
Self-driving cars must be able to detect objects quickly and accurately to ensure the safety of their drivers and other drivers on the road. Due to this need for real-time processing in autonomous driving (AD) and visual inspection use cases, multiple AI models with preprocessing and postprocessing logic are combined in a pipeline and used for machine learning (ML) inference.
Speedup is required in every step of the pipeline to ensure a low latency workflow. Latency is the time it takes to get the inference response. Faster processing of AD data will enable more efficient analysis and use of the information, creating a safer driving environment. A delay with any single aspect can slow down the entire pipeline.
To achieve a low latency inference workflow, electric vehicle manufacturer NIO integrated NVIDIA Triton Inference Server into their AD inference pipeline. NVIDIA Triton Inference Server is an open source multiframework inference serving software.
This post explains how NIO orchestrated its pipeline of image preprocessing and postprocessing and AI models with NVIDIA Triton on GPUs. It also shows how NIO reduced network transmission to successfully speed up their AI inference workflow for AD use cases.

Faster AI inference for real-time response
NIO designs, develops, jointly manufactures, and sells premium smart electric vehicles, driving innovations in next-generation technologies in autonomous driving, digital technologies, electric powertrains, and batteries. NIO Autonomous Driving Development Platform (NADP) is an R&D platform dedicated to the core autonomous driving service of NIO.
NIO chose NVIDIA Triton Inference Server because of several key technical and operational reasons, including:
- NVIDIA Triton supports DAG-based orchestration of numerous models, along with preprocessing or postprocessing modules
- Cloud-native deployment of NVIDIA Triton enabled multi-GPU, multi-node scaling in a lightweight way
- High-quality documentation and learning resources helped ease migration to NVIDIA Triton
- NVIDIA Triton’s stability and robust functionality are necessary for AD use cases
NIO’s AI inference workflow for autonomous driving
Hundreds of AI models are used to mine data from autonomous vehicles. In a use case like autonomous driving, the inference workflow consists of multiple AI models with preprocessing and postprocessing logic stitched together in a pipeline.
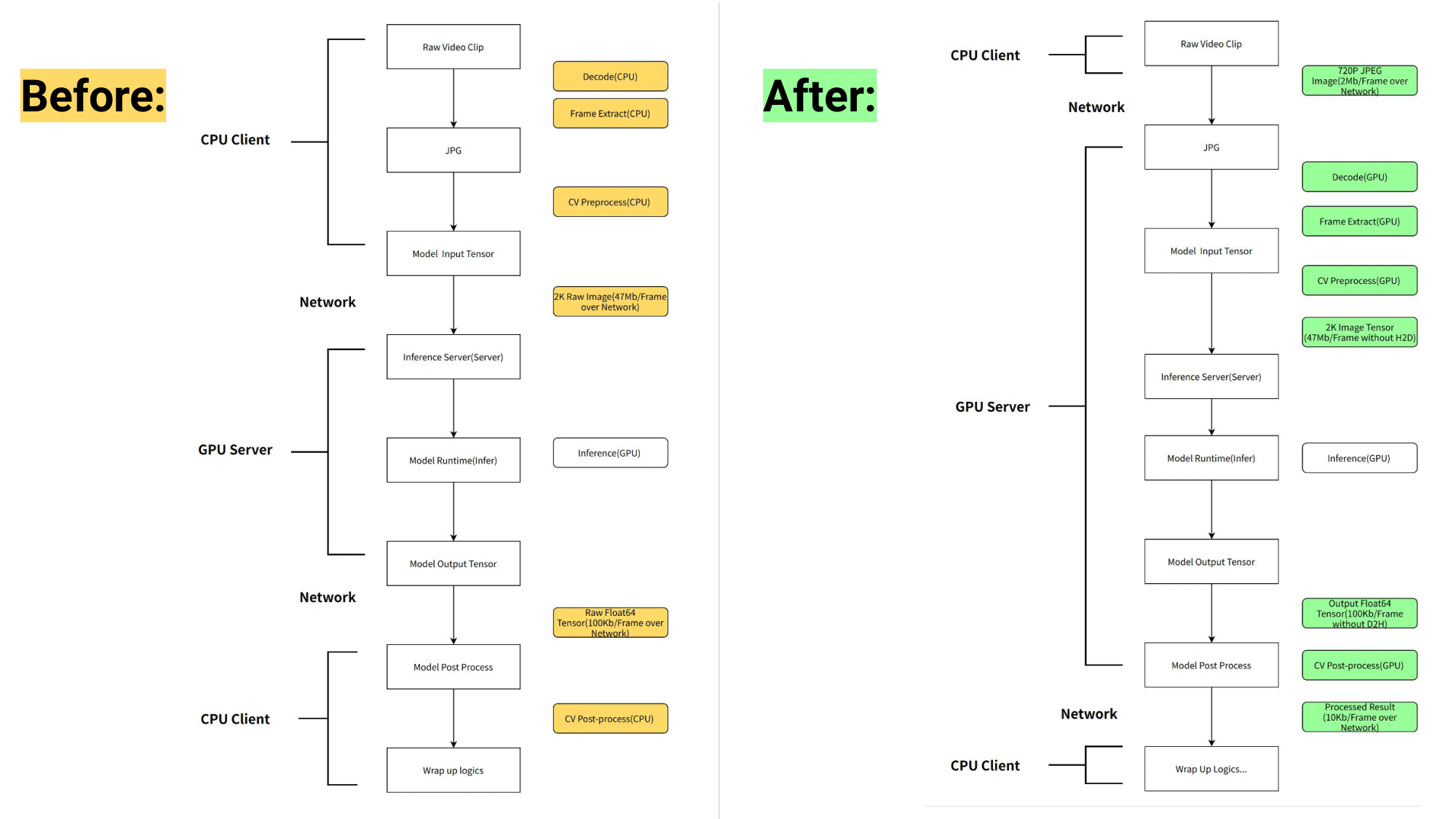
NIO moved the preprocessing and postprocessing of the pipeline from the client side, which runs on CPUs, to NVIDIA Triton running on GPUs. The NVIDIA Triton’s business logic scripting (BLS) functionality was used to orchestrate the pipeline to run optimally for AD use.
