
OpenAI researchers recently released a paper describing the development of GPT-3, a state-of-the-art language model made up of 175 billion parameters.
For comparison, the previous version, GPT-2, was made up of 1.5 billion parameters. The largest Transformer-based language model was released by Microsoft earlier this month and is made up of 17 billion parameters.
“GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic,” the researchers stated in their paper. “We find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans.”
Natural language processing tasks range from generating news articles, to language translation, to answering standardized test questions.
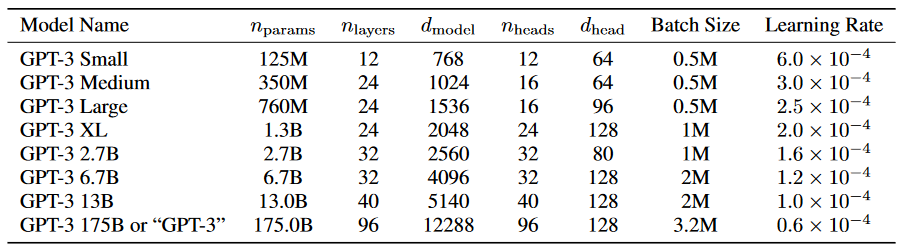
“The precise architectural parameters for each model are chosen based on computational efficiency and load-balancing in the layout of models across GPU’s,” the organization stated. “All models were trained on NVIDIA V100 GPUs on part of a high-bandwidth cluster provided by Microsoft.”
OpenAI trains all of their AI models on the cuDNN-accelerated PyTorch deep learning framework.
Earlier this month Microsoft and OpenAI announced a new GPU-accelerated supercomputer built exclusively for the organization.
“The supercomputer developed for OpenAI is a single system with more than 285,000 CPU cores, 10,000 GPUs and 400 gigabits per second of network connectivity for each GPU server,” the companies stated in a blog.
In terms of performance, the new GPT-3 model achieves near state-of-the-art results on the SuperGLUE benchmark, introduced last year to test reasoning and other advanced NLP tasks. In other benchmarks, including COPA and ReCoRD, the model falls short with word-in-context analysis (WIC) and RACE, a set of middle and high school exam questions.
“Despite many limitations and weaknesses, these results suggest that very large language models may be an important ingredient in the development of adaptable, general language systems,” the organization said.
