When I joined the RAPIDS team in 2018, NVIDIA CUDA device memory allocation was a performance problem. RAPIDS cuDF allocates and deallocates memory at high frequency, because its APIs generally create new Series and DataFrames rather than modifying them in place. The overhead of cudaMalloc and synchronization of cudaFree was holding RAPIDS back. My first task for RAPIDS was to help with this problem, so I created a rough prototype RAPIDS memory management library, RMM, that provided C++ and Python APIs wrapping an existing open-source CUDA memory allocator called CNMeM. RMM had much better performance than the CUDA default, cudaMalloc and cudaFree.
We were preparing the RAPIDS launch demo for GTC Europe 2018 in Munich. In typical NVIDIA style, not only did we have to run a large-scale data analytics demo live and faster than ever, but we had to do it on brand new hardware to which we were only just getting access. When we ran and profiled the workflow on NVIDIA DGX-2, with its 16 Tesla V100 GPUs, the mortgage data analysis notebook that we were running was completely bottlenecked by calls to cudaMalloc and cudaFree.
There are several reasons for this. First, cudaMalloc and cudaFree have a lot of overhead. Also, cudaFree synchronizes the entire device on each call and cudaMalloc must register each allocation with all peer GPUs in case code running on them accesses the memory over NVLink or PCIe. This P2P registration overhead scales quadratically with the number of GPUs; going from eight GPUs in DGX-1 to 16 in DGX-2 quadrupled the P2P registration overhead. The RAPIDS mortgage analysis launch demo was spending 90% of its time in memory allocation and deallocation.
We centralized memory management in cuDF by replacing all calls to cudaMalloc and cudaFree with RMM allocations. This was a lot of work, but it paid off. RMM calls are on the order of 1,000 times faster than cudaMalloc and cudaFree. The result was a 10x speedup for the mortgage demo. With the hard work of our team on the rest of cuDF and cuML for the demo, the RAPIDS launch was a success.
Since that time, and with the help of our great team, RMM has evolved into a scalable, open source, standards-based allocator interface that can support the entire RAPIDS ecosystem and beyond. Later in this post, I show how to use RMM with the GPU-accelerated CuPy and Numba Python libraries. The RMM high-performance memory management API is designed to be useful for any CUDA-accelerated C++ or Python application. It is starting to see use in (and contributions from!) HPC codes like the Plasma Simulation Code (PSC).
A common interface
Memory management in RAPIDS mirrors the experience of other GPU-accelerated library and application developers. Achieving optimal performance in GPU-centric workflows often requires customizing how host and device memory are allocated. For example, you could use “pinned” host memory for asynchronous host-to-device memory transfers or a device memory pool suballocator to reduce the cost of dynamic device memory allocation. Furthermore, memory diagnostics, logging, leak detection, profiling, and debugging support are invaluable in complex workflows. All these customizations benefit from a common memory allocation interface.
The goal of RMM is to provide fast and flexible memory management through the following features:
- A common interface that allows customizing device and host memory allocation
- A collection of implementations of the interface
- A collection of data structures that use the interface for memory allocation
RMM provides a common memory allocation interface that is used across RAPIDS libraries, such as cuDF, cuML, cuGraph, and cuSpatial; Python data ecosystem libraries such as CuPy and Numba; and even other libraries outside the RAPIDS ecosystem.
Memory resources
The primary interface to memory allocation in RMM is through memory resources (MR). An RMM device MR is an object that provides two core methods: allocate and deallocate. All RMM MRs are derived from the abstract base class rmm::mr::device_memory_resource. This simple design is extremely powerful: combined with C++ polymorphism, it enables layered customization of memory allocation.
Credit for the design of the RMM MR interface goes to Jake Hemstad, who borrowed heavily from a feature of C++17 called std::pmr::memory_resource. RMM currently provides two kinds of MRs: device and host. In this post I focus on device MRs, as they are more commonly used. For more information, see the Host Memory Resources section in the GitHub repo readme file.
Device memory resources
The rmm::mr::device_memory_resource class is an abstract base class that defines the interface for allocating and freeing device memory in RMM. It has two key functions:
void* device_memory_resource::allocate(std::size_t bytes, cuda_stream_view s)—Returns a pointer to an allocation of the requested size in bytes.void device_memory_resource::deallocate(void* p, std::size_t bytes, cuda_stream_view s)—Reclaims a previous allocation of size bytes pointed to byp. The pointerpmust have been returned by a previous call toallocate(bytes); otherwise, the behavior is undefined.