By moving the preprocessing from CPU to GPU and leveraging efficient pipeline orchestration, NIO achieved 6x latency reduction in some core pipelines, improving the overall throughput by up to 5x.
Before and after workflow pipelines are shown in Figure 1.
Model pipeline orchestration benefits of NVIDIA Triton
This section examines each of the benefits NIO realized by integrating NVIDIA Triton.
GPU-accelerated preprocessing
Preprocessing tasks such as decoding, resizing, and transposing were accelerated on the GPU by NVIDIA Triton using nvJPEG and NVIDIA DALI. This significantly offloaded the computing workload from the client CPU and reduced preprocessing latency.
Upgrading models without the need for client application modification
By moving the preprocessing and postprocessing of the model to NVIDIA Triton, each time the model is upgraded, the client side does not require any modification. This essentially speeds up the rollout of the model, helping it reach production faster.
Using a single GPU node to reduce network data transfer overhead
A unified preprocessing enables multiple copies of the input to be shared with multiple backend recognition models. The process uses GPU shared memory on the server side, without data transfer overhead costs.
Figure 2 shows the pipeline can connect up to nine models using the NVIDIA Triton business logic scripting functionality.
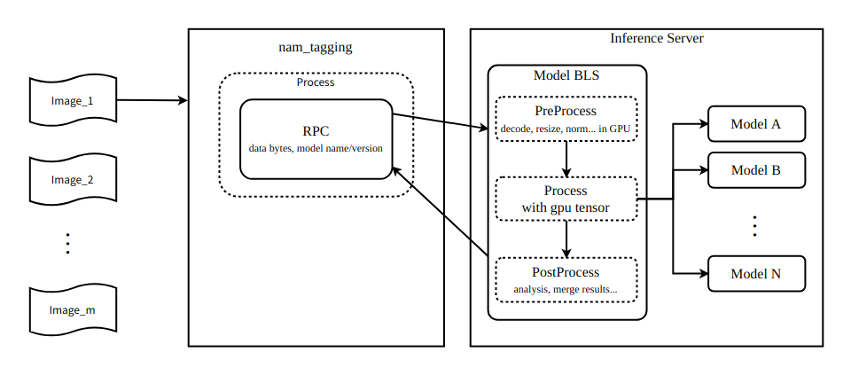
For an input image of 2 K resolution, the size of each frame is 1920 x 1080 x 3 x 8 = 47 Mb. Assuming a full frame rate of 60 fps, the amount of data input per second is 1920 x 1080 x 3 x 8 x 60 = 2847 Mb. In the previous workflow, each image is sent sequentially to the nine models over the network. Data transferred per second is 1920 x 1080 x 3 x 8 x 60 x 9 = 25 Gb = 3 GB.
In the new workflow, the nine models are orchestrated with the NVIDIA Triton business logic scripting. That means the models can access the image in the GPU shared memory and the images do not have to be sent over the network. Assuming a PCIe bandwidth of 160 Gb = 20 GB per second, theoretically the data generated per second can save 150 ms in data transfer if the data is transferred over PCIe.
Assuming an available bandwidth of 16 Gb = 2 GB per second, theoretically the data generated per second can save 1,500 ms in data transfer if the data is transferred over the network. All these result in speeding up the workflow.
