Hospitals today are seeking to overhaul their existing digital infrastructure to improve their internal processes, deliver better patient care, and reduce operational expenses. Such a transition is required if hospitals are to cope with the needs of a burgeoning human population, accumulation of medical patient data, and a pandemic.
The goal is not only to digitize existing infrastructure but to optimize workflow efficiency, help bring many pieces of patient data together, and create new tools for screening and diagnosis. By feeding data from smart sensors into edge-based systems, hospitals can serve the needs of both patients and staff in real time.
A key part of the smart hospital ecosystem is the independent software vendors (ISVs) who build and deploy state-of-the-art applications for these hospitals. The ISV data scientists and developers need easy access to software building blocks that include models and containers both secure and high-performing. These building blocks give developers a headstart on building AI models and the underlying architecture.
After the application is built, it must be deployed on a myriad of edge devices for real-time insights. However, deploying, monitoring, and managing software on edge devices presents its own set of challenges. DevOps and IT managers must seamlessly manage all the physical devices at each location and the software deployment.
In this post, we show how you can use NVIDIA Clara Guardian, a smart hospital application framework from the NVIDIA NGC Catalog, to build applications and NVIDIA Fleet Command to securely deploy applications at the edge.
Accelerating AI workflows with NGC
The NGC catalog was built to help accelerate AI workflows. It is the hub for cloud-native, GPU-optimized AI and HPC applications and tools that provides faster access to performance-optimized containers, shortens time-to-solution with pretrained models and provides industry specific software development kits to build end-to-end AI solutions. The catalog hosts a diverse set of assets that can be used for a variety of applications and use cases ranging from computer vision and speech recognition to recommendation systems and more.
In the area of healthcare, the pretrained models cover key features such as annotation, segmentation, and classification. You can apply transfer learning to a model and retrain it against your own data to create your own custom model.
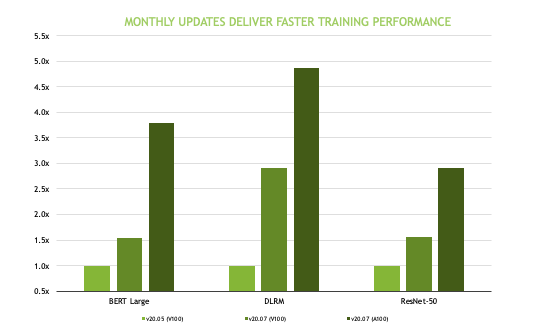
The AI containers and models on the NGC catalog are tuned, tested, and optimized to extract maximum performance from your existing GPU infrastructure. The containers and models use automatic mixed precision (AMP), enabling you to use this feature with either no code changes or only minimal changes. AMP uses the Tensor Cores on NVIDIA GPUs and can speed up model training considerably. Multi-GPU training is a standard feature implemented on all NGC models that use Horovod and NCCL libraries for distributed training and efficient communication.
NVIDIA Clara Guardian on NGC
One of the frameworks that are containerized on the NGC catalog is NVIDIA Clara Guardian. Clara Guardian, available as part of an early access program from the NGC catalog, is one of the many healthcare application frameworks available. Key components include healthcare pretrained models for computer vision and speech, training tools, deployment SDKs, and NVIDIA Fleet Command, all of which enable ISVs to build and deploy solutions quickly and efficiently for use in hospitals.
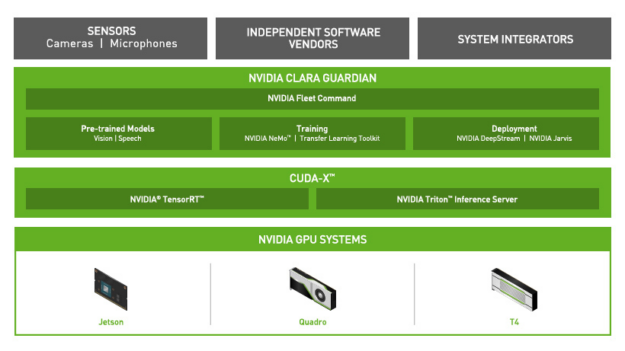
This makes it easy for you to add AI capabilities to common sensors that can monitor crowds for safe social distancing, measure body temperature, detect the absence of protective gear such as masks, or interact remotely with high-risk patients so that everyone in the healthcare facility stays safe and informed. Applications and services can run on a wide range of hardware, from NVIDIA Jetson Nano to an NVIDIA T4 server, allowing you to securely deploy anywhere, from the edge to the cloud.
