Automatic speech recognition (ASR) is becoming part of everyday life, from interacting with digital assistants to dictating text messages. ASR research continues to progress, thanks to recent advances:
- ASR model multiple architectures to match needs
- Customization flexibility in industry-specific jargon, languages, accents, and dialects
- Cloud, on-premises, or hybrid deployment options
This post first introduces common ASR applications and then features two startups exploring unique applications of ASR as a core product capability.

How speech recognition systems work
Automatic speech recognition, or speech recognition, is the capability of a computer system to decipher spoken words and phrases from audio and transcribe them into written text. Developers may also refer to ASR as speech-to-text, not to be confused with text-to-speech (TTS).
The text output of an ASR system may be the final product for a speech AI interface, or a conversational AI system may consume the text.
Common ASR applications
ASR has already become the gateway to novel interactive products and services. Even now you may be able to think of brand-name systems with the following use cases.
Live captioning and transcription
Live captioning and transcription are siblings. The main distinction between the two is that captioning produces subtitles live, as needed, for video programs like streaming movies. In contrast, transcription may take place live or in batch mode, where recorded audio cuts are transcribed orders of magnitude faster than in real time.
Virtual assistants and chatbots
Virtual assistants and chatbots interact with people both to help and entertain. They can receive text-based input from users typing or from an ASR system as it recognizes and outputs a user’s words.
Assistants and bots need to issue a response to the user quickly enough so that the processing delay is imperceptible. The response might be plain text, synthesized speech, or images.
Voice commands and dictation
Voice commands and dictation systems are common ASR applications used by social media platforms and in the healthcare industry.
To provide a social media example, before recording a video on a mobile device, a user might speak a voice command to activate beauty filters: “Give me purple hair.” This social networking application involves an ASR-enabled subsystem that receives a user’s words in the form of a command, while the application simultaneously processes camera input and applies filters for screen display.
Dictation systems store text from speech, expanding the vocabulary of the Speech AI system beyond commands. To provide an example from the healthcare industry, a doctor dictates voice notes packed with medical terminology and names. The accurate text output can be added to a visit summary in a patient’s electronic medical record.
Unique ASR applications
Beyond these common use cases, researchers and entrepreneurs are exploring a variety of unique ASR applications. The two startups featured in this post are developing products that use the technology in novel ways.
Interactive learning: Tarteel AI
Creative applications of ASR are beginning to appear in educational materials, especially in the form of interactive learning for both children and adults.
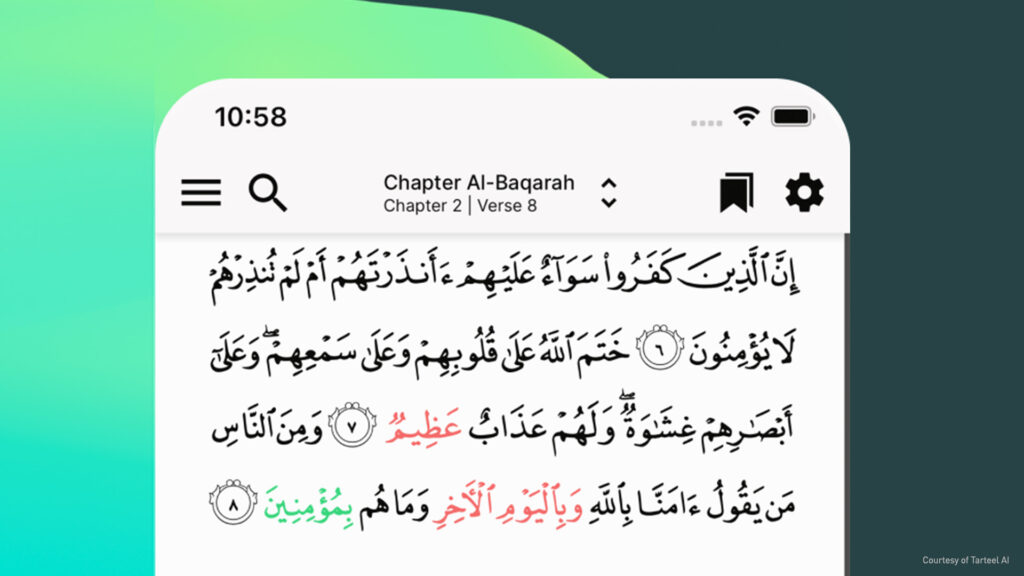
Tarteel.ai is a startup that has developed a mobile app using NVIDIA Riva to aid people in reciting and memorizing the Quran. (‘Tarteel’ is the term used to define the recitation of the Quran in Arabic using melodic, beautiful tones.) The app applies an ASR model fine-tuned by Tarteel to Quranic Arabic. To learn more, watch the demo video in the following social media post.