These functions are pure virtual functions, meaning that it is up to another class that derives from device_memory_resource to provide the implementation. For example, cuda_memory_resource is a derived class that implements allocate and deallocate using cudaMalloc and cudaFree, respectively. For more information about additional examples of device_memory_resource derived classes, see the Available Resources section in the GitHub repo readme file. The cuda_stream_view object used earlier is an RMM wrapper class around a CUDA stream.
Polymorphism enables customization
Through dynamic polymorphism in C++, the device_memory_resource abstract base class allows for infinite possibilities in customizing device memory allocation. This means that any custom-derived MR object can be passed to a function that takes a pointer or reference to a device_memory_resource object.
class my_custom_resource : public device_memory_resource {
/* implement do_allocate and do_deallocate */
};
void foo(..., rmm::mr::device_memory_resource * mr);
my_custom_resource mine{...};
foo(..., &mine);
The power of this pattern can be seen in RMM support for layering memory resources. Many RMM memory resources take a device_memory_resource pointer to an “upstream” memory resource as a constructor argument. These resources call into that upstream resource to perform allocation/deallocation, and then layer some other behavior on top. For example, a logging_memory_resource uses its upstream resource for the actual allocation, and then writes information about the allocation (timestamp, size, pointer, thread ID, stream) to a log file. A pool_memory_resource uses its upstream resource to allocate large chunks of memory (a pool) from which it then sub-allocates. A tracking_memory_resource keeps track of all outstanding allocations, along with an optional call stack of their allocation location for use in pinpointing the source of memory leaks. Many of these can be layered. For example, we can create a tracking pool memory resource with logging. Read on to find out more about layering resources and adaptors.
Stream-ordered memory allocation
You may have noticed that rmm::mr::device_memory_resource::allocate and deallocate require a stream parameter. This is because device MRs implement stream-ordered memory allocation. This is an extension of the CUDA stream programming model to include allocation and deallocation of device memory as stream-ordered operations, just like kernel launches and asynchronous memory copies. Stream-ordered memory allocation solves some of the synchronization performance problems experienced with cudaMalloc and cudaFree. It also allows optimizations such as re-using memory deallocated on the same stream without the overhead of synchronization. The key is using a stream parameter to tell the allocator where the memory is being used.
The rules are simple:
- A call to
device_memory_resource::allocate(bytes, stream_a)returns a pointer that is valid to use immediately onstream_a. - Specifying
stream_btodevice_memory_resource::deallocate(pointer, bytes, stream_b)indicates that it is valid to reuse that deallocated memory immediately for another allocation onstream_b.
Using the memory returned by allocate(bytes, stream_a) on a different stream than specified (for example, stream_b) is undefined behavior unless the two streams are first synchronized. For example, you could use cudaStreamSynchronize(stream_a) or record a CUDA event e on stream_a and then call cudaStreamWaitEvent(stream_b, e). The stream passed to deallocate is typically the stream on which the allocation was last used before the call to deallocate.
The cudaMalloc and cudaFree functions do not require stream parameters, because they are not stream-ordered. Because the memory passed to cudaFree may still be in use asynchronously at the time of the call, the CUDA runtime must be conservative and so it effectively synchronizes the whole device. Stream-ordered allocation solves this problem, because when you indicate the stream on which the memory may be still in use, the allocator knows that it can reuse that memory on the same stream safely. The allocator also knows that if it must allocate the same memory to a request on a different stream, it must wait on the stream on which the memory was deallocated.
RMM device memory data structures, such as rmm::device_buffer and rmm::device_uvector, follow these stream-ordered memory allocation semantics and rules.
Suballocation in RMM
RMM achieves high performance primarily through suballocation. A suballocator allocates a large chunk of memory from the underlying system (in this case, the CUDA driver), and then subdivides it into smaller pieces to service allocations from the application. Most high-performance allocators work this way. There are probably as many approaches to allocation as there are applications, because different applications have different allocation patterns. This is a key motivation for the flexible allocator interface in RMM, to enable easy customization of suballocation algorithms. RMM currently has a few device MRs that implement different suballocation approaches.
