CUDA 13.2 Introduces Enhanced CUDA Tile Support and New Python Features
CUDA 13.2 arrives with a major update: NVIDIA CUDA Tile is now supported on devices of compute capability 8.X architectures (NVIDIA Ampere and NVIDIA Ada), as...
Accelerating Data Processing with NVIDIA Multi-Instance GPU and Locality Domains
NVIDIA flagship data center GPUs in the NVIDIA Ampere, NVIDIA Hopper, and NVIDIA Blackwell families all feature non-uniform memory access (NUMA) behaviors, but...
CUDA Pro Tip: Increase Performance with Vectorized Memory Access
Many CUDA kernels are bandwidth bound, and the increasing ratio of flops to bandwidth in new hardware results in more bandwidth bound kernels. This makes it...
Optimizing Memory and Retrieval for Graph Neural Networks with WholeGraph, Part 1
Graph neural networks (GNNs) have revolutionized machine learning for graph-structured data. Unlike traditional neural networks, GNNs are good at capturing...
Deploying Retrieval-Augmented Generation Applications on NVIDIA GH200 Delivers Accelerated Performance
Large language model (LLM) applications are essential in enhancing productivity across industries through natural language. However, their effectiveness is...
Simplifying GPU Application Development with Heterogeneous Memory Management
Heterogeneous Memory Management (HMM) is a CUDA memory management feature that extends the simplicity and productivity of the CUDA Unified Memory programming...
Boosting Application Performance with GPU Memory Access Tuning
NVIDIA GPUs have enormous compute power and typically must be fed data at high speed to deploy that power. That is possible, in principle, as GPUs also have...
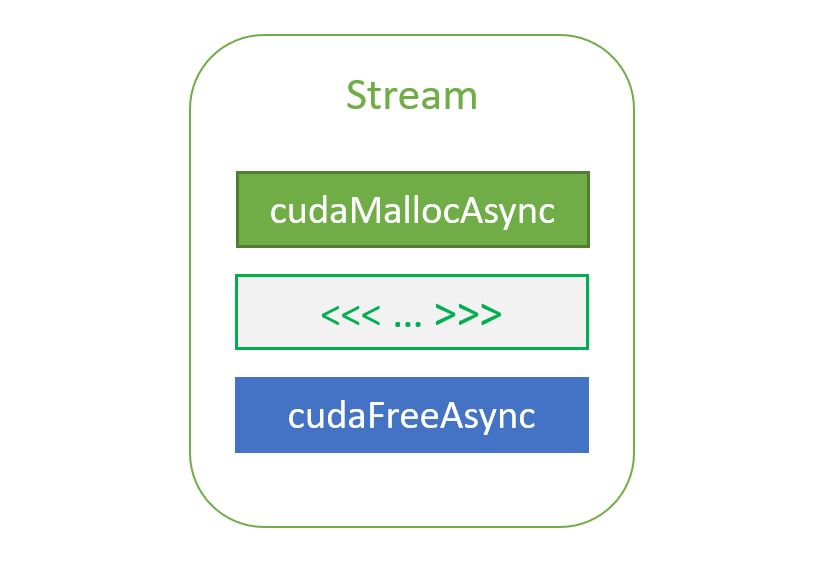
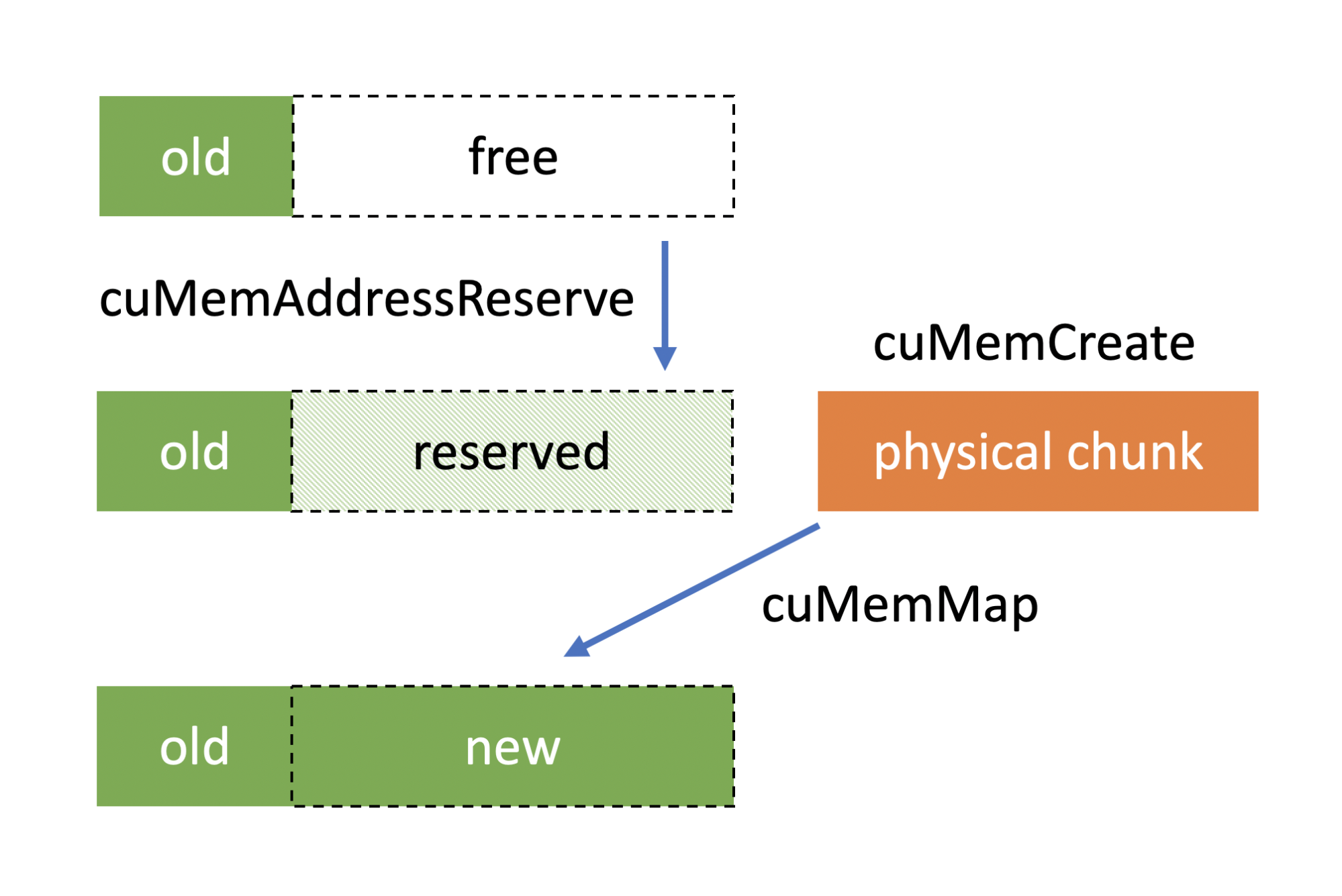
Using the NVIDIA CUDA Stream-Ordered Memory Allocator, Part 1
Most CUDA developers are familiar with the cudaMalloc and cudaFree API functions to allocate GPU accessible memory. However, there has long been an obstacle...
Reducing Acceleration Structure Memory with NVIDIA RTXMU
