NVSHMEM 2.0 is introducing a new API for performing collective operations based on the Team Management feature of the OpenSHMEM 1.5 specification. A team is a subset of processing elements (PEs) in an OpenSHMEM job. The concept is analogous to communicators in MPI. The new Teams API is a replacement for the active-set-based API for collective operations in the OpenSHMEM specification that was supported in prior versions of NVSHMEM. NVSHMEM supports host, device, and on-stream variants of the team-based collective APIs. For example, the following code shows the signatures of various variants of the reduce API action:
__host__ int nvshmem_<typename>_<op>_reduce(nvshmem_team_t team, TYPENAME *dest, const TYPENAME *source, size_t nreduce); __host__ int nvshmem_<typename>_<op>_reduce_on_stream(nvshmem_team_t team, TYPENAME *dest, const TYPENAME *source, size_t nreduce, cudaStream_t stream); __device__ int nvshmem_<typename>_<op>_reduce(nvshmem_team_t team, TYPENAME *dest, const TYPENAME *source, size_t nreduce);
The typename identifier specifies the datatype, such as int or float, and the op identifier specifies the operation, such as sum, min, or max. For more information, see Team Management.
The Teams API is easier to use than the active-set-based API. For example, you are no longer required to provide the synchronization (pSync) and work (pWrk) arrays to the collective’s API:
Example: nvshmem_int_sum_to_all using the active-set-based API
int *pWrk = (int *) nvshmem_malloc(NVSHMEM_REDUCE_WRK_DATA_SIZE*sizeof(int));
long *pSync = (long *) nvshmem_malloc(NVSHMEM_REDUCE_SYNC_SIZE*sizeof(long));
thrust::for_each(pSync, pSync+NVSHMEM_REDUCE_SYNC_SIZE, [=](long& entry) {
entry = NVSHMEM_SYNC_VALUE;
});
for(int iter = 0; iter < MAX_ITERS; iter++) {
/* Compute */
nvshmem_barrier_all(); /* Ensure pSync is reset and src can be read from at all PEs */
nvshmem_int_sum_to_all(dest, src, nreduce, 0, 0, npes, pWrk, pSync);
}
Example: nvshmem_int_sum_reduce using the new Teams API
for(int iter = 0; iter < MAX_ITERS; iter++) {
/* Compute */
nvshmem_int_sum_reduce(NVSHMEM_TEAM_WORLD, dest, src, nreduce);
}
Team-based collective API actions are supported on the device as well. A team object from the host can be passed as an argument to CUDA kernels or can be copied to device memory. The device-callable collective API actions come in the following variants:
- A single-threaded variant where one GPU thread on each PE in the team is selected to call into the collective. These variants have no suffix.
- A warp cooperative variant where one warp on each PE in the team is selected to call into the collective. All threads in the warp compute the collective cooperatively. These variants have a
_warpsuffix. - A block cooperative variant where one CUDA block on each PE in the team is selected to call into the collective. All threads in the CUDA block compute the collective cooperatively. These variants have a
_blocksuffix.
The optimal variant to use depends on the size of the collective (nreduce).
__global__ void my_kernel(int *dest, int *src, int nreduce, nvshmem_team_t team, …)
{
/* compute */
if ( blockDim.x <= nreduce )
{
//select first block
if ( 0 == blockIdx.x )
{
nvshmem_int_sum_reduce_block(team, dest, src, nreduce);
}
}
else if ( 1 < nreduce )
{
//select first warp from first CUDA block
if ( 0 == blockIdx.x && 0 == threadIdx.x/warp_size )
{
nvshmem_int_sum_reduce_warp(team, dest, src, nreduce);
}
}
else
{
//select first thread
if (0 == blockIdx.x * blockDim.x + threadIdx.x)
{
nvshmem_int_sum_reduce(team, dest, src, nreduce);
}
}
}
When you use the device-callable collective APIs, make sure that all participating GPU threads on all PEs in the team are active at the same time. We recommend using nvshmemx_collective_launch to launch the GPU kernel calling the collective.
NVSHMEM provides the following predefined teams:
NVSHMEM_TEAM_WORLD—All the PEs that a NVSHMEM job is initialized with.NVSHMEM_TEAM_SHARED—The PEs whose symmetric heap is directly accessible through memory load/store/atomic using thenvshmem_ptroperation.NVSHMEMX_TEAM_NODE—All the PEs that are on the same node or OS instance.
On systems like an NVIDIA DGX A100 where all GPUs are directly connected to all other GPUs via NVLink, the NVSHMEMX_TEAM_NODE teams contain the same PEs as the NVSHMEM_TEAM_SHARED teams. Compared to that, a DGX-1 V100 consists of two fully connected sets with four GPUs each. On DGX-1 V100, the NVSHMEMX_TEAM_NODE team contains all PEs running on the same node but on each node, there are two NVSHMEM_TEAM_SHARED teams (Figure 1).
