
Developing effective locomotion policies for quadrupeds poses significant challenges in robotics due to the complex dynamics involved. Training quadrupeds to walk up and down stairs in the real world can damage the equipment and environment. Therefore, simulators play a key role in both safety and time constraints in the learning process.
Leveraging deep reinforcement learning (RL) for training robots in a simulated environment can enable performing complex tasks more effectively and safely. However, this approach introduces a new challenge: how to ensure that this policy trained in simulation transfers seamlessly to the real world. In other words, how can we close the simulation-to-reality (sim-to-real) gap?
Closing the sim-to-real gap requires a high-fidelity, physics-based simulator for training, a high-performance AI computer such as NVIDIA Jetson, and a robot with joint-level controls. The Reinforcement Learning Researcher Kit, developed in collaboration with Boston Dynamics, NVIDIA, and The AI Institute, brings these capabilities together for seamless deployment of quadrupeds from the virtual to the real world. It includes a joint-level control API for the Spot quadruped robot to control how the robot moves, mounting hardware for the NVIDIA Jetson AGX Orin payload to run the policy (AGX Orin sold separately), and a simulation environment for Spot in NVIDIA Isaac Lab.
Isaac Lab is a lightweight reference application built on the NVIDIA Isaac Sim platform specifically optimized for robot learning at scale. It leverages GPU-based parallelization for massively parallel physics-based simulation to improve final policy performance and reduce the training time of RL in robotics. With its high-fidelity physics and domain randomization capabilities, Isaac Lab bridges the sim-to-real gap, enabling seamless deployment of trained models onto physical robots, zero-shot. To learn more, see Supercharge Robotics Workflows with AI and Simulation Using NVIDIA Isaac Sim 4.0 and NVIDIA Isaac Lab.
This post explains how a locomotion RL policy is created for Spot in Isaac Sim and Isaac Lab and deployed on the hardware using the components from the RL Researcher Kit.
Training quadruped locomotion in Isaac Lab
This section describes how to train a locomotion RL policy in Isaac Lab.

Goal
Train the Spot robot to track target x, y, and yaw base velocities while walking on flat terrain.
Observation and action space
The target velocities are randomized at each reset and provided alongside the other observations shown in Figure 1. The action space includes only the 12 DOF joint positions, which are passed to the low-level joint controller as the reference joint positions.
Domain randomization
Various parameters are randomized at key training stages, as shown in Figure 1 under randomization parameters. These randomizations help the model ensure robustness for real-world deployment. This process is called domain randomization.
Network architecture and RL algorithm details
The locomotion policy is structured as a Multilayer Perceptron (MLP) with three layers, containing [512, 256, 128] neurons, and it was trained using the Proximal Policy Optimization (PPO) algorithm from RSL-rl, which is optimized for GPU computation.
Prerequisites
To train the locomotion policies, you will need the following:
- A system equipped with an NVIDIA RTX GPU. For detailed minimum specifications, see the Isaac Sim documentation.
- NVIDIA Isaac Sim, Isaac Lab, and RSL-rl.
Usage
This section shows how to train the policy, replay it, and inspect the results.
Train a policy
cd <path_to_isaac_lab>
./isaaclab.sh -p source/standalone/workflows/rsl_rl/train.py --task Isaac-Velocity-Flat-Spot-v0 --num_envs 4096 --headless --video --enable_cameras
--video --enable_cameras arguments record a video of the agent’s behavior during training; hence, it’s optional.
Play the trained policy
This step will play the trained model and export the .pt policy to .onnx in an exported folder in the log directory.
cd <path_to_isaac_lab>
./isaaclab.sh -p source/standalone/workflows/rsl_rl/play.py --task Isaac-Velocity-Flat-Spot-v0 --num_envs 64
Results
Video 1 demonstrates the trained policy in action on the Spot robot. The robot is able to walk on flat terrain by following the target x, y, and yaw velocities. With 4,096 environments and 15,000 iterations, equivalent to approximately 4 hours of training time on the NVIDIA RTX 4090 GPU, we achieved a training speed of 85,000 to 95,000 frames per second (FPS).
Deploying the trained RL policy on Spot with Jetson Orin
Deploying models trained in simulation to the real world for robotic applications poses several challenges, including real-time control, safety constraints, and other real-world conditions. The accurate physics and domain randomization features of Isaac Lab enable deploying the policy trained in simulation to the real Spot robot on Jetson Orin zero shot, achieving similar performance in both the virtual and real world.
Figure 2 shows the real Spot robot framework policy deployment. The policy neural network is loaded and inferred on the real robot. The same observations as in simulation are computed using the Boston Dynamics State API.