Acceleration structures spatially organize geometry to accelerate ray tracing traversal performance. When you create an acceleration structure, a conservative...
In ray tracing, more geometries can reside in the GPU memory than with the rasterization approach because rays may hit the geometries out of the view frustum....
Managing Memory for Acceleration Structures in DirectX Raytracing
In Microsoft Direct3D, anything that uses memory is considered a resource: textures, vertex buffers, index buffers, render targets, constant buffers,...
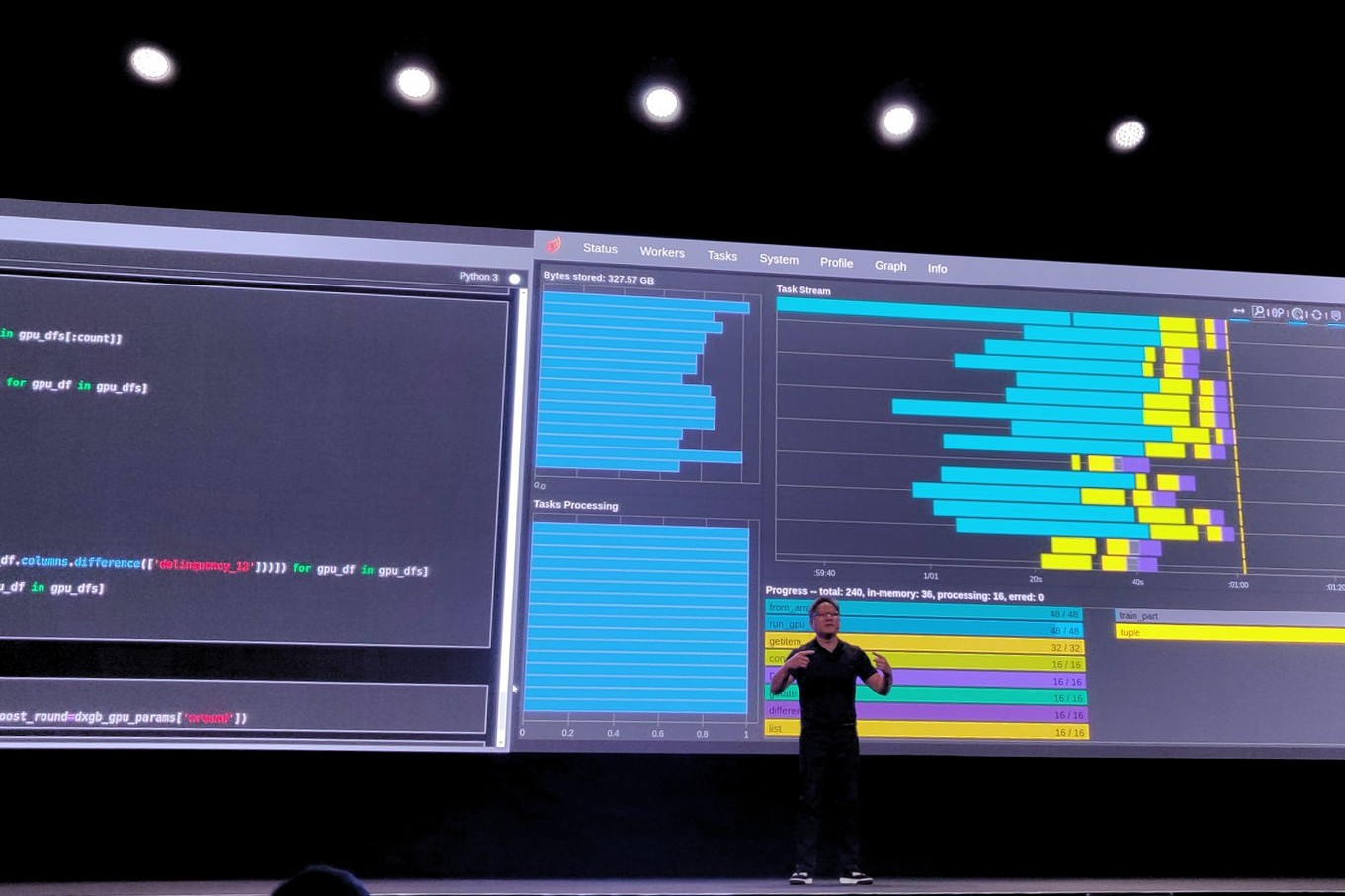
Apache Spark provides capabilities to program entire clusters with implicit data parallelism. With Spark 3.0 and the open source RAPIDS Accelerator for Spark,...
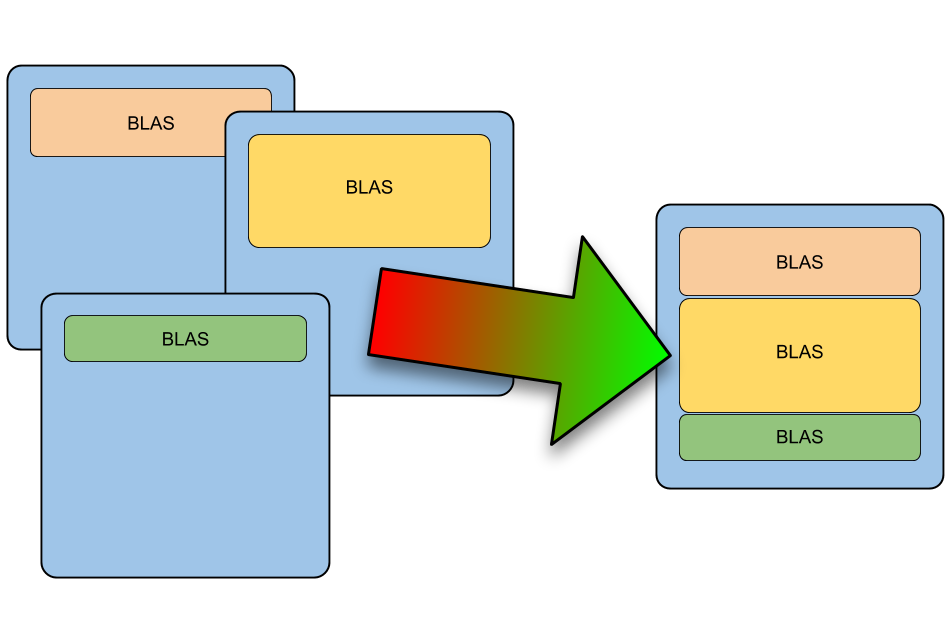
Fast, Flexible Allocation for NVIDIA CUDA with RAPIDS Memory Manager
When I joined the RAPIDS team in 2018, NVIDIA CUDA device memory allocation was a performance problem. RAPIDS cuDF allocates and deallocates memory at high...
