
In recent years, model-free deep reinforcement learning algorithms have produced groundbreaking results. However, the current algorithms require a large number of training samples as well as an enormous amount of computing power to achieve the desired results. To help make training more accessible, a team of researchers from NVIDIA developed a GPU-accelerated reinforcement learning simulator that can teach a virtual robot human-like tasks in record time.
With just one NVIDIA Tesla V100 GPU and a CPU core, the team trained the virtual agents to run in less than 20 minutes within the FleX GPU-based physics engine. The work used 10 to 1000x fewer CPU cores than previous works. The simulator can even support hundreds to thousands of virtual robots at the same time on a single GPU.
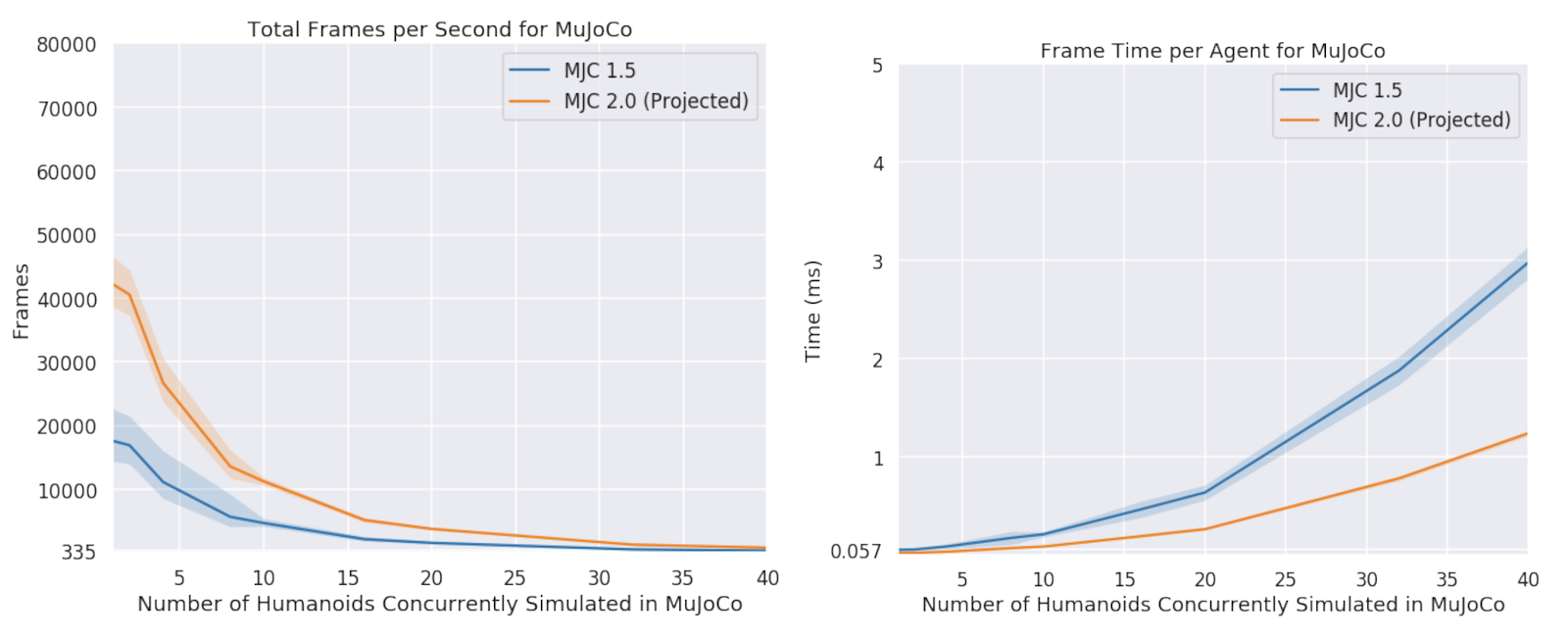
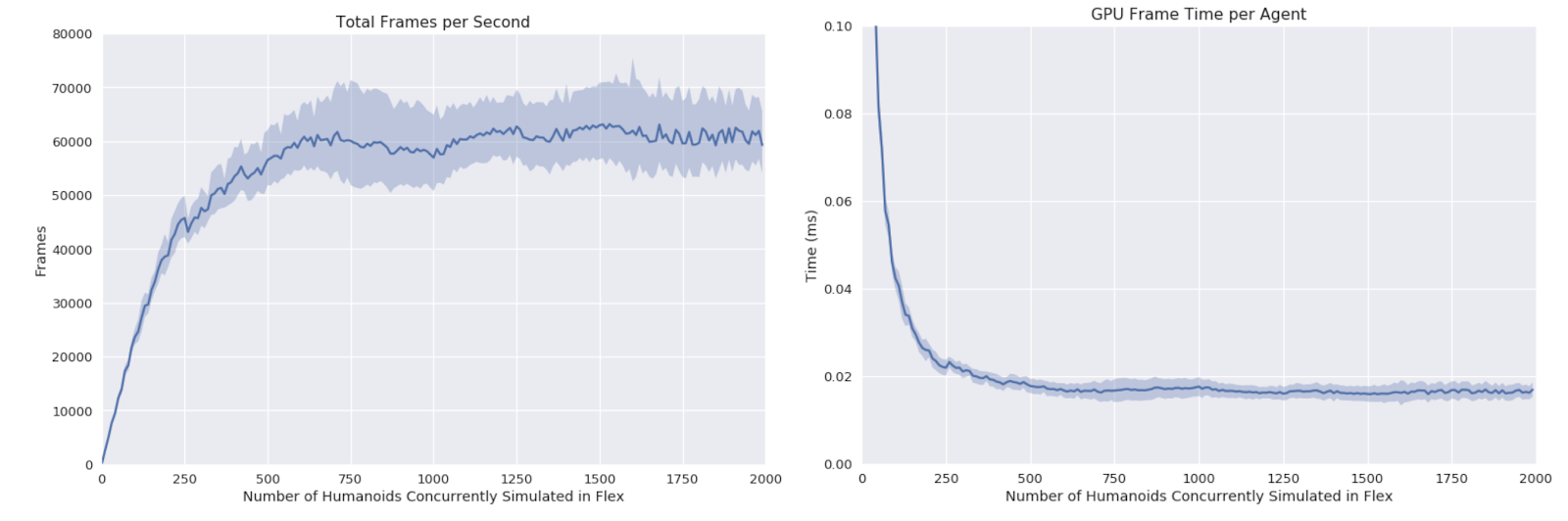
“Unlike simulating individual robots on each CPU cores, we load all simulated agents onto the same scene on one GPU, so they can interact and collide with each other,” the researchers stated. “The peak GPU simulation frame time per agent for the humanoid environment is less than 0.02ms.”
“Using FleX, we implement an OpenAI Gymlike interface to perform RL experiments for continuous control locomotion tasks,” the team stated.
