
Meetings are the lifeblood of an organization. They foster collaboration and informed decision-making. They eliminate silos through brainstorming and problem-solving. And they further strategic goals and planning.
Yet, leading meetings that accomplish these goals—especially those involving cross-functional teams and external participants—can be challenging. A unique blend of people management skills and adept documentation strategies are required to seamlessly facilitate decision-making and ensure effective post-meeting task execution.
This post introduces the cloud-native microservice-based architecture for intelligent note-taking from adam.ai. Part of the NVIDIA Inception program, adam.ai is a comprehensive meeting management platform designed to empower organizations, teams, and professionals throughout their entire meeting lifecycle. The architecture offers high scalability, low latency, and cost-effective provisioning of automatic note-taking services in online meetings. Specifically, adam.ai leverages:
- Google Cloud Dataflow for automated provisioning of processing resources
- NVIDIA Riva speech-to-text (STT) models for low-latency transcription
- Large language models (LLMs) for efficient summarization
AI-driven automatic note-taking
Manual note-taking requires real-time decisions about what information to record and what to omit. Moreover, balancing active participation with meticulous note-taking presents challenges even for those most adept. The endurance required to focus, especially during lengthy or complex discussions, remains a constant hurdle.
Advancements in automatic speech recognition (ASR) and LLMs pave the way for novel approaches to managing and organizing meeting information. Automatic note-taking harnesses the power of transcription to ensure accuracy and depth in capturing nuances.
Transcription models transform spoken words into accurate text in real time, empowering teams, corporate executives, and professionals to create comprehensive meeting minutes, leaving no critical details overlooked. LLMs leverage a capacity for understanding, reasoning, and knowledge representation to analyze meeting data and extract invaluable insights.
With the user-friendly adam.ai interface, essential agenda items become accessible, and decisions and action items are meticulously tracked (Figure 1). This intuitive approach facilitates meeting management, fosters seamless collaboration, and supports superior meeting outcomes.

Transcription and summarization architecture
The AI Engineering team at adam.ai developed a microservice architecture specifically designed for Google Cloud (Figure 2). This architecture, which includes the note-taking system, can seamlessly translate to other cloud platforms such as AWS and Azure.
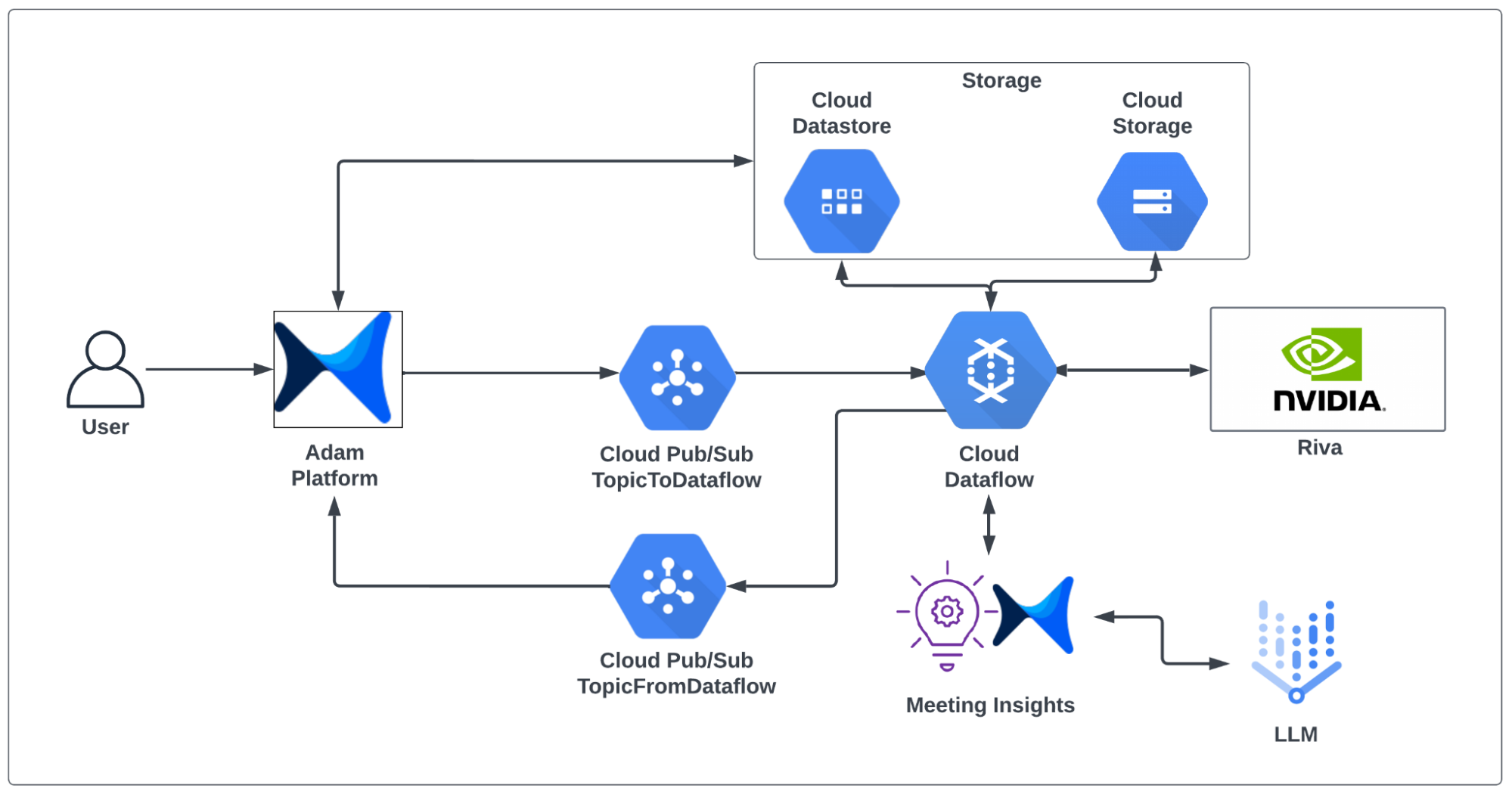
The architecture leverages Google Cloud components, such as Storage, Dataflow, and the Pub/Sub system for storing users’ data, managing data-processing resources, and facilitating communication between the different components.
