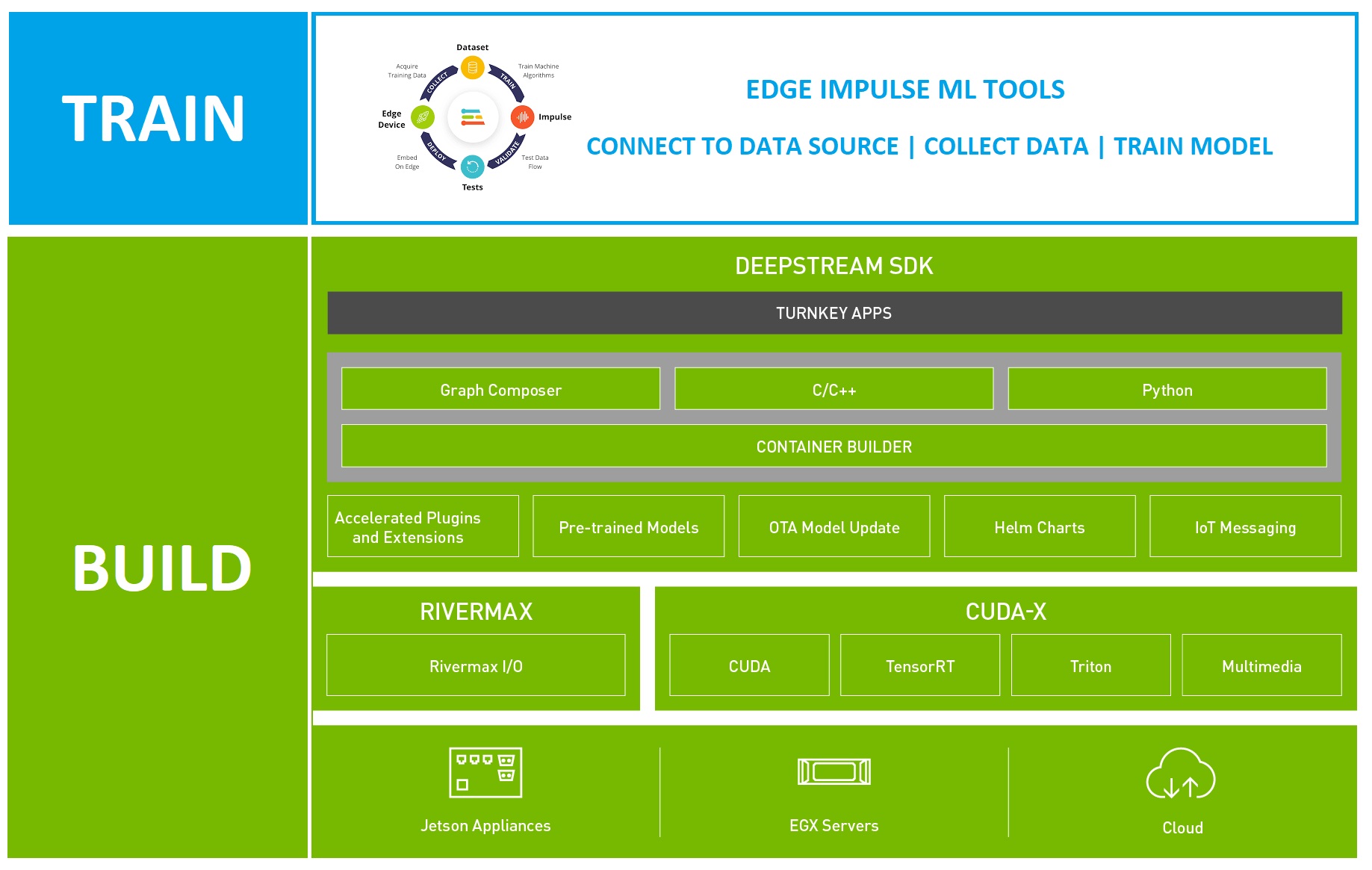
Building CV applications with NVIDIA DeepStream
Deepstream SDK is a component of NVIDIA Metropolis, which is designed to support video analytics at scale. You can quickly and easily create production-ready CV pipelines that can be deployed directly on NVIDIA hardware appliances.