Using the OpenAI Roboschool and the Deepmind Parkour environments the team trained the virtual agents to run toward changing targets, recover from falls, and run on complex and uneven terrains.
Prior works compared to the new NVIDIA work
| Algorithm | CPU Cores | GPUS | Time (mins) |
| Evolution Strategies | 1440 | – | 10 |
| Augmented Random Search | 48 | – | 21 |
| Distributed Prioritized Experience Replay | 32 | 1 | 240 |
| Proximal Policy Optimization w/ GPU Simulation (Ours) | 1 | 1 | 16 |
Resources and Times for Training a Humanoid to Run.
“In contrast to prior works that trained locomotion tasks on CPU clusters, with some using hundreds to thousands of CPU cores, we are able to train a humanoid to run in less than 20 minutes on a single machine with 1 GPU and CPU core, making GPU-accelerated RL simulation a viable alternative to CPU-based ones,” the team explained in their paper.
The work is an ongoing research project at NVIDIA. The paper will be presented at the Conference on Robot Learning in Zurich, Switzerland this week.
The team says they will next train their virtual agents in more complex humanoid environments, allowing the humanoid to actively control the orientation of the rays used to generate the height map. This could lead to the virtual agents navigating obstacles in mid-air.
The team is comprised of researchers Jacky Liang, Viktor Makoviychuk, Ankur Handa, Nuttapong Chentanez, Miles Macklin, and Dieter Fox.
Read more>