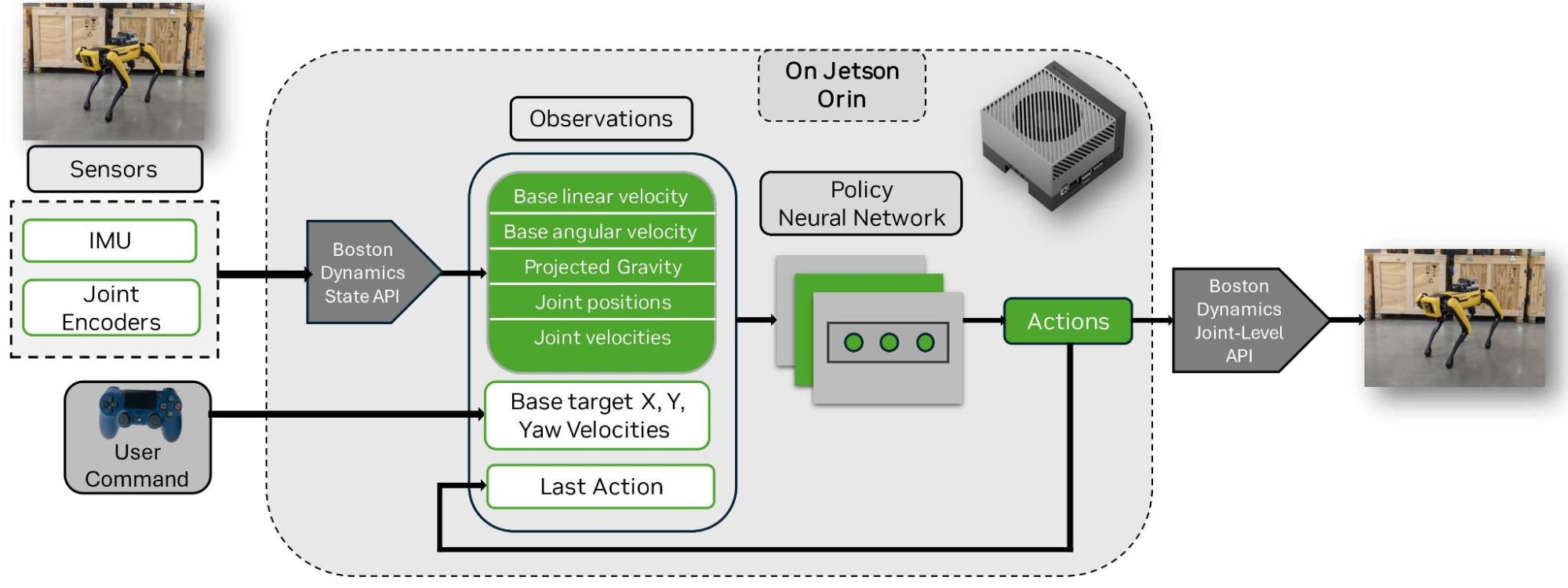
Transferring the trained model to the Spot robot requires deploying the model to the edge and controlling the robot with low latency and high frequency. The NVIDIA Jetson AGX Orin high-performance computing capabilities and low-latency AI processing ensure rapid inference and response times, crucial for real-world robotics applications. Simulated policies can be directly deployed for inference, simplifying the deployment process.
Prerequisites
The following are needed for deployment:
- Spot robot with Jetson Orin attached and configured as a custom payload using the Ethernet port, power cable, and mounting bracket. Follow the setup instructions provided.
- Deployment code and Spot Python SDK from the Spot RL Researcher Kit.
- A PS4 Gamepad controller connected to Jetson Orin through Bluetooth.
- External PC to SSH into Jetson and run the code.
- Trained model and config file from Isaac Lab.
Hardware and network setup on Jetson Orin
- Install SDK Manager on an external PC with Ubuntu 22.04.
- Flash Jetson Orin with JetPack 6 using the SDK Manager by following the instructions on How to use SDK Manager to Flash L4T BSP. Restart when done.
- Connect Jetson Orin to a display port, keyboard, and mouse.
- Log in to Jetson Orin using the username and password set in Step 2.
- For communication between Jetson Orin and Spot, set up the wired network configuration manually for the Ethernet port on Jetson Orin. Read the instructions for choosing an IP address.
- Go to Settings -> Network -> Wired -> + add the information under IPv4 (Routes): Address – Jetson IP Address (we chose 192.168.50.5), Net Mask – 255.255.255.0, and Default Gateway -192.168.50.3
- Click the Add button

Software setup on Jetson
First, convert the simulated trained policy from .pt to .onnx and export the environment config. This is done on the PC for training.
cd <path_to_isaac_lab>
./isaac_lab.sh -p source/standalone/workflows/rsl_rl/play.py --task Isaac-Velocity-Flat-Spot-v0
The result will be in the exported folder in the training log directory for the model. The folder contains the env_cfg.json and .onnx files.
1. On the training PC, create a folder and copy the env.yaml file and .onnx file to the folder. Note: the env.yaml is in the params folder and .onnx file is in the exported folder of the training log directory.