DeepStream apps are built using the following approaches:
- From the command line
- Visually using Graph Composer
- Without code using the DeepStream reference application and config files
- With C++ or Python code for more customization
If you aren’t a developer, you can have a pipeline up and running using one of the first three options together with your trained ML model in less than an hour. If you need more customization, you can build a custom-coded solution from existing templates as a starting point.
Deploying CV applications
Once you have created your pipeline, it can be deployed directly on NVIDIA hardware appliances. These range from edge devices, like the NVIDIA Jetson Nano, to high-performance computing (HPC) and cloud deployments, and a hybrid approach.
You can deploy your application to run locally on NVIDIA edge hardware with your video source directly connected for minimal latency. If you need to handle complex pipelines or accommodate multiple video sources that exceed the capability of an NVIDIA edge appliance, you can deploy the same pipeline to an NVIDIA-based cloud instance on your preferred IaaS provider.
A hybrid approach is also possible, where the pipeline can be deployed to an NVIDIA edge appliance and inference can be performed remotely using NVIDIA Triton Inference Server.
Triton enables remote execution of models, receiving input frames from the client and serving back the results. Triton leverages NVIDIA GPUs when present and can also perform inference on x86 with support for concurrency and dynamic batching. Triton also has native support for most popular frameworks, including TensorFlow and PyTorch.
DeepStream supports Triton through an alternative to the Gst-nvinfer inference plugin called Gst-nvinferserver. This plugin enables you to use a Triton instance in a DeepStream application.
IVA applications are only as good as the ML models they are built around. While many pre built models are available, use cases often require customized models and MLOps workflows. This is where having an easy-to-use MLOps platform enables speedy deployments, especially when combined with DeepStream rapid application development.
Edge Impulse for machine learning
Edge Impulse offers a powerful suite of tools to build ML models that can be deployed directly onto NVIDIA targets and dropped into DeepStream applications. Seamlessly integrating with NVIDIA hardware acceleration and the DeepStream SDK, Edge Impulse helps you scale your projects quickly.
Edge Impulse guides developers at all levels throughout the process. Experienced ML professionals will appreciate the ease and convenience of bringing in data from different sources, as well as the end-to-end model-buildinging process. You can also integrate custom models with the custom learning blocks feature, which takes the heavy lifting out of MLOps.
For those new to machine learning, the Edge Impulse process guides you in building basic models as you use the environment. The basic model types you can use with DeepStream are YOLO object detection and classification.
You can also repurpose models built for tinyML targets so they work with edge use cases and the more powerful NVIDIA hardware. Many edge AI use cases involve complex applications that demand more powerful compute resources. NVIDIA hardware can help solve challenges associated with the limitations of constrained devices.
While you can create your own models from scratch with Edge Impulse, it also integrates with NVIDIA TAO Toolkit so you can leverage over 100 pretrained models in the Computer Vision Model Zoo. Edge Impulse complements TAO and can be used to adapt these models to custom applications. It is a great starting point for enterprise users.
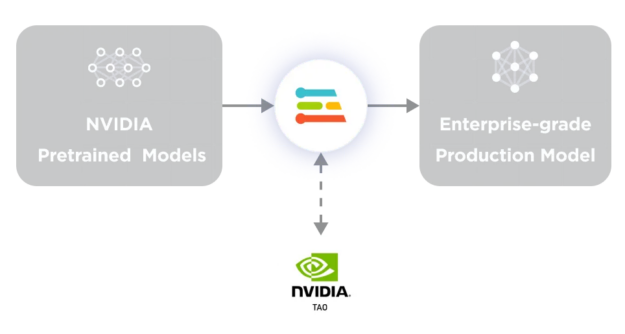
Building models for DeepStream with Edge Impulse
Once you are done building your model, deploy it into DeepStream. Export your model files from Edge Impulse and drop them into your DeepStream project. Then follow the configuration steps to ensure your Edge Impulse model works with DeepStream. The process generally involves four steps (Figure 3).

Step 1: Build model in Edge Impulse
Start by building either a YOLO or Image Classification model in Edge Impulse Studio. The DeepStream inference Gst-nvinfer plugin requires tensors to be in NCHW format for the input layer. Be sure to select Jetson Nano as the target and use FP32 weights.