There is a growing need among CUDA applications to manage memory as quickly and as efficiently as possible. Before CUDA 10.2, the number of options available...
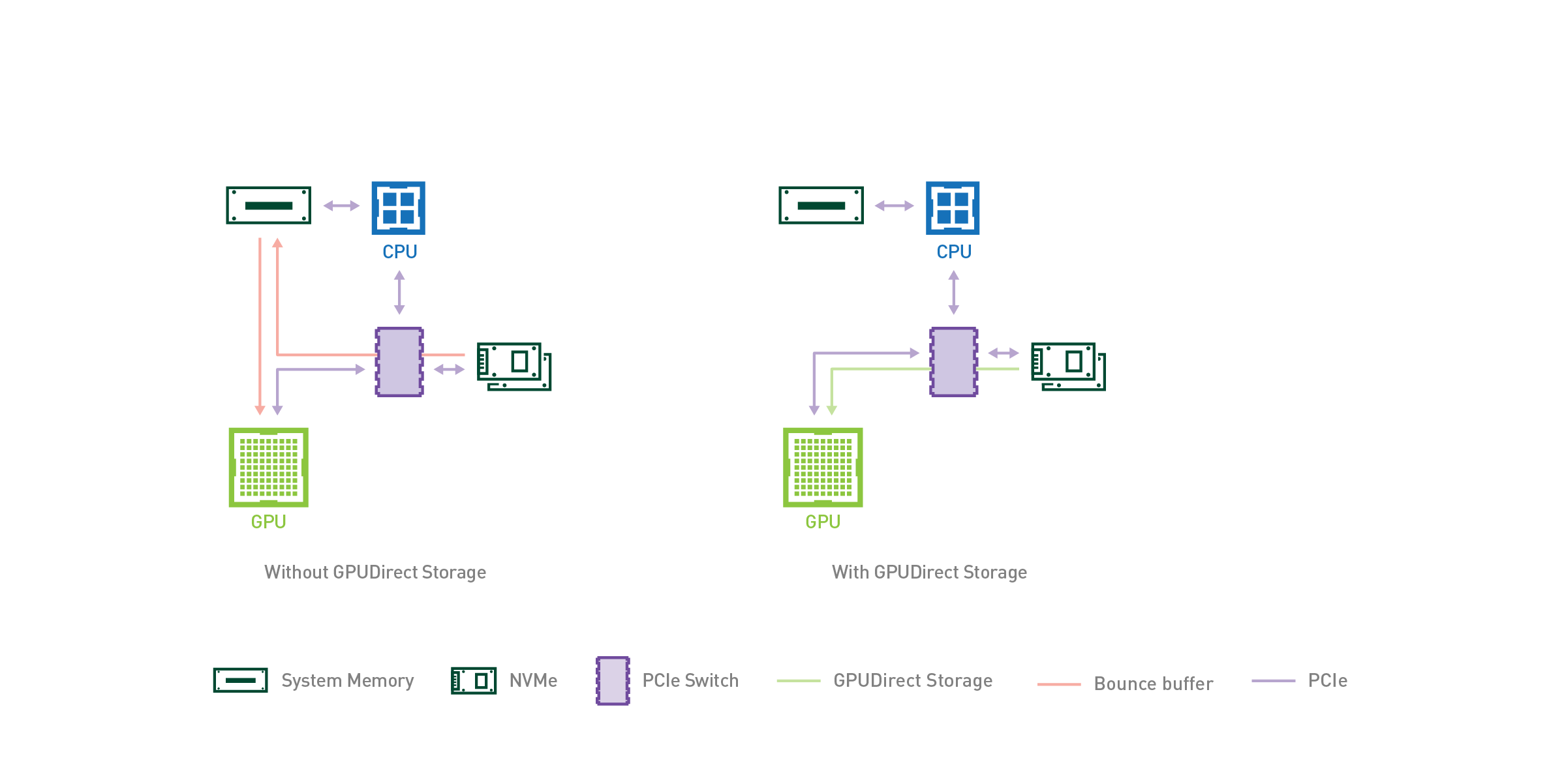
GPUDirect Storage: A Direct Path Between Storage and GPU Memory
As AI and HPC datasets continue to increase in size, the time spent loading data for a given application begins to place a strain on the total application’s...