NVIDIA Fleet Command
NVIDIA Fleet Command is a hybrid-cloud platform to manage and scale AI deployments across dozens or up to millions of servers or edge devices. Fleet Command allows IT departments to manage a large-scale fleet of deployed systems securely and remotely. Instead of spending weeks planning and executing deployment plans, administrators can bring AI to networked hospitals in minutes. Administrators can add or delete applications, update system software over the air, and monitor the health of devices spread across vast distances from a single control plane.
Security is a requirement for all enterprises. Applications hosted in the NGC catalog are scanned for common vulnerabilities and exposures (CVEs), crypto keys, private keys, and metadata scans, ensuring that they are ready for production-level deployments. At the edge, all processed data is encrypted at rest and the AI runtime is protected from tampering with secure and measured boot. In addition, because systems are on-premises to process local sensor feeds, organizations maintain control of where sensor data is stored.
Clara Guardian in action
NVIDIA Inception healthcare AI startup Whiteboard Coordinator uses Clara Guardian to build virtual patient assistant solutions for leading hospitals such as Northwestern Hospitals. Patient safety is always important but during the COVID-19 pandemic, it is essential.
Actions like reducing physical contact are key to reducing transmission and keeping patients and healthcare staff safe. Conversational AI can help reduce direct physical contact while continuing to deliver high-quality care. Instead of waiting for a clinical staff member to become available, patients can receive immediate answers from an AI-powered virtual assistant.
Building the application
Now that you have seen Clara Guardian in action, here’s how you can build the application.
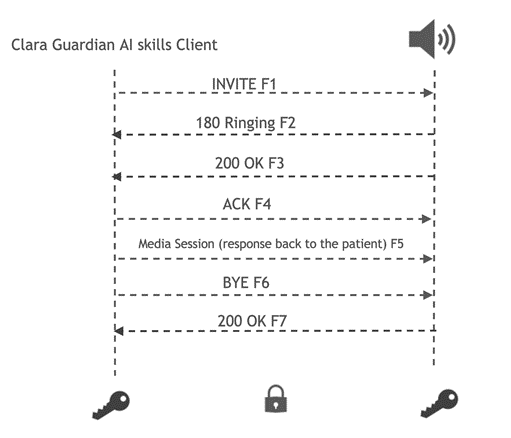
The Virtual Patient Assistant application is a Clara Guardian client application that takes input queries from the patient, interprets the query by extracting intent and relevant slots, and computes a response in real time, in a natural-sounding voice. The patient can ask any questions ranging from general concerns on the daily schedule to more domain-specific questions regarding treatment plans or medical procedures.
Clara Guardian client applications interact with the Clara Guardian SDK using the gRPC protocol. In the case of the Virtual Patient Assistant application, the methods are specific to automated speech recognition, natural language understanding, and text to speech with defined request and response types. The client has a stub that provides the same methods as the server and runs on the same host. Python bindings are typically used to interact with the Clara Guardian AI services. The client, however, can talk to the server in any official gRPC supported language by using protobuf files.
The Clara Guardian automated speech recognition (ASR) skills perform real-time English transcription of incoming, streaming audio, RTP streams encoded in 16-bit LPCM. For ease of integration with a wide range of microphones located in the patient room and to accommodate different frequency responses, polar patterns, and proximity effects, we provide an RTP connector as part of the client application that encodes incoming microphone data to Clara Guardian ASR-compatible input. ASR at its core represents an end-to-end speech recognition pipeline based on the Jasper model.
The ASR skills are optimized for low latency by allowing whole sub-blocks of the convolutional layers to be fused into a single GPU kernel with high accuracy (measured at ~2% WER on medical datasets). You can also train your own acoustic model using NeMo by following the step-by-step instructions. To deploy your trained model with Clara Guardian, you must export the encoder and the decoder checkpoint to ONNX.
