
NVSHMEM is a parallel programming interface that provides efficient and scalable communication for NVIDIA GPU clusters. Part of NVIDIA Magnum IO and based on OpenSHMEM, NVSHMEM creates a global address space for data that spans the memory of multiple GPUs and can be accessed with fine-grained GPU-initiated operations, CPU-initiated operations, and operations on CUDA streams.
Existing communication models, such as the Message Passing Interface (MPI), orchestrate data transfers using the CPU. In contrast, NVSHMEM uses asynchronous, GPU-initiated data transfers, eliminating synchronization overheads between the CPU and the GPU.
This post dives into the details of the NVSHMEM 3.0 release, including new features and support that we are enabling across platforms and systems.
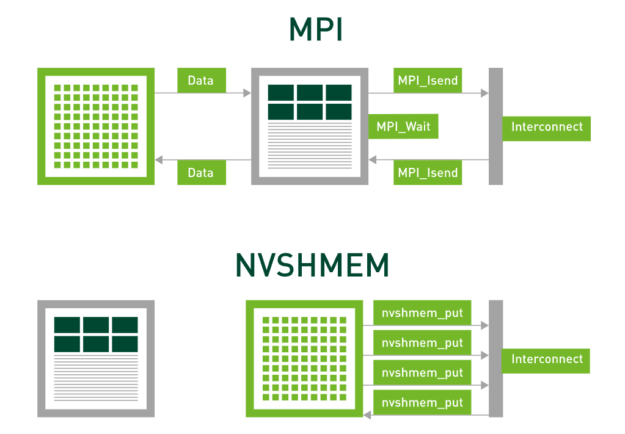
New features and interface support in NVSHMEM 3.0
NVSHMEM 3.0 introduces multi-node, multi-interconnect support, host-device ABI backward compatibility, and CPU-assisted InfiniBand GPU Direct Async (IBGDA).
Multi-node, multi-interconnect support
Previously, NVSHMEM has supported connectivity between multiple GPUs within a node over P2P interconnect (NVIDIA NVLink/PCIe) and multiple GPUs across a node over RDMA interconnects, such as InfiniBand, RDMA over Converged Ethernet (RoCE), Slingshot, and so on (Figure 2).
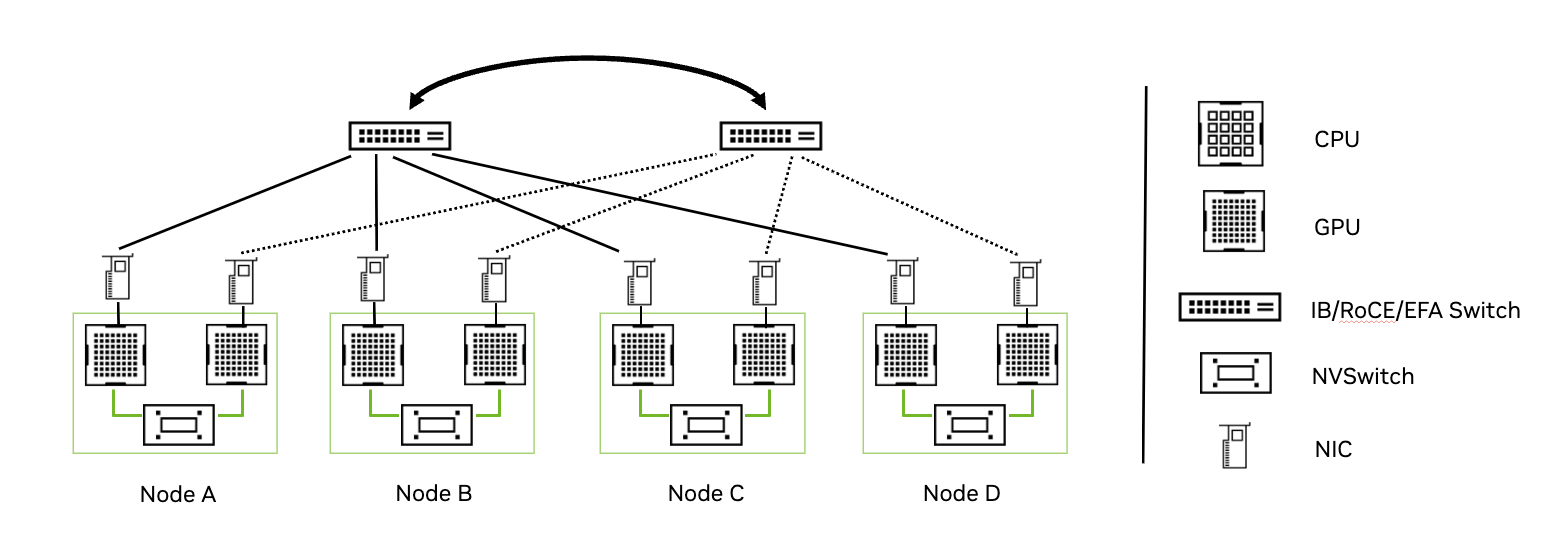
