
Heterogeneous computing is about efficiently using all processors in the system, including CPUs and GPUs. To do this, applications must execute functions concurrently on multiple processors. CUDA Applications manage concurrency by executing asynchronous commands in streams, sequences of commands that execute in order. Different streams may execute their commands concurrently or out of order with respect to each other. [See the post How to Overlap Data Transfers in CUDA C/C++ for an example]
When you execute asynchronous CUDA commands without specifying a stream, the runtime uses the default stream. Before CUDA 7, the default stream is a special stream which implicitly synchronizes with all other streams on the device.
CUDA 7 introduces a ton of powerful new functionality, including a new option to use an independent default stream for every host thread, which avoids the serialization of the legacy default stream. In this post I’ll show you how this can simplify achieving concurrency between kernels and data copies in CUDA programs.
Asynchronous Commands in CUDA
As described by the CUDA C Programming Guide, asynchronous commands return control to the calling host thread before the device has finished the requested task (they are non-blocking). These commands are:
- Kernel launches;
- Memory copies between two addresses to the same device memory;
- Memory copies from host to device of a memory block of 64 KB or less;
- Memory copies performed by functions with the
Asyncsuffix; - Memory set function calls.
Specifying a stream for a kernel launch or host-device memory copy is optional; you can invoke CUDA commands without specifying a stream (or by setting the stream parameter to zero). The following two lines of code both launch a kernel on the default stream.
kernel<<< blocks, threads, bytes >>>(); // default stream kernel<<< blocks, threads, bytes, 0 >>>(); // stream 0
The Default Stream
The default stream is useful where concurrency is not crucial to performance. Before CUDA 7, each device has a single default stream used for all host threads, which causes implicit synchronization. As the section “Implicit Synchronization” in the CUDA C Programming Guide explains, two commands from different streams cannot run concurrently if the host thread issues any CUDA command to the default stream between them.
CUDA 7 introduces a new option, the per-thread default stream, that has two effects. First, it gives each host thread its own default stream. This means that commands issued to the default stream by different host threads can run concurrently. Second, these default streams are regular streams. This means that commands in the default stream may run concurrently with commands in non-default streams.
To enable per-thread default streams in CUDA 7 and later, you can either compile with the nvcc command-line option --default-stream per-thread, or #define the CUDA_API_PER_THREAD_DEFAULT_STREAM preprocessor macro before including CUDA headers (cuda.h or cuda_runtime.h). It is important to note: you cannot use #define CUDA_API_PER_THREAD_DEFAULT_STREAM to enable this behavior in a .cu file when the code is compiled by nvcc because nvcc implicitly includes cuda_runtime.h at the top of the translation unit.
A Multi-Stream Example
Let’s look at a trivial example. The following code simply launches eight copies of a simple kernel on eight streams. We launch only a single thread block for each grid so there are plenty of resources to run multiple of them concurrently. As an example of how the legacy default stream causes serialization, we add dummy kernel launches on the default stream that do no work. Here’s the code.
const int N = 1 << 20;
__global__ void kernel(float *x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159,i));
}
}
int main()
{
const int num_streams = 8;
cudaStream_t streams[num_streams];
float *data[num_streams];
for (int i = 0; i < num_streams; i++) {
cudaStreamCreate(&streams[i]);
cudaMalloc(&data[i], N * sizeof(float));
// launch one worker kernel per stream
kernel<<<1, 64, 0, streams[i]>>>(data[i], N);
// launch a dummy kernel on the default stream
kernel<<<1, 1>>>(0, 0);
}
cudaDeviceReset();
return 0;
}
First let’s check out the legacy behavior, by compiling with no options.
nvcc ./stream_test.cu -o stream_legacy
We can run the program in the NVIDIA Visual Profiler (nvvp) to get a timeline showing all streams and kernel launches. Figure 1 shows the resulting kernel timeline on a Macbook Pro with an NVIDIA GeForce GT 750M (a Kepler GPU). You can see the very small bars for the dummy kernels on the default stream, and how they cause all of the other streams to serialize.
Now let’s try the new per-thread default stream.
nvcc --default-stream per-thread ./stream_test.cu -o stream_per-thread
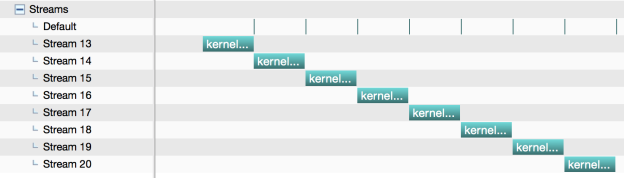
Figure 2 shows the results from nvvp. Here you can see full concurrency between nine streams: the default stream, which in this case maps to Stream 14, and the eight other streams we created. Note that the dummy kernels run so quickly that it’s hard to see that there are eight calls on the default stream in this image.