The pool_memory_resource class implements a coalescing suballocator that uses a pool of memory allocated from an upstream MR. Coalescing means that when blocks of memory are freed, they are combined with any contiguous free memory to reduce fragmentation. Typically, the upstream MR is an instance of cuda_memory_resource, which just passes through to cudaMalloc. The pool resource is designed to minimize synchronization, so it maintains separate free lists for each stream that is passed to its deallocate method. As described in the later section on stream-ordered allocation, this allows it to allocate previously freed memory blocks on the same stream without synchronizing. If a sufficient block is not available in the allocating stream’s free list, it can search other streams’ free lists. If a block is found in a free list associated with a different stream, the requesting stream must wait on an event recorded in the stream on which the block was deallocated.
In some applications, there are many small allocations, which can lead to a high number of outstanding allocations and a high deallocation cost, as well as increased fragmentation. The binning_memory_resource class implements a hybrid allocator that uses one or more fixed_size_memory_resource object to allocate small blocks and only uses its upstream MR for large allocations. The fixed_size_memory_resource class implements constant-time allocation for memory blocks of a single size.
In multithreaded applications, it’s common to use CUDA per-thread default streams as a non-invasive way to enable concurrency between kernels and device memory copies launched in different threads. However, maintaining separate free lists for many streams can result in memory fragmentation problems. The arena_memory_resource class is designed to carve out a small pool for each thread to use for small allocations, while sharing a pool for large allocations. This can often result in lower fragmentation in multi-stream use cases.
As you can see, the flexibility of the device_memory_resource design pays off when it comes to the need to adapt memory suballocation to different memory usage patterns.
RMM performance
RMM suballocator MRs provide orders-of-magnitude higher performance than direct allocation and deallocation using cudaMalloc and cudaFree. Because there are many allocation patterns, there are many ways to benchmark allocators. It is important to benchmark non-trivial allocation patterns, because these stress things like the data structures and algorithms used to select from available free blocks and to coalesce blocks when freeing memory.
RMM includes a benchmark that performs random allocations. It performs N allocations and deallocations, choosing a random size within a specified range (0 to M bytes) for each allocation. When freeing, it chooses the memory to free randomly as well, so that memory is not freed in the order in which it is allocated. While a random size and ordering does not necessarily reflect most real allocations, it does stress the allocator. The following graphs show the results of the random allocation benchmark using four different RMM MRs:
pool_memory_resourcebinning_memory_resourcearena_memory_resourcecuda_memory_resource
Because cuda_memory_resource is just a thin wrapper around cudaMalloc and cudaFree, this is a good demonstration of the level of speedup that RMM can provide. The benchmarks in this section were run on an Ubuntu 18.04 PC with CUDA 11.0, an NVIDIA Quadro V100 GPU with 32 GiB of RAM, and an AMD Ryzen 7 3700X CPU.
Figure 2 shows the running time of these MRs for 1,000 random allocations and frees. This was run with various values for the maximum allocation size M, from 1 MiB up to 4 GiB. The y-axis is logarithmic, which means that the cost of allocation using cudaMalloc and cudaFree scales exponentially with the size of the allocation, while the cost of RMM MRs scales linearly. The result is that suballocation can be several orders of magnitude faster than cudaMalloc and cudaFree.