The Clara Guardian Natural Language Understanding (NLU) service takes the ASR-transcribed text as an input and extracts the patient intent and the relevant slots based on a pretrained BERT model for joint intent classification and slot filling. To train this model with your own data, see the nlp/intent_slot_classification examples posted on GitHub.
The Clara Guardian text-to-speech skills are based on two neural network models:
- A modified Tacotron 2 model based on the Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions paper.
- A flow-based neural network model based on the WaveGlow: A Flow-based Generative Network for Speech Synthesis paper.
The Tacotron 2 and WaveGlow models, available from the NGC catalog, form a text-to-speech pipeline that synthesizes natural-sounding speech without any additional information such as patterns or rhythms of speech. The Tacotron 2 model generates a mel spectrogram from the input NLU text because of the intent classifier and slot tagger using the encoder-decoder architecture and WaveGlow generates speech back to the patient.
You can train both Tacotron 2 and WaveGlow using your own data by following the NeMo documentation. To send the responses back to the speakers in the patient room, we provide a TLS-secure Session Initiation Protocol (SIP) connector. The transmission is encrypted to prevent eavesdropping, tampering, and message forgery when streaming the responses back to the patient.
To build the application, you must write a Python client that communicates with the Clara Guardian AI Skills server in gRPC. The client transcribes the incoming RTSP stream and sends the streaming responses to the Clara Guardian AI Skills server as a first processing step:
#import all the libraries #setup the channel and the client channel = grpc.insecure_channel(clara_guardian_server) client = risr_srv.RivaSpeechRecognitionStub(channel) ... #set the streaming config parameters config = risr.RecognitionConfig( encoding=clara_guardian_encodi sample_rate_hertz=16000, language_code="en-US", max_alternatives=1, enable_automatic_punctuation=True) streaming_config = risr.StreamingRecognitionConfig(config_parameters) mic_rtsp = open_stream(IP_of_device) #send client requests to generate responses ... mic_rtsp.close_stream()
After the audio is transcribed, the client sends the NLP Skills server requests to detect and identify patient queries. For example, when a patient asks, “What procedure am I having today?”, the slot tagger extracts the related semantic entities, such as “day_of_week”.
intent {
class_name: "procedure_inquiry"
score: 0.9931640625
}
slots {
token: "today"
label {
class_name: "day_of_week"
score: 0.56298828125
}
}
domain_str: "healthcare"
domain {
class_name: "healthcare"
score: 0.9866989850997925
As a final step, you send streaming requests to the TTS streaming skills server and then send the encrypted responses to the IP devices in the patient room:
responses = client.SynthesizeOnline(req)
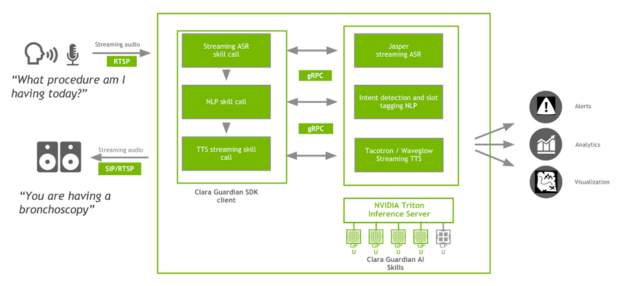
The Clara Guardian AI services are deployed with NVIDIA Triton Inference Server. Triton Inference Server is a cloud inference solution optimized for NVIDIA GPUs that supports deployment of AI models trained with all the major frameworks including TensorRT, TensorFlow, PyTorch, ONNX Runtime, or even custom frameworks and provides an inference server using a gRPC endpoint. Inference requests arrive at the server using gRPC and are then routed to the appropriate per-model scheduler. The model scheduler batches the inference requests and forwards the requests to the backend to the corresponding ASR, NLP, or TTS model. Triton also provides ensemble support through a single inference request that triggers the execution of the entire ASR-NLP-TTS model pipeline. Several metrics—such as GPU utilization, latency, number of inference requests, and number of inferences performed—are available by accessing the endpoint.
Deploying the application
This section describes deploying the Virtual Patient Assistant application with NVIDIA Fleet Command on an NVIDIA T4, NGC-Ready for edge server, validated to run various AI workloads and tested for security and remote management protocols.