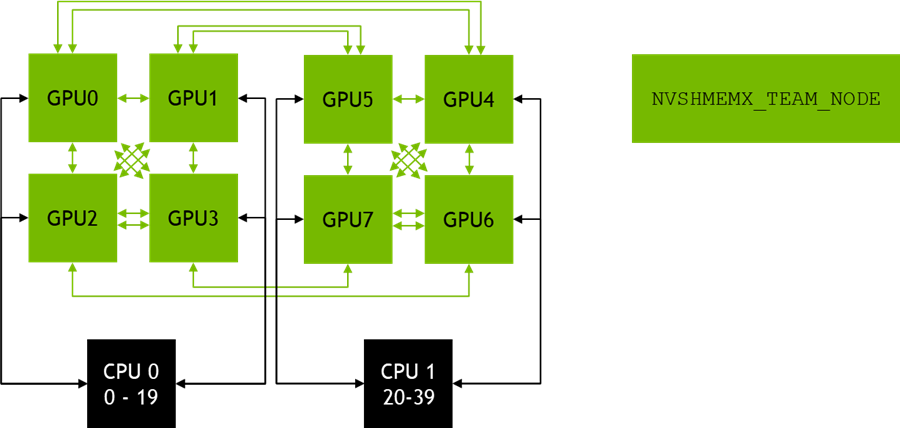
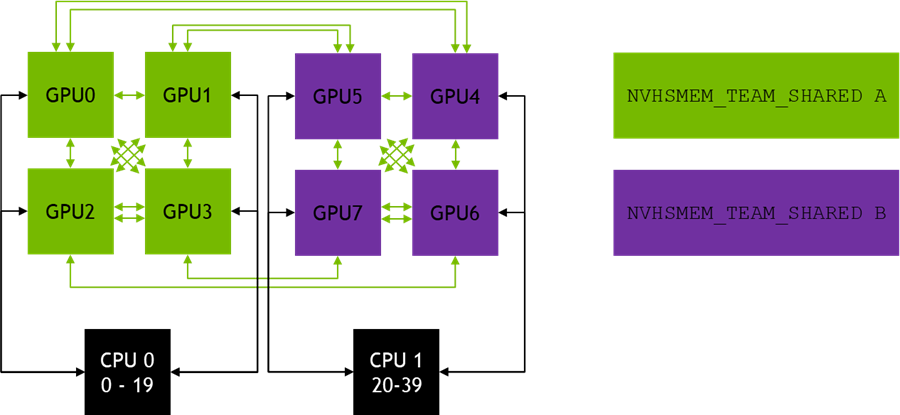
Figure 2 shows the intended behavior of NVSHMEM_TEAM_SHARED teams. In the initial implementation of the Teams API in NVSHMEM 2.0, each NVSHMEM_TEAM_SHARED team only contains a single GPU.
Because NVSHMEMX_TEAM_NODE contains all PEs running in a node, it can be conveniently used to select which GPU each PE should use on multi-GPU nodes:
mype_node = nvshmem_team_my_pe(NVSHMEMX_TEAM_NODE); cudaGetDeviceCount(&dev_count); cudaSetDevice(mype_node % dev_count);
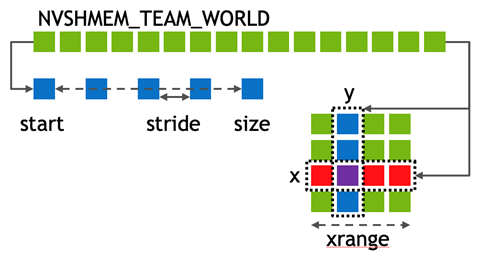
You can create new teams through one of the following two host APIs: nvshmem_team_split_strided or nvshmem_team_split_2d.
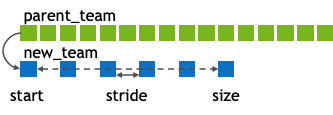
int nvshmem_team_split_strided(nvshmem_team_t parent_team, int start, int stride, int size, const nvshmem_team_config_t *config, long config_mask, nvshmem_team_t *new_team);
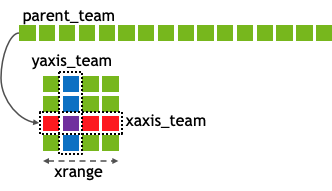
int nvshmem_team_split_2d(nvshmem_team_t parent_team, int xrange, const nvshmem_team_config_t *xaxis_config, long xaxis_mask, nvshmem_team_t *xaxis_team, const nvshmem_team_config_t *yaxis_config, long yaxis_mask, nvshmem_team_t *yaxis_team);
Consider a modification of the nvshmem_int_sum_reduce example earlier where only every other PE should participate in the reduction. In this case, you can use nvshmem_team_split_strided to create this team as in the following examples.