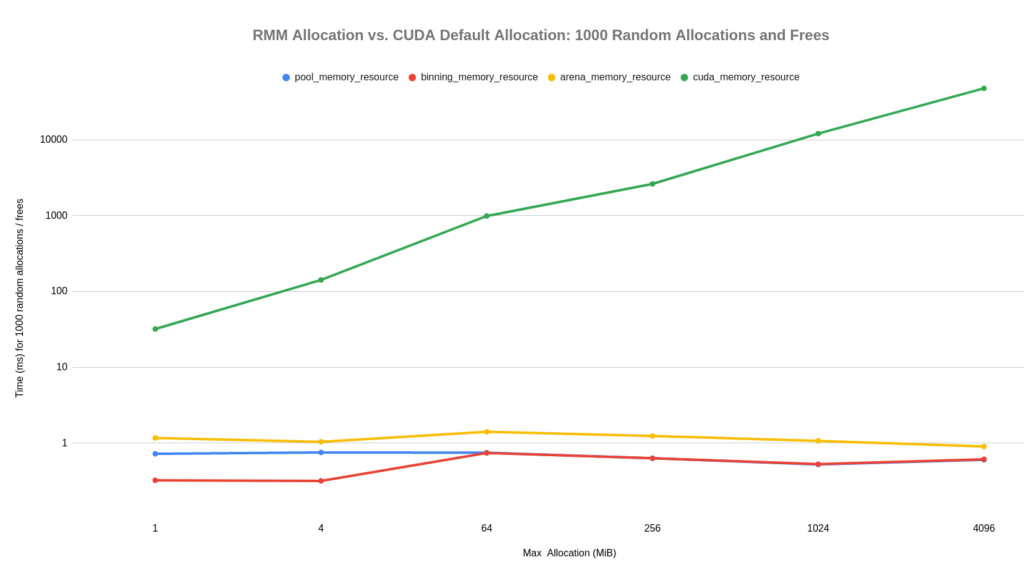
Pool allocation, with pool_memory_resource, generally costs less than a microsecond per allocation and free, and arena_memory_resource is competitive and suffers less from fragmentation in multithreaded applications. The binning_memory_resource provides fast constant-time allocation for small sizes, and switches over to pool allocation for requests of 64 MiB or larger. Therefore, it matches pool_memory_resource performance for larger sizes.
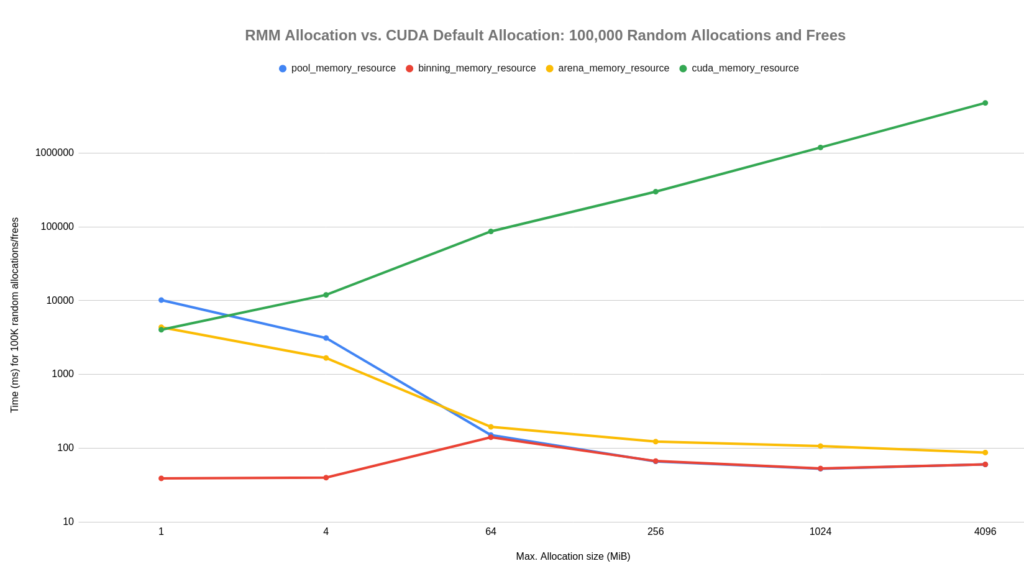
Figure 3 shows the results for 100,000 random allocations and frees. You can see that this two-orders-of-magnitude jump has a large effect on pool allocation with a small maximum allocation size. This is because the number of active allocations can grow much larger, requiring more expensive searches (\(O(\log{}N)\)) when deallocating. The binning_memory_resource helps this case, because the many small allocations are much faster and have constant time cost, rather than a cost proportional to the number of allocations.
Data structures and thrust support
Most C++ developers are used to using container data structures such as std::vector to hold data, so RMM provides a number of data structures to make development easier. Like std::vector, RMM data structures provide RAII semantics. RAII is a common C++ term for “Resource acquisition is initialization,” which is a complicated way of saying that the resources owned by an object are cleaned up by its destructor when it goes out of scope.
Untyped device buffers
The rmm::device_buffer class is a simple, untyped, uninitialized class for stream-ordered device memory allocation. The following example allocates 100 bytes of device memory on stream s and fills the buffer in the CUDA kernel kernel_1, also on stream s. The device_buffer object is deleted when it goes out of scope, and its memory is deallocated on the stream on which it was allocated.
cuda_stream_view s{...};
// Allocates at least 100 bytes on stream `s` using the *default* resource
rmm::device_buffer b{100,s};
void* p = b.data(); // Raw, untyped pointer to device memory
kernel_1<<<..., s.value()>>>(p); // `b` is safe to use on `s`
You can specify an MR to use for allocating the device memory owned by a device_buffer object using an optional MR constructor parameter, as in the following example.