Step 2: Export model from Edge Impulse
Edge Impulse can export models from the Dashboard page in Edge Impulse Studio. YOLOv5 can be exported as an ONNX with an NCHW input layer ready for use with DeepStream.

An IVA pipeline in DeepStream typically consists of a primary inference (PGIE) step that performs object detection with the bounding box coordinates. Associated object classes are passed to a secondary inference step (SGIE) that classifies each object. Each is implemented as an instance of the Gst-nvinfer plugin.
Step 3: Convert model to DeepStream compatible ONNX
When using YOLO with DeepStream, a custom output layer parser is required to extract the bounding boxes and object classes from the output layers that are then passed to the next plugin. For more details about the custom YOLO output parser, see How to Use the Custom YOLO Model.
Edge Impulse uses YOLOv5, which is a more recent, higher performance model, and has a slightly different output tensor format than YOLOv3. YOLOv3 has three output layers, each responsible for detecting objects at different scales, whereas YOLOv5 has a single output layer that uses anchor boxes to handle objects of various sizes.
DeepStream is based on GStreamer, which was designed for multimedia use cases. NVIDIA has added features to support deep learning within a GStreamer pipeline, including additional ML-related metadata which is passed down the pipeline with Gst-Buffer and encapsulated in the NvDsBatchMeta structures with Gst-Buffer.
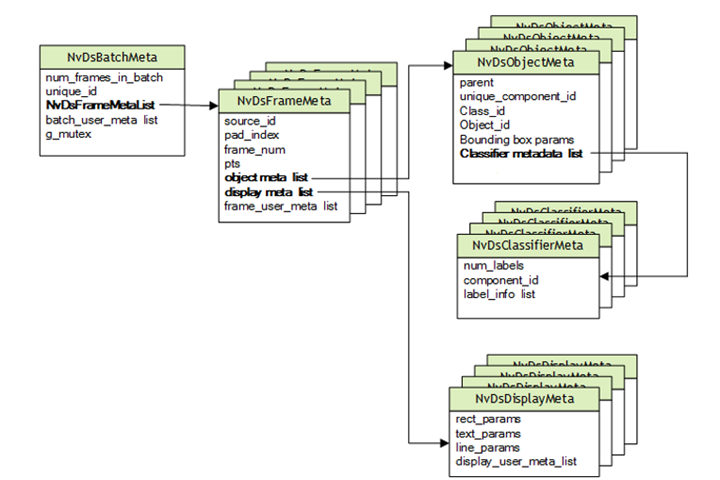
The output tensor from YOLO is different from the bounding box data required by DeepStream which is held in NvDsObjectMeta. To use YOLO with DeepStream, a custom output parser is needed to transform YOLO output to meet NvDsObjectMeta’s requirements at run-time. NVIDIA provides a sample plugin that works through YOLOv3.
Edge Impulse uses YOLOv5. The differences between the output layers of YOLOv3 and YOLOv5 make YOLOv3 plugin unsuitable for use with YOLOv5 (Figure 6).