NVSHMEM 2.11 added support for Multi-Node NVLink (MNNVL or NVIDIA GB200 NVL72) systems (Figure 3). However, this support was limited to when NVLink was the only inter-node interconnect.
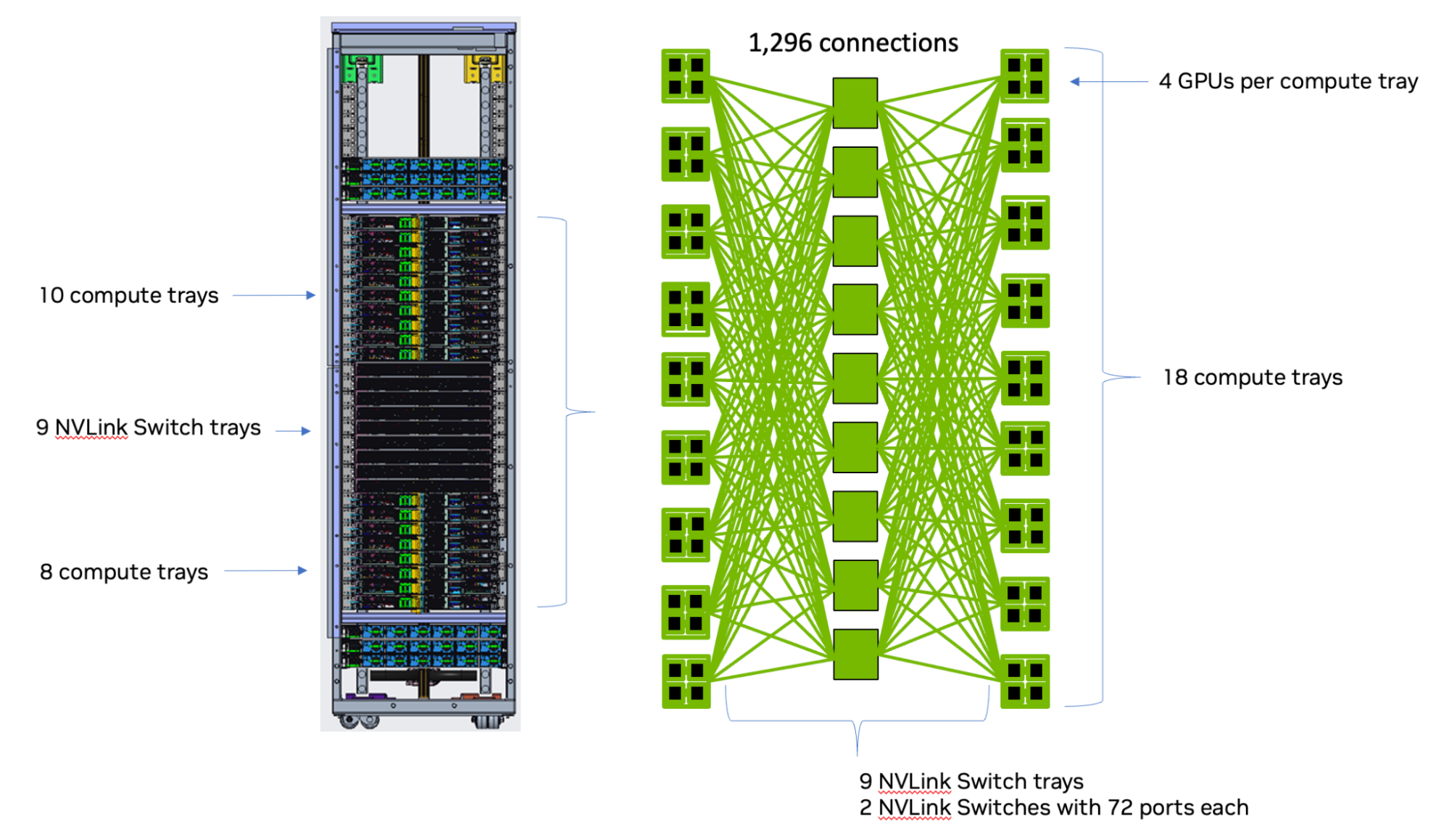
To address this limitation, new platform support was added to enable multiple racks of NVIDIA GB200 NVL72 systems connected to each other through RDMA networks (Figure 4). NVSHMEM 3.0 adds this platform support such that when two GPUs are part of the same NVLink fabric (for example, within the same NVIDIA GB200 NVL72 rack), NVLink will be used for communication.
In addition, when the GPUs are spread across NVLink fabrics (for example, across NVIDIA GB200 NVL72 racks), the remote network will be used for communication between those GPUs. This release also enhances the NVSHMEM_TEAM_SHARED capabilities to contain all GPUs that are part of the same NVLink clique that spans one or more nodes.

Host-device ABI backward compatibility
Historically, NVSHMEM has not supported backwards compatibility for applications or independently compiled bootstrap plug-ins. NVSHMEM 3.0 introduces backwards compatibility across NVSHMEM minor versions. An ABI breakage will be denoted by a change in the major version of NVSHMEM.
This feature enables the following use cases for libraries or applications consuming ABI compatible versions of NVSHMEM:
- Libraries linked to a minor version 3.X of NVSHMEM can be installed on a system with a newer installed version 3.Y of NVSHMEM (Y > X).