2. On the training PC, copy the folder in Step 1 to Jetson Orin using SSH. Ensure the PC and Jetson are on the same network, like spot local wifi. On the PC’s terminal, run the following command:
scp -P 20022 -r /path/to/folder/* orinusername@network_IP:<path_to_copy_files>
3. Next, run the following command on Orin’s terminal from the home directory:
mkdir spot-rl-deployment && cd spot-rl-deployment && mkdir models
git clone https://github.com/boston-dynamics/spot-rl-example.git
cd spot-rl-example && mkdir external && cd external && mkdir spot_python_sdk
4. Download Spot Python SDK with the joint level API and unzip the content into the spot_python_sdk folder from Step 3.
5. Install the deployment code dependencies:
cd ~/spot-rl-deployment/spot-rl-example
sudo apt update
sudo apt install python3-pip
cd external/spot_python_sdk/prebuilt
pip3 install bosdyn_api-4.0.0-py3-none-any.whl
pip3 install bosdyn_core-4.0.0-py3-none-any.whl
pip3 install bosdyn_client-4.0.0-py3-none-any.whl
pip3 install pygame
pip3 install pyPS4Controller
pip3 install spatialmath-python
pip3 install onnxruntime
6. Convert the env.yaml file to env_cfg.json file:
cd ~/spot-rl-deployment/spot-rl-example/python/utils/
python env_convert.py
#input the path to the .yaml file e.g ~/env.yaml
#The file outputs a env_cfg.json file in the same directory as the .yaml file
7. Move env_cfg.json from Step 6 and the trained model policy.onnx file from Step 2 into the models folder:
mv env_cfg.json policy.onnx ~/spot-rl-deployment/models
Run the policy
1. Power up Spot and press the motor lockout button at the back of the robot. Ensure the Jetson Orin is powered on.

2. Open the Spot app on the Spot tablet controller. Select a robot and follow the prompts to log in and operate Spot. Ensure that you release control from the tablet to run the policy: open the Motor Status menu (power icon), navigate to advanced settings, and select Release Control.
3. Connect the PC to Spot local Wi-Fi and SSH to Orin from the terminal. Spot forwards port 20022 to its payloads so the Orin can be reached by opening an SSH connection to the Spot IP and this port. The IPv4 address, 192.168.50.3, is the Spot IP.
ssh <jetson_username>@<spot_ip> -p 20022
e.g
ssh <jetson_username>@192.168.50.3 -p 20022
4. Connect the wireless gamepad to Orin using bluetoothctl:
bluetoothctl
scan on // wait for devices populate ~5s
scan off
devices
Find the Mac address of the gamepad in the listed devices. Put the gamepad in pairing mode, hold the Select and PlayStation buttons for ~5 seconds, and continue in bluetoothctl. You may need to repeat this process if it exits pairing mode before finishing the next steps.
trust {MAC}
pair {MAC}
connect {MAC}
exit
5. Run RL policy:
cd ~/spot-rl-deployment/spot-rl-example/python
python spot_rl_demo.py <spot_ip> ~/spot-rl-deployment/models --gamepad-config ./gamepad_config.json
Enter Spot’s username and password when prompted. Spot will then stand, but the policy will not take control until you press enter. You can now drive the robot with the Gamepad. Press enter again to cleanly sit Spot down and exit.
6. Control with the PS4 gamepad.

Use the left joystick for x, y movement and the right joystick for rotation, as shown in the Gamepad figure. Note that using another Gamepad (such as the PS5 controller) will require a different axis mapping. The axis_mapping refers to the axis index according to pygame. The script test_controller.py from ~/spot-rl-deployment/spot-rl-example/python/utils/test_controller.py can be used to print the values of each axis to determine the proper mapping for different controllers.
7. Run the policy using the gamepad config option:
python spot_rl_demo.py ~/spot-rl-deployment/models --gamepad-config /home/gamepad_config.json
Video 2 shows the real Spot robot in action after being trained in simulation.
Get started developing your custom application
The codebase provided in the Spot RL Researcher Kit is a starting point for creating your own custom RL tasks in simulation and then deploying them to hardware. To build your custom application, you can modify and extend the current codebase by adding your own robot model, environment, reward functions, curriculum learning, domain randomization, and so on.
For detailed guidance on how to use Isaac Lab to train a policy for your specific task, see the documentation. Deployment of the trained policy on other robots is specific to the robot architecture; however, Spot users can modify the current deployment code if additional observations are needed for their application.
Get your Reinforcement Learning Researcher Kit and Spot robot and start developing your custom application.
Learn more about Isaac Lab, built on Isaac Sim. And check out the following papers for more inspiration and task descriptions:
- Enhancing Efficiency of Quadrupedal Locomotion Over Challenging Terrains with Extensible Feet
- Legs as Manipulator: Pushing Quadrupedal Agility Beyond Locomotion
- Learning Torque Control for Quadrupedal Locomotion
- More Than an Arm: Using a Manipulator as a Tail for Enhanced Stability in Legged Locomotion
Stay up to date on LinkedIn, Instagram, X, and Facebook. Explore the NVIDIA documentation and YouTube channels, and join the NVIDIA Developer Robotics forum. Learn more with self-paced training and webinars on Isaac ROS and Isaac Sim.
Acknowledgments
We would like to acknowledge Farbod Farshidian, Adam Miller, Fangzhou Yu, and Michael Brauckmann from The AI Institute for providing the Isaac Lab-based training environment for Spot and for their support on the deployment of the trained policies.