// my_custom_resource is derived from `rmm::device_memory_resource`
my_custom_resource mr{...};
// Allocates at least 100 bytes on stream `s` using mr
rmm::device_buffer b2{100, s, &mr};
Typed device vectors
rmm::device_vector is an alias for thrust::device_vector that uses the RMM current device resource for its allocation. Thrust is an open-source CUDA C++ parallel algorithms library included in the CUDA toolkit, and thrust::device_vector is a typed vector container that works much like std::vector, except that it is backed by CUDA device memory. RMM may provide a stream-ordered equivalent to thrust::device_vector in the future.
// Allocates at least 100 bytes on stream `s` using the *default*
// resource and *default* stream
rmm::device_vector<int> v{100};
int* p = v.data(); // typed pointer to device memory
// Data in `v` is safe to access on default stream
kernel_2<<<..., rmm::cuda_stream_default()>>>(p);
Typed, uninitialized device vectors
rmm::device_uvector<T> is a typed, uninitialized RAII class for stream-ordered allocation of a contiguous set of elements in device memory. It’s common to create a device_vector to store the output of a Thrust algorithm or CUDA kernel. But device_vector is always default-initialized, just like std::vector. This default initialization incurs a CUDA kernel launch and an expensive cudaDeviceSynchronize(). device_uvector<T> is similar to a thrust::device_vector<T>, but as an optimization, it does not default initialize the contained elements, which can significantly reduce overhead in some situations. This optimization restricts the types T that can be stored in this container to trivially copyable types. device_uvector<T> is also fully stream ordered, so many of its methods take a stream parameter.
cuda_stream_view s{...};
// Allocate uninitialized storage for 100 `int32_t` elements on stream `s` using the default resource
rmm::device_uvector<int32_t> v(100, s);
// Initialize the elements to 0
thrust::uninitialized_fill(thrust::cuda::par.on(s.value()), v.begin(), v.end(), int32_t{0});
// Allocate uninitialized storage for 100 `int32_t` elements on
// stream `s` using the explicitly provided resource
my_custom_resource mr{...};
rmm::device_uvector<int32_t> v2(100, s, &mr);
Typed device scalars
rmm::device_scalar<T> is a typed, RAII class for stream-ordered allocation of a single element in device memory. This is similar to a device_uvector with a single element but provides convenience functions for modifying the value in device memory from the host and retrieving the value from device to host.
cuda_stream_view s{...};
// Allocate uninitialized storage for a single `int32_t` in
// device memory on stream `s`
rmm::device_scalar<int32_t> a{s};
// Update the value in device memory to `42` on stream `s`
a.set_value(42, s);
// Pass raw pointer to underlying element in device memory to `kernel`
kernel<<<...,s.value()>>>(a.data());
// Retrieve the value from device to host on stream `s`
int32_t v = a.value(s);
CUDA stream support
rmm::cuda_stream_view (seen in the earlier examples), is a simple non-owning wrapper around a CUDA cudaStream_t. This wrapper’s purpose is to provide strong type safety for stream types and mitigate the potential ambiguity of cudaStream_t and literal stream identifiers. All RMM stream-ordered APIs take a rmm::cuda_stream_view argument.
rmm::cuda_stream is a simple owning wrapper around a CUDA cudaStream_t. This class provides RAII semantics (constructor creates the CUDA stream; destructor destroys it). An instance of rmm::cuda_stream always represents a single non-default stream; it cannot represent the CUDA default stream or per-thread default stream (RMM provides rmm::cuda_stream_default and rmm::cuda_stream_per_thread to access those).
Resource adaptors: Logging and replay, limiting and tracking
While performance is an obvious benefit of a flexible allocator interface, the composition it enables delivers further benefits. RMM memory resource adaptors add “meta” capabilities on top of allocation and deallocation, including logging, limiting allocation sizes, and tracking.