You also use Helm charts to deploy the application. Helm is the NVIDIA recommended package manager for Kubernetes that allows you to easily configure, deploy, and update applications on Kubernetes. The Helm chart provided for Clara Guardian is responsible for downloading model artifacts, setting up a model repository, and launching the ASR, NLU, and TTS services.
To get started with NVIDIA Fleet Command, you’ll need access to your organization’s NGC private registry. The NGC private registry provides a secure cloud-hosted environment for developers to customize pre-trained models, SDKs, and Helm charts from NGC, encrypt, sign, share and deploy their proprietary software from a single portal. With additional features such as user management and custom model creations, you can foster collaboration between teams and improve the overall development and deployment process. Click here to find out more about setting up your NGC private registry.
Once your NGC private registry is set up, you can login to your NGC account. To access applications in your NGC private registry from Fleet Command, synchronize them by entering the NGC API key for authentication.
After you have uploaded all your custom content to the NGC Private Registry, add the edge location where the application is to be deployed. In this example, that is the T4 server installed at Northwestern Hospitals.
To add the Virtual Patient Assistant application deployed on the Kubernetes cluster with the Clara Guardian Helm chart, choose Applications, Add Application. In the form, enter the relevant details for the application, including the name of the Helm chart.
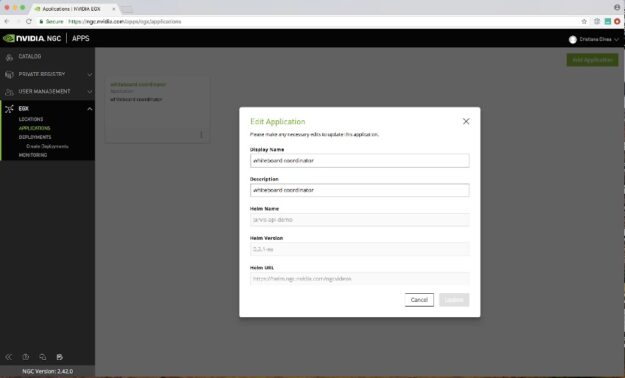
The riva-api-demo Helm chart has the following tree structure:
├── Chart.yaml ├── templates │ ├── _helpers.tpl │ ├── artifactSecret.yaml │ ├── deployment.yaml │ ├── registrySecret.yaml │ └── service.yaml └── values.yaml
Helm charts are templates, and the values.yaml file provides the runtime config to be injected into the charts. This can be considered analogous to the parameters for a release, which are used to customize the chart.
The /templates directory contains template files that are combined with configuration values from values.yaml and custom config and rendered into Kubernetes manifests.
The final step is to create the deployment. The Helm deployment uses two Kubernetes secrets for obtaining access to NGC: one for Docker images, and another for model artifacts. By default, these are named riva-ea-regcred and imagepullsecret, respectively. The names of the secrets can be modified in the values.yaml file. When you add the API key (using the Fleet Command location option) it adds an Kubernetes secret called imagepullsecret to all the EGX systems in your locations.

After you choose Deploy, the application is successfully deployed to the server inside the hospital. When the application has been deployed, you’ll see the status change to green (or active), indicating a successful deployment.
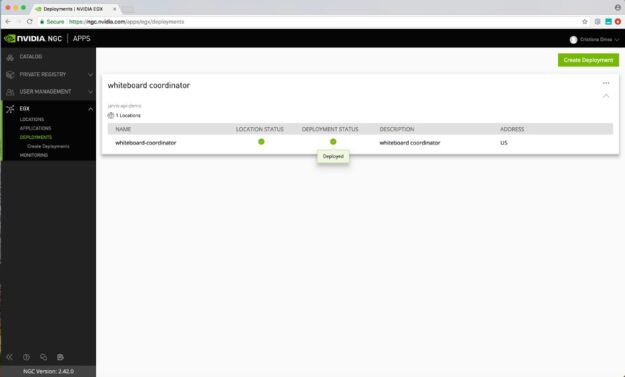
Summary
The Virtual Patient Assistant application can be easily built with Clara Guardian and securely deployed, managed, and scaled with the NVIDIA Fleet Command to power Smart Hospitals.
Get started today by signing up for access to Clara Guardian available from the NGC catalog.