Example: nvshmem_int_sum_to_all using the active-set-based API
/* allocated pWrk, pSyncand initialized as shown in the example above */
long *pSync2 = (long *) nvshmem_malloc(NVSHMEM_SYNC_SIZE*sizeof(long));
thrust::for_each(pSync, pSync+NVSHMEM_REDUCE_SYNC_SIZE, [=](long& entry) {
entry = NVSHMEM_SYNC_VALUE;
});
if (0 == my_pe % 2) {
for(int iter = 0; iter < MAX_ITERS; iter++) {
/* Compute */
nvshmem_barrier(0, 1, npes / 2, pSync2); /* Ensure pSync is reset and src can be read from at all PEs */
nvshmem_int_sum_to_all(dest, src, nreduce, 0, 1, npes / 2, pWrk, pSync);
}
}
Example: nvshmem_int_sum_reduce using the new Teams API
nvshmem_team_split_strided(NVSHMEM_TEAM_WORLD, 0, 1, npes / 2, NULL, 0, &team);
if (0 == my_pe % 2) {
for(int iter = 0; iter < MAX_ITERS; iter++) {
/* Compute */
nvshmem_int_sum_reduce(team, dest, src, nreduce);
}
}
The Teams-based API in NVSHMEM also makes it easier to leverage NCCL for implementing host and on-stream collective APIs in NVSHMEM. To build NVSHMEM with NCCL support, NCCL_HOME should point to the NCCL installation and NVSHMEM_USE_NCCL=1 needs to be set. If NVSHMEM is built with NCCL support, it is used by default and can be switched off at runtime by setting NVSHMEM_DISABLE_NCCL=1.
For every NVSHMEM team, NVSHMEM constructs a corresponding NCCL communicator. NVSHMEM calls NCCL whenever there is a corresponding collectives API available in NCCL. Currently, NCCL is leveraged for the host and on-stream versions of broadcast, collect, and reductions.
Up till now, collectives in NVSHMEM have not been optimized. The new NCCL-based collectives provide significant speedups both in terms of latency and throughput. For benchmarks, we used the NVIDIA Selene supercomputer made of 560 DGX A100 connected with a non-blocking InfiniBand network and eight NVIDIA ConnectX-6 HDR200 InfiniBand HCA per node (1 per GPU). For more information about Selene, see Selene – NVIDIA DGX A100, AMD EPYC 7742 64C 2.25GHz, NVIDIA A100, Mellanox HDR Infiniband and NVIDIA DGX SuperPOD.
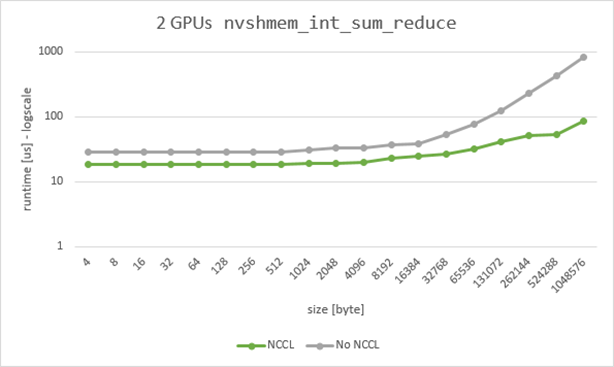
Running the NVSHMEM perftests for nvshmem_int_sum_reduce_on_stream over all tested message sizes, we saw speedups from 1.5x to almost 10x when using two GPUs in one DGX A100 (Figure 5).
When using 16 GPUs in two nodes, the speedup increases to up to almost 260x for large messages (Figure 6).
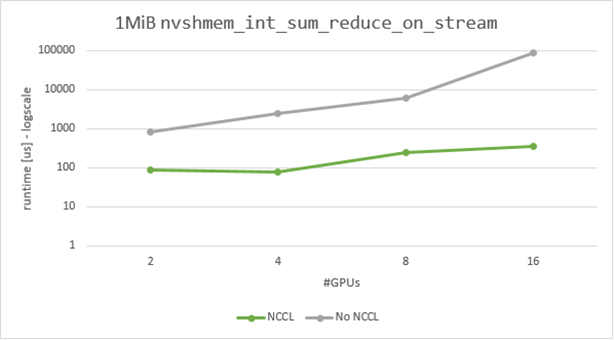
The high delta in performance for large message sizes (Figure 6) between the NCCL and non-NCCL case is due to NVSHMEM using a recursive-doubling algorithm that is optimized only for latency of small message reductions. The algorithm used by NCCL is optimized for large message sizes as well.
For a 4-byte message, we saw a speedup between 1.5x and 1.7x (Figure 7).
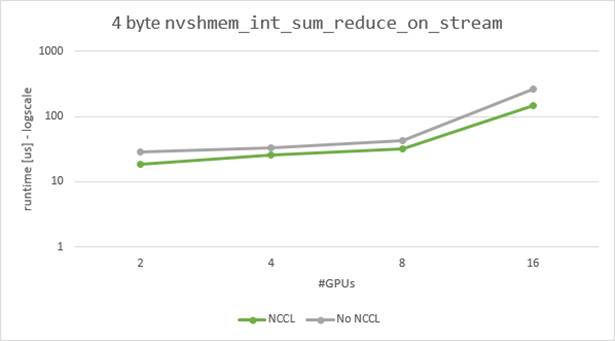
The latency delta between the NCCL and non-NCCL case (Figure 7) is due to an internal barrier needed in the non-NCCL case to reuse team internal resources (pSync array).
Download NVSHMEM 2.0 from the NVIDIA Developer website and try out the new Teams API!