As the screenshot of the app shows, a user sees the properly recited text, presented from right to left, top to bottom. The script in green is the word just spoken by the user (the leading edge). If a mistake happens in the recitation, the incorrect or missed words are marked in red and a counter keeps track of the inaccuracies for improvement.
The user’s progress is summarized with a list of recitation errors, including links to similar passages that may help the user remember the text. Challenge modes propel the user’s studies forward.
Challenges and solutions
While the app works smoothly now, Tarteel faced a tough set of initial challenges. To start, no suitable ASR model existed for Quranic Arabic, initially forcing Tarteel to try a general-purpose ASR model.
“We started with on-device speech AI frameworks, like for smartphones, but they were designed more for commands and short sentences than precise recitations,” co-founder and CEO of Tarteel Anas Abou Allaban said. “They also weren’t production-level tools—not even close.”
To overcome the challenge, Tarteel built a custom dataset to refine an existing ASR model to meet the app’s performance goals. Then, in their next prototype, the ASR model did perform with a lower word error rate (WER), but it still did not meet the app’s practical accuracy and latency requirements.
Allaban notes that he has seen 10-15% WER for some conference call transcripts, but it is another matter to see a high WER in Quranic studies. A processing latency longer than 300 milliseconds in the app “becomes very annoying,” he said.
Tarteel addressed these challenges by adjusting their ASR model in the NVIDIA NeMo framework and further optimizing its latency with TensorRT before deployment with Riva on Triton Inference Server.
Digital human services: Ex-human
The startup Ex-human is creating hyper-realistic digital humans to interact with analog humans (you and me). Their current focus is developing a B2B digital human service for the entertainment niche, enabling the creation of chatbots or game characters with unique personalities, knowledge, and realistic speaking voices.
In the company’s Botify AI app, the AI entities include famous personalities to engage with users through verbal and graphical interactions, whether you’re typing in a smartphone chat window or using your voice. NVIDIA Riva ASR provides text input to the digital human’s natural language processing subsystems, comprised as part of a large language model (LLM).
Accurate and fast ASR is required to make virtual interactions believable. Because LLMs are compute-intensive and require ample processing resources, they could run too slowly for the interaction.
For example, Botify AI applies state-of-the-art TTS to produce a speech audio response which, in turn, drives facial animation using another AI model. The team has observed that a bot’s believable interactions with users are at their best when the turnaround time for a response is shorter than about a third of a second.
Challenges and solutions
While Botify AI is working to bridge the gap between realistic videos of AI-generated humans and real humans, the Ex-human team was surprised by an analysis of their customers’ behavioral data. “They’re building their own novel anime characters,” said Artem Rodichev, founder and CEO of Ex-human.
Employing ASR models fine-tuned for the Botify AI ecosystem, users may communicate with their favorite personalities or create their own. The surprising pattern of building novel anime characters emerged in the context of uploading custom faces to bring conversation to life with a custom persona. Rodichev explained that his team needed to quickly adapt their AI models to handle, for example, mouths that are stylistically just a dot or a line.
Rodichev and the team overcame many challenges in the architecture of Ex-human through the careful choice of tools and SDKs, as well as evaluating opportunities to parallelize processing. Rodichev cautions, “Because latency is so important, we optimized our ASR model and other models with NVIDIA TensorRT and rely on Triton Inference Server.”
Are Botify AI users ready to engage with digital humans more than with analog humans? Data reveals that users spend an average of 40 minutes a day with Botify AI digital humans, texting their favorites hundreds of messages during that time.
Get started with ASR
You can start including ASR capabilities in your own designs and projects, from hands-free voice commands to real-time transcription. Advanced SDKs such as Riva see high performance in world-class accuracy, speed, latency, and ease of integration—all aligned to enable your new idea.
Try NVIDIA Riva ASR on your web browser or download the Riva Skills Quick Start Guide.
Related resources
The best way to gain expertise in speech AI is to experience it. For more information about how to build and deploy real-time speech AI pipelines for your conversational AI application, see the free Building Speech AI Applications ebook (registration required).
Explore the differences between speech AI and conversational AI with A Guide to Understanding Essential Speech AI Terms.