A Multi-threading Example
Let’s look at another example, designed to demonstrate how the new default stream behavior makes it easier to achieve execution concurrency in multi-threaded applications. The following example creates eight POSIX threads, and each thread calls our kernel on the default stream and then synchronizes the default stream. (We need the synchronization in this example to make sure the profiler gets the kernel start and end timestamps before the program exits.)
#include <pthread.h>
#include <stdio.h>
const int N = 1 << 20;
__global__ void kernel(float *x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159,i));
}
}
void *launch_kernel(void *dummy)
{
float *data;
cudaMalloc(&data, N * sizeof(float));
kernel<<<1, 64>>>(data, N);
cudaStreamSynchronize(0);
return NULL;
}
int main()
{
const int num_threads = 8;
pthread_t threads[num_threads];
for (int i = 0; i < num_threads; i++) {
if (pthread_create(&threads[i], NULL, launch_kernel, 0)) {
fprintf(stderr, "Error creating threadn");
return 1;
}
}
for (int i = 0; i < num_threads; i++) {
if(pthread_join(threads[i], NULL)) {
fprintf(stderr, "Error joining threadn");
return 2;
}
}
cudaDeviceReset();
return 0;
}
First, let’s compile with no options to test the legacy default stream behavior.
nvcc ./pthread_test.cu -o pthreads_legacy
When we run this in nvvp, we see a single stream, the default stream, with all kernel launches serialized, as Figure 3 shows.

Let’s compile it with the new per-thread default stream option.
nvcc --default-stream per-thread ./pthread_test.cu -o pthreads_per_thread
Figure 4 shows that with per-thread default streams, each thread creates a new stream automatically and they do not synchronize, so the kernels from all eight threads run concurrently.

More Tips
Here are a few more things to keep in mind when programming for concurrency.
- Remember: With per-thread default streams, the default stream in each thread behaves the same as a regular stream, as far as synchronization and concurrency goes. This is not true with the legacy default stream.
- The
--default-streamoption is applied per compilation unit, so make sure to apply it to allnvcccommand lines that need it. cudaDeviceSynchronize()continues to synchronize everything on the device, even with the new per-thread default stream option. If you want to only synchronize a single stream, usecudaStreamSynchronize(cudaStream_t stream), as in our second example.- Starting in CUDA 7 you can also explicitly access the per-thread default stream using the handle
cudaStreamPerThread, and you can access the legacy default stream using the handlecudaStreamLegacy. Note thatcudaStreamLegacystill synchronizes implicitly with the per-thread default streams if you happen to mix them in a program. - You can create non-blocking streams which do not synchronize with the legacy default stream by passing the
cudaStreamNonBlockingflag tocudaStreamCreate().
Download CUDA 7 RC Today
The Release Candidate of the CUDA Toolkit version 7.0 is available today for NVIDIA Registered Developers. If you aren’t a registered developer, register for free access at NVIDIA Developer Zone. Read about the features of CUDA 7 here.
Want to learn more about accelerated computing on the Tesla Platform and about GPU computing with CUDA? Come to the GPU Technology Conference, the world’s largest and most important GPU developer conference, March 17-20 at the San Jose Convention Center. Readers of Parallel Forall can use the discount code GM15PFAB to get 20% off any conference pass!`