Memory event logging
Memory event logging writes details of every allocation or deallocation to a CSV (comma-separated value) file. Each row in the log represents either an allocation or a deallocation along with information such as the thread id, (de)allocation size, and stream. It can be analyzed with any tool that can import CSV or used as input to REPLAY_BENCHMARK, available when building RMM from source. This log replayer can be useful for profiling and debugging allocator issues.
In C++, enable memory event logging by using rmm::logging_resource_adaptor as a wrapper around any other device_memory_resource object. In Python, enable memory event logging by setting the logging parameter of rmm.reinitialize to True. The log file name can be set using the log_file_name parameter. For more information, see the Memory Event Logging and logging_resource_adaptor section in the GitHub readme file.
RMM also provides debug logging for low-level runtime diagnostics. For more information, see the Debug Logging section in the GitHub readme file.
Limiting and tracking memory usage
The rmm::mr::limiting_resource_adaptor class adapts a wrapped MR to limit the maximum amount of memory that it may allocate. For example, to create a rmm::mr::managed_memory_resource that is limited to at most 32 MiB of allocations, use the following C++ code.
auto cuda_mr = rmm::mr::managed_memory_resource;
auto limited_cuda_mr =
rmm::mr::limiting_resource_adaptor{&cuda_mr, 1 << 25};
The tracking resource adaptor tracks all outstanding allocations made to its wrapped resource, optionally with a call stack to the points of allocation. This is useful for leak detection. At any point, you can query tracking_resource_adaptor to get a list of all outstanding allocations. For instance, you could check this at shutdown or after each unit test in a test suite to ensure that your library or application is not leaking device memory.
RMM Python API
So far, I’ve been talking about RMM in terms of its C++ classes and APIs, but RMM also provides a Python API that can be used to manage device memory for CUDA-accelerated Python libraries, such as Numba, CuPy, RAPIDS cuDF, cuML, and cuGraph. RMM is used as the memory manager for all RAPIDS libraries, and it provides plugins for CuPy and Numba.
There are two ways to use RMM in Python code:
- Using the
rmm.DeviceBufferAPI to explicitly create and manage device memory allocations. - Transparently, using external libraries such as CuPy and Numba.
RMM provides a MemoryResource abstraction to control how device memory is allocated in both cases.
DeviceBuffer objects
A DeviceBuffer object represents an untyped, uninitialized device memory allocation. It is the Python equivalent of the RMM C++ rmm::device_buffer data structure. DeviceBuffer objects can be created by providing the size of the allocation in bytes.
>>> import rmm >>> buf = rmm.DeviceBuffer(size=100)
You can access the size of the allocation and the memory address associated with it using the .size and .ptr attributes, respectively.
>>> buf.size 100 >>> buf.ptr 140202544726016
DeviceBuffer objects can also be created by copying data from host memory.
>>> import rmm >>> import numpy as np >>> a = np.array([1, 2, 3], dtype='float64') >>> buf = rmm.to_device(a.tobytes()) >>> buf.size 24
Conversely, the data underlying a DeviceBuffer object can be copied to the host.
>>> np.frombuffer(buf.tobytes()) array([1., 2., 3.])
MemoryResource objects
MemoryResource objects are used to configure how device memory allocations are made by RMM. By default, if a MemoryResource object is not set explicitly, RMM uses an instance of CudaMemoryResource, which uses cudaMalloc for allocating device memory using a rmm::cuda_memory_resource in C++.
The rmm.reinitialize function provides an easy way to (re-)initialize RMM with specific MR options across multiple devices. For more information, run help(rmm.reinitialize). For example, to enable using the PoolMemoryResource for higher performance, call rmm.reinitialize(pool_allocator=True) before making any calls to libraries that use RMM, such as RAPIDS cuDF.
For lower-level control, the rmm.mr.set_current_device_resource function can be used to set a different MemoryResource object for the current CUDA device. For example, passing it a ManagedMemoryResource object tells RMM to use cudaMallocManaged instead of cudaMalloc for allocating memory, using rmm::managed_memory_resource in C++.
>>> import rmm >>> rmm.mr.set_current_device_resource(rmm.mr.ManagedMemoryResource())
The following example shows how to construct a PoolMemoryResource with an initial size of 1 GiB and a maximum size of 4 GiB. The pool uses CudaMemoryResource as its underlying “upstream” MR.