Meeting transcription is powered by NVIDIA Riva models, offering unmatched accuracy and low latency while efficiently handling real-time audio processing tasks at scale. What sets Riva apart is its full customization capabilities. Riva can be fine-tuned for specialized industries such as legal and medical, providing precise transcription even in niche vocabularies and language usage. Additionally, for variable demand, deploying Riva models using Helm charts enables scalable resource management, providing a cost-effective solution.
Note-taking data flow
The adam.ai note-taking data flow is orchestrated through four key steps:
Step 1: Initiate a note-taking job
When a new meeting recording is uploaded, an event message is generated and transmitted through the Google Cloud Pub/Sub messaging service. This event-driven, distributed mechanism establishes a loosely coupled architecture, simplifying communication between the platform and the note-taking service, especially when processing lengthy meetings that require significant analysis and summarization time.
Step 2: Start the data processing pipeline
Event messages, which encapsulate the location of the audio and video recordings, undergo processing through customized data processing pipelines to derive meeting insights. These pipelines are executed through Google Cloud Dataflow, enabling automated provisioning of computing resources tailored to dynamic user workload, thereby ensuring optimal performance and cost efficiency of processing tasks.
Step 3: Generate meeting transcriptions
The data processing pipeline begins by downloading audio and video recordings from cloud storage. Downloaded files are then meticulously transcribed by NVIDIA Riva. Producing more than a simple conversion of speech to text, Riva enhances transcription quality using contextual understanding. Punctuation and capitalization are refined to provide robust and accurate summarization and insight generation.
Step 4: Generate summary and actionable insights
The meticulously transcribed text is then passed to an LLM to summarize the meeting content. Through refined prompt engineering, the LLM summarizes the meeting and generates valuable, actionable insights. The meeting summary and insights are then returned to the platform for user display.
Benefits of adam.ai architecture
This architecture ensures efficient, scalable, and cost-effective meeting transcription and summarization. Specific benefits include:
Dynamically scalable and fault-tolerant system
Using Google Cloud Pub/Sub, the architecture embraces a loosely coupled, event-driven microservices approach, prompting a scalable, fault-tolerant system. This not only simplifies communication but also provides independent functionality of components. Additionally, Google Cloud Dataflow automatic resource provisioning dynamically scales computing power, resulting in cost-effective data processing.
Real-time accurate meeting transcriptions
The Riva ASR model supports streaming audio and provides real-time accurate transcriptions. Its ability to refine punctuation and capitalization elevates transcript quality, enabling accurate summarization and extraction of valuable insights.
Intelligible and well-structured summarizations
LLM integration provides intelligible and well-structured summaries, fostering the extraction of valuable and actionable insights from the meeting transcript.
Intuitive user experience
The entire process, from transcription to summarization, is seamlessly integrated into the platform. Requests and results flow efficiently through the Pub/Sub system, providing a smooth and intuitive user experience and easy access to meeting insights.
Summary
Transform your meetings into more productive, dynamic collaborations with adam.ai. Working together, ASR and LLMs seamlessly capture every word spoken, extract key insights, and generate detailed notes. This frees participants from the burden of note-taking so they can fully engage in the meeting.
To ensure scalable, low-latency, and cost-effective processing of meetings’ audio data, the adam.ai meeting management platform employs a cloud-native microservice-based architecture. This architecture enables real-time accurate transcriptions and enhanced punctuation and capitalization powered by NVIDIA Riva, providing you with a comprehensive and polished record of your meetings.
To explore how adam.ai can help elevate your meetings, sign up for a free trial. To learn more about LLM enterprise applications, see Getting Started with Large Language Models for Enterprise Solutions. And join the conversation on Speech AI in the NVIDIA Riva forum.