Network transfer savings using image compression
For accurate model prediction, the input image must be 1920 x 1080 x 3 x 8 bytes in the previous workflow and must be transmitted through the network. After introducing the server-side preprocessing, the original image can be altered to a compressed three-channel 720 pixel image (1280 x 720 x 3) within the allowed range of accuracy loss.
As a result, it only takes a few hundred KB to transmit the bytes of the compressed image and resize with minimal accuracy loss to 1920 x 1080 x 3 x 8 bytes on the server. This leads to additional network transfer savings, speeding up the workflow.
Ease of integration in NADP inference platform
NIO’s current inference platform based on NVIDIA Triton is a key component of their Autonomous Driving Development Platform (NADP), used in their autonomous driving solution.
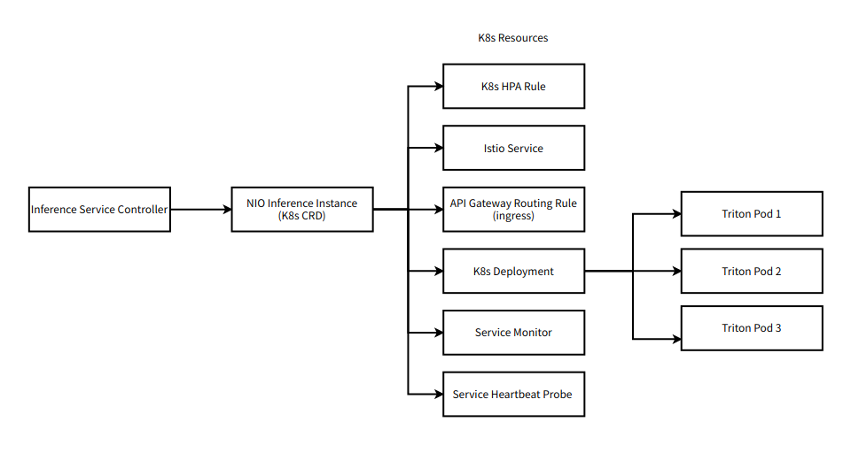
As the NIO platform is built on Kubernetes (K8s), it was imperative for NVIDIA Triton to integrate well with Kubernetes. The components of the workflow are implemented as K8s CRD (native and custom) around NVIDIA Triton.
Continuous Integration/Continuous Delivery (CI/CD)
Argo is the engine used to orchestrate the workflow in Kubernetes. It helps with CI/CD for all the components involved in development, quantification, access, cloud deployment, pressure testing, and launch. NVIDIA Triton helps with CI/CD by triggering the next step in the workflow whenever the models are loaded.
In addition, use of the NVIDIA Triton Docker container helps with consistent functionality across development, test, and deployment environments.
Integrating the Jupyter environment into the NVIDIA Triton image was seamless. Jupyter provides a convenient development environment for debugging in case of a complex problem that requires online debugging or offline reproduction.
Ease of deployment with Istio
NVIDIA Triton natively supports gRPC protocol for communication with applications. However, as the Kubernetes native service cannot offer effective request-level load balancing for gRPC, NVIDIA Triton is integrated with the Istio service mesh. Istio is used to load balance traffic to NVIDIA Triton Inference Server and monitor the health of the service through liveness/readiness probes of NVIDIA Triton.
Ease of use with Apollo configuration management
Apollo Configuration Center is used for model name-based service discovery. Users can access the models without knowing the specific domain name where the model is deployed. Combined with the NVIDIA Triton model repository, users can directly trigger the deployment of models.
Metrics with Prometheus and Grafana
NVIDIA Triton provides a complete set of model service metrics based on model dimensions. For example, NVIDIA Triton can distinguish between inference request queueing time and GPU computation time, enabling fine-grained diagnosis and analysis of online model service performance without entering the debug mode.
Because NVIDIA Triton supports cloud-native mainstream Prometheus/Grafana, users can easily configure the dashboard and the alarms for each dimension to provide metrics support for high service availability.
Key takeaways
NIO’s optimized workflow that integrates NVIDIA Triton Inference Server resulted in a 6x latency reduction in some core pipelines. This improved overall throughput by up to 5x.
By moving the preprocessing logic to GPU using the NVIDIA Triton pipeline orchestration functionality, NIO achieved:
- Faster image processing
- Freed CPU capacity
- Reduced network transfer overhead
- Higher inference throughput
NIO achieved AI inference workflow acceleration using NVIDIA Triton Inference Server. NVIDIA Triton was also easy to integrate in a robust Kubernetes-based scalable solution.
Additional resources
- Get started with NVIDIA Triton and access a variety of beginner to advanced resources.
- Learn about the features needed in an inference platform when building a real-time or continuous data streaming application with Fast and Scalable AI Model Deployment with NVIDIA Triton Inference Server.
- Watch the NVIDIA On-Demand session, From Cloud to Car: How NIO Develops Intelligent Vehicles.