>>> import rmm >>> pool = rmm.mr.PoolMemoryResource( ... upstream=rmm.mr.CudaMemoryResource(), ... initial_pool_size=2**30, ... maximum_pool_size=2**32 ... ) >>> rmm.mr.set_current_device_resource(pool)
Using RMM with CuPy
You can configure CuPy to use RMM for memory allocations by setting the CuPy CUDA allocator to rmm_cupy_allocator.
>>> import rmm >>> import cupy >>> cupy.cuda.set_allocator(rmm.rmm_cupy_allocator)
Using RMM with Numba
You can configure Numba to use RMM for memory allocations using the Numba EMM Plugin. This can be done in two ways.
The first way is setting the environment variable NUMBA_CUDA_MEMORY_MANAGER:
$ NUMBA_CUDA_MEMORY_MANAGER=rmm python (args)
The second way is using the set_memory_manager function provided by Numba:
>>> from numba import cuda >>> import rmm >>> cuda.set_memory_manager(rmm.RMMNumbaManager)
Importance of external allocator interfaces
RMM was created to solve a major memory allocation performance bottleneck experienced by RAPIDS, which is part of the larger accelerated data science ecosystem. This ecosystem and its applications and workflows rely on the interoperability between many libraries.
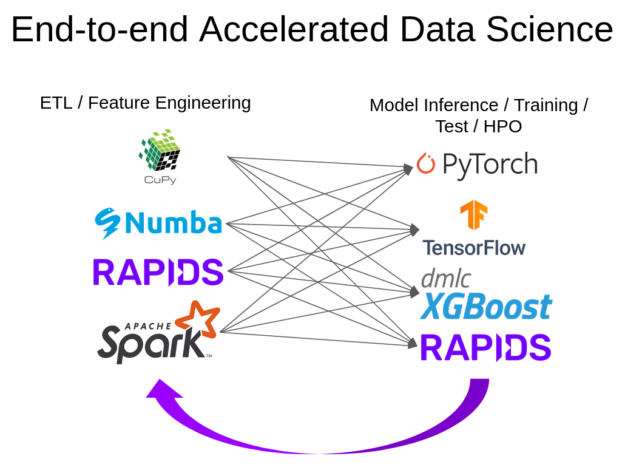
Many libraries have run into the same issues with CUDA memory allocation, and have solved them in similar ways, such as suballocation using pool allocators or caching allocators. However, when multiple libraries used by an application each maintain a memory pool, they end up competing for device memory rather than sharing it. This is because suballocators allocate more memory than is in use (the pool or cache) and hold onto it for the lifetime of the application. Applications can run out of memory when, for example, the RMM memory pool used by RAPIDS libraries is not shared with PyTorch, which has its own caching allocator. This is an ecosystem problem.
There is a solution: libraries need external allocator interfaces (EAIs). An EAI lets an application “plug in” an object that implements a memory allocation API required by the library. This is the key to enabling sharing of custom memory allocation between libraries in an application.
In this post, I have already shown two simple examples, cupy.cuda.set_allocator and Numba’s cuda.set_memory_manager. The objects passed to these APIs just need to implement a well-defined interface for allocation and deallocation requests. In fact, the EAI defined by every library need not be the same. A standard would provide convenience but is not required; what is important is that libraries provide an EAI to allow applications to override how memory is allocated. RMM implements the EAIs of CuPy and Numba, and it can implement future EAIs to enable sharing RMM allocators across a wider set of libraries. The RAPIDS team looks forward to popular deep learning frameworks and other libraries providing EAIs.
Fast and flexible CUDA memory management for your code
RMM is a powerful memory management library that was created for RAPIDs but is useful for much more. It provides composable MRs that can be used for high-performance memory allocation, logging, tracking, and more. RMM is easy to use in your own C++ and Python applications and libraries, so try it out today.
If you are using RAPIDS in Python, I encourage you to try out RMM pool allocation for higher performance in data analytics workflows. If you develop custom GPU-accelerated code in C++ or Python, you can also use RMM data structures and MRs in your own code.
- For more information about RAPIDS, see the Getting Started page on rapids.ai.
- For more information about RMM or to dive into using RMM in your own projects, see the rapidsai/rmm GitHub repo. Give it a star if you like it!
- Anaconda packages for Python RMM are available along with all other RAPIDS conda packages.
- Join the RAPIDS community conversations on Twitter, Google Groups, and Slack.
- Please let us know of any problems by filing GitHub issues.