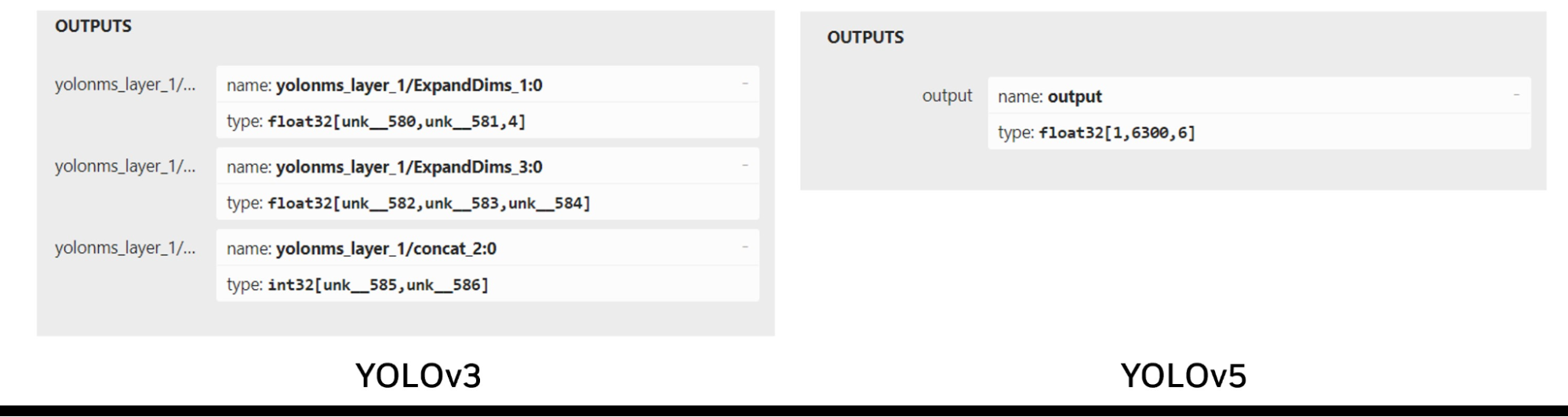
To use the YOLOv5 model trained in Edge Impulse, a custom YOLOv5 output parser must be created to process the single output tensor. One implementation that can be used is a third-party output parser that works with the Edge Impulse ONNX exports.
For Image Classification models, the default TFLite Float32 provided by Edge Impulse in NHWC format and its input layer need to be converted to NCHW.
This is easily achieved using the following tf2onnx command:
python -m tf2onnx.convert --inputs-as-nchw serving_default_x:0 --opset 13 --tflite MODELFILE --output OUTPUT.ONNX
MODELFILE is the input file and OUTPUT.ONNX is the output file that specifies the input layer name generated by Edge Impulse as serving_default_x:0. As a result, the input layer is transformed to meet DeepStream requirements.

Step 4: Create inference plugin configuration file
DeepStream requires the creation of plain text configuration files for each instance of the Gst-nvinfer plugin to specify runtime requirements. This includes the ONNX model file or generated TRT Engine file and the text file containing the label names. Figure 9 shows the minimum set of parameters required to use the Edge Impulse YOLOv5 and classification models.

Note that, although comments are shown inline with parameters for illustrative purposes, all configuration parameters should be separated into new lines.
The process-mode parameter can be used to specify whether the plugin is a primary or secondary stage. Note that the ONNX file is specified and DeepStream uses trtexec to generate the TensorRT Engine that NVIDIA TensorRT executes on NVIDIA GPUs.
After creating the engine, specify it using the model-engine-file parameter. The model-file parameter can be commented out to prevent the engine from being recreated on each run, thereby saving on startup time.
Depending on the model-color-mode (whether the model is RGB or grayscale), the parameter must be set to 0 or 2, respectively. This will correspond to the color depth set in Edge Impulse Studio.
The preceding example shows how the model used as the primary inference plugin. The model can also be used as the second-stage classifier by setting the process-mode property as follows:
process-mode=2 #SGIE
The example in Figure 9 also shows the minimal configuration files needed for a two-stage pipeline where the YOLO model first detects objects, then individually classifies them in the second stage classifier. For the YOLO model, the default YOLO label file can be edited and the labels replaced with labels from the custom model with each label on a new line, per the YOLO standard format.
In the case of the classification model, labels are separated by semicolons. During run time, the models will be indexed accordingly from these files and the text you specify will be displayed.
DeepStream can be used by referencing the configuration files in your pipeline that have these settings embedded.
Conclusion
This post has explained how to leverage Edge Impulse and NVIDIA DeepStream SDK to quickly create HPC vision applications. These applications include vehicle identification, traffic measurement, inspection systems, quality control on production lines, safety and security enhancement through surveillance, smart checkout system implementation, and process measurement. New use cases for AI and IVA are continually emerging.
To learn more about DeepStream, see Get Started With the NVIDIA DeepStream SDK. To get started with Edge Impulse and DeepStream, see Using Edge Impulse with NVIDIA DeepStream. This guide includes a link to a repository with a preconfigured DeepStream pipeline that you can use to validate performance or develop your own pipeline. A precompiled custom parser for the Jetson Nano architecture is also included to help you get started.