- Multiple libraries shipped together in an SDK, which link to different minor versions of NVSHMEM, will be supported by a single newer version of NVSHMEM.
- A CUDA binary (also referred to as cubin) statically linked to an older version of the NVSHMEM device library can be loaded by a library using a newer version of NVSHMEM.
| NVSHMEM Host Library 2.12 | NVSHMEM Host Library 3.0 | NVSHMEM Host Library 3.1 | NVSHMEM Host Library 3.2 | NVSHMEM Host Library 4.0 | |
| Application linked to NVSHMEM 3.1 | No | No | Yes | Yes | No |
| Cubin linked to NVSHMEM 3.0 | No | Yes | Yes | Yes | No |
| Multiple Libraries Lib 1 NVSHMEM 3.1 Lib 2 NVSHMEM 3.2 | No | No | No | Yes | No |
CPU-assisted InfiniBand GPU Direct Async
In previous releases, NVSHMEM supported traditional InfiniBand GPU Direct Async (IBGDA), where the GPU directly drives the IB NIC, enabling massively parallel control plane operations. It is responsible for managing the Network Interface Card (NIC) control plane, such as ringing the doorbell when a new work request is published to the NIC.
NVSHMEM 3.0 adds support for a new modality in IBGDA called CPU-assisted IBGDA, which acts as an intermediate mode between proxy-based networking and traditional IBGDA. It splits responsibilities of the control plane between the GPU and CPU. The GPU generates work requests (control plane operations) and the CPU manages NIC doorbell-ringing requests for submitted work requests. It also enables dynamic selections of the NIC assistant to be CPU or GPU at runtime.
CPU-assisted IBGDA relaxes existing administrative-level configuration constraints in IBGDA peer mapping, thereby helping to improve IBGDA adoption on non-coherent platforms where administrative level configuration constraints are harder to enforce in large-scale cluster deployments.
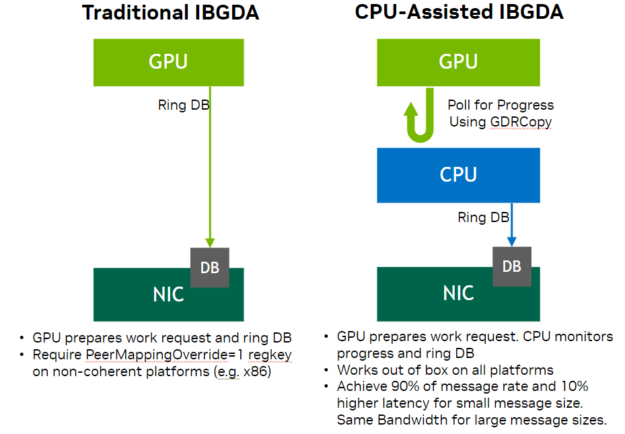
Non-interface support and minor enhancements
NVSHMEM 3.0 also introduces minor enhancements and non-interface support, as detailed in this section.
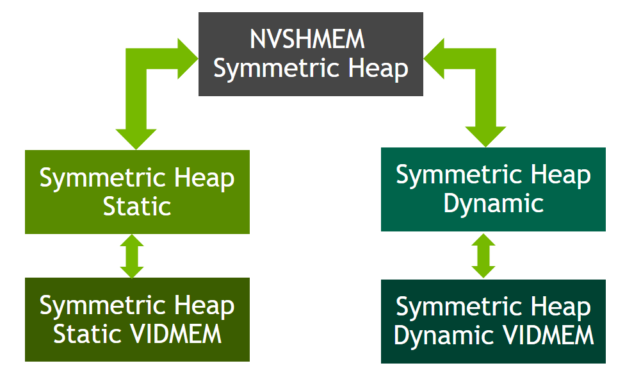
Object-oriented programming framework for symmetric heap
Historically, NVSHMEM has supported multiple symmetric heap kinds using a procedural programming model. This has limitations, such as a lack of namespace-based data encapsulation and code duplication and data redundancy.
NVSHMEM 3.0 introduces support for an object-oriented programming (OOP) framework that can manage different kinds of symmetric heaps such as static device memory and dynamic device memory using multi-level inheritance. This will enable easier extension to advanced features like on-demand registration of application buffers to symmetric heap in future releases.
Performance improvements and bug fixes
NVSHMEM 3.0 introduces various performance improvements and bug fixes for different components and scenarios. These include IBGDA setup, block scoped on-device reductions, system scoped atomic memory operation (AMO), IB Queue Pair (QP) mapping, memory registration, team management, and PTX build testing.
Summary
The 3.0 release of the NVIDIA NVSHMEM parallel programming interface introduces several new features, including multi-node multi-interconnect support, host-device ABI backward compatibility, CPU-assisted InfiniBand GPU Direct Async (IBGDA), and object-oriented programming framework for symmetric heap.
With host-device ABI backward compatibility, administrators can update to a new version of NVSHMEM without breaking already compiled applications, eliminating the need to modify the application source with each update.
CPU-assisted InfiniBand GPU Direct Async (IBGDA) enables users to benefit from the high message rate of the IBGDA transport on clusters where enforcing administrative level driver settings is not possible.
To learn more and get started, see the following resources:
- IBGDA: Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect Async
- Scaling Scientific Computing with NVSHMEM
- Accelerating NVSHMEM 2.0 Team-Based Collectives Using NCCL
- NVSHMEM Documentation
- NVSHMEM Best Practices Guide
- NVSHMEM API Documentation
- OpenSHMEM
- NVSHMEM Developer